大数据环境搭建(在虚拟机上)
一、安装VMare
二、安装Centos7
三、配置linux
1、配置网络
ip addr #查看本机ip
vi /etc/sysconfig/network-scripts/ifcfg-ens33
BOOTPROTO=static #修改
ONBOOT=yes #修改
IPADDR=192.168.52.100
NETMASK=255.255.255.0
GATEWAY=192.168.52.2 #结尾必须.2 .1默认被占用了
DNS1=8.8.8.8
// 保存并退出
service network restart #重启网络服务
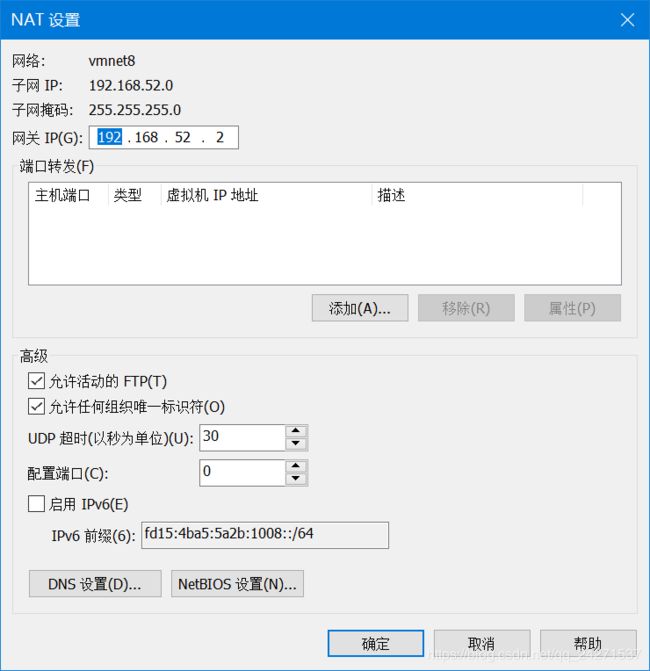
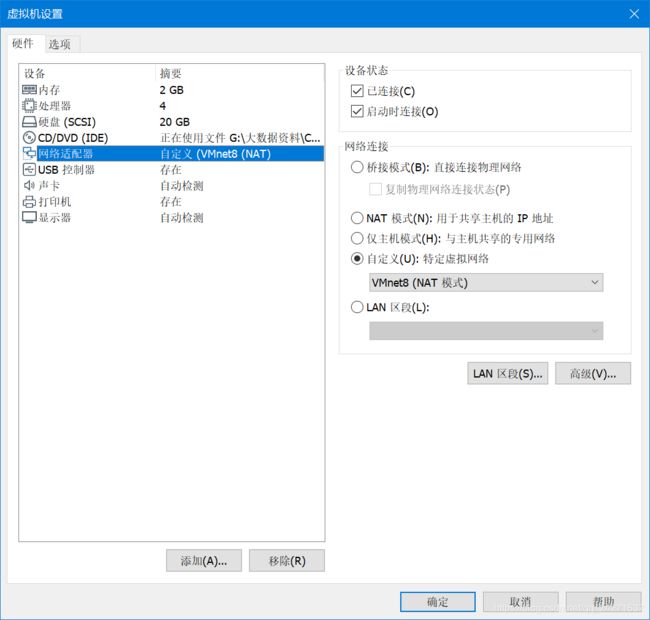
2、编辑VMare虚拟网络编辑器
(编辑 -- 虚拟网络编辑器)

3、测试
ping www.baidu.com #测试网络
// 如果不通
service network restart
hostnamectl set-hostname node00 #设置hostname
logout #登出
如果发生 there are job stoped 错误:
jobs 查看正在执行的任务
fg %1 重新执行 (1是jobs命令中的任务编号)
kill %1 杀死任务。
yum install -y vim #安装vim
4、关闭防火墙
systemctl stop firewalld #关闭防火墙
systemctl disable firewalld #防火墙不在启动
systemctl status firewalld #查看防火墙状态
// 显示下列信息即为关闭
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled; vendor preset: enabled)
Active: inactive (dead)
Docs: man:firewalld(1)
yum install -y vim #安装vim
vim /etc/selinux/config #进入selinux设置文件
SELINUX=disabled
5、建立映射节点
vim /etc/hosts #进入配置文件
192.168.52.100 node01
192.168.52.110 node02
192.168.52.120 node03
6、添加普通用户并授权
useradd hadoop #添加hadoop用户
passwd hadoop #给hadoop用户添加密码
hadoop #密码设为hadoopvisudo #进入用户权限配置文件
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
hadoop ALL=(ALL) ALL # 给hadoop用户添加所有权限
7、上传并解压Hadoop、JDK安装文件
#切换到hadoop用户,注意“-”左右有空格
#(从此步骤开始,最好切换到hadoop用户操作)
su - hadoop
cd / # 先进入根目录
mkdir -p /kkb/soft # 软件压缩包存放目录
mkdir -p /kkb/install # 软件解压后存放目录
chown -R hadoop:hadoop /kkb # root用户将文件夹权限更改为hadoop用户// 将jdk8-linux压缩包,zookeeper压缩包,hadoop压缩包,通过xftp传送到/kkb/soft/目录
cd /kkb/soft
# 解压jdk到/kkb/install文件夹
tar -zxvf jdk-8u141-linux-x64.tar.gz -C /kkb/install/
# 解压hadoop到/kkb/install文件夹
tar -zxvf hadoop-2.6.0-cdh5.14.2_after_compile.tar.gz -C /kkb/install/
8、免密登陆设置
# hadoop用户下执行下列命令,必须!
# 下面操作node01,node02,node03 都执行,回车next。
ssh-keygen -t rsa #生成公钥 (一直回车)
ssh-copy-id node01 #三台机器的公钥全部拷贝到node01
// 此时node01的 /home/hadoop/.ssh 文件夹中包含了3台机器的公钥#下面是在node01 hadoop用户下执行
cd /home/hadoop/.ssh/
scp authorized_keys node02:$PWD #将node01的授权文件拷贝到node02
scp authorized_keys node03:$PWD #将node01的授权文件拷贝到node03
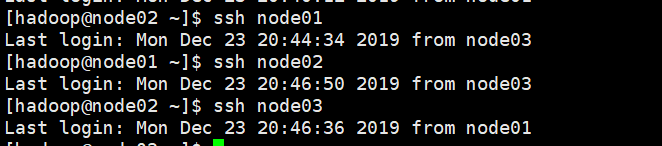
# “:PWD”的意思是:拷贝目标文件位置和node01的位置一致。#验证免密登录
#在node01执行
ssh node02 #在node01登录node02,不需要密码就ok
ssh node03 #在node01登录node02,不需要密码就ok
#回到node01
logout#修改.ssh目录权限
[hadoop@node01 ~]$ chmod -R 755 .ssh/
[hadoop@node01 ~]$ cd .ssh/
[hadoop@node01 .ssh]$ chmod 644 *
[hadoop@node01 .ssh]$ chmod 600 id_rsa
[hadoop@node01 .ssh]$ chmod 600 id_rsa.pub
#把hadoop的公钥添加到本机认证文件当中,如果没有添加启动集群时需要输入密码才能启动,这里需要重点注意下
[hadoop@node01 .ssh]$ cat id_rsa.pub >> authorized_keys
[hadoop@node01 .ssh]$测试:
8、配置JDK , Hadoop环境变量(3台都要配)
rpm -e --nodeps #删除原生jdk
vim /etc/profile # 配置全局全局环境变量,下拉到文件最下方
export JAVA_HOME=/kkb/install/jdk1.8.0_141 #添加
export HADOOP_HOME=/kkb/install/hadoop-2.6.0-cdh5.14.2 #添加
export PATH=$PATH:$HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin #添加source /etc/profile # 环境变量立即生效
java -version #验证java
hadoop version #验证hadoop测试:


9、配置Hadoop(3台都要配)
注意:要在root用户下,否则无法修改,保存时提示readonly --- su - root
#配置hadoop-env.sh
su - hadoop
cd /kkb/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop
vim hadoop-env.sh
export JAVA_HOME=/kkb/install/jdk1.8.0_141 #修改为此变量chown -R hadoop:hadoop /kkb #如果从第六步一直用hadoop用户操作,那么没必要执行此命令
#配置core-site.xml
#在hadoop用户下打开配置文件:
vim /kkb/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop/core-site.xml
#复制以下内容到配置文件中
fs.defaultFS
hdfs://node01:8020
hadoop.tmp.dir
/kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/tempDatas
io.file.buffer.size
4096
fs.trash.interval
10080
检查点被删除后的分钟数。 如果为零,垃圾桶功能将被禁用。
该选项可以在服务器和客户端上配置。 如果垃圾箱被禁用服务器端,则检查客户端配置。
如果在服务器端启用垃圾箱,则会使用服务器上配置的值,并忽略客户端配置值。
fs.trash.checkpoint.interval
0
垃圾检查点之间的分钟数。 应该小于或等于fs.trash.interval。
如果为零,则将该值设置为fs.trash.interval的值。 每次检查指针运行时,
它都会从当前创建一个新的检查点,并删除比fs.trash.interval更早创建的检查点。
#配置hdfs-site.xml
#在hadoop用户下打开配置文件:
vim /kkb/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop/hdfs-site.xml
#复制以下文件到配置文件中
dfs.namenode.secondary.http-address
node01:50090
dfs.namenode.http-address
node01:50070
dfs.namenode.name.dir
file:///kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/namenodeDatas
dfs.datanode.data.dir
file:///kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/datanodeDatas
dfs.namenode.edits.dir
file:///kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/dfs/nn/edits
dfs.namenode.checkpoint.dir
file:///kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/dfs/snn/name
dfs.namenode.checkpoint.edits.dir
file:///kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/dfs/nn/snn/edits
dfs.replication
3
dfs.permissions
false
dfs.blocksize
134217728
#配置mapred-site.xml
#在hadoop用户下操作
#进入指定文件夹:cd /kkb/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop/
#由于原来没有mapred-site.xml配置文件,需要根据模板复制一份:
cp mapred-site.xml.template mapred-site.xml
vim /kkb/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop/mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.job.ubertask.enable
true
mapreduce.jobhistory.address
node01:10020
mapreduce.jobhistory.webapp.address
node01:19888
#配置yarn-site.xml
#在hadoop用户下操作
vim /kkb/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop/yarn-site.xml
yarn.resourcemanager.hostname
node01
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.log-aggregation-enable
true
yarn.log.server.url
http://node01:19888/jobhistory/logs
yarn.log-aggregation.retain-seconds
2592000
yarn.nodemanager.log.retain-seconds
604800
yarn.nodemanager.log-aggregation.compression-type
gz
yarn.nodemanager.local-dirs
/kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/yarn/local
yarn.resourcemanager.max-completed-applications
1000
编辑slaves (3个节点都要设置)
此文件用于配置集群有多少个数据节点,我们把node2,node3作为数据节点,node1作为集群管理节点
#在hadoop用户下操作
vim /kkb/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop/slavesnode01 #添加
node02 #添加
node03 #添加
修改hadoop安装目录的权限 (3个节点都要设置)
#1.修改目录所属用户和组为hadoop:hadoop
[root@node01 ~]# chown -R hadoop:hadoop /kkb
[root@node01 ~]##2.修改目录所属用户和组的权限值为755
[root@node01 ~]# chmod -R 755 /kkb
[root@node01 ~]# chmod -R g+w /kkb
[root@node01 ~]# chmod -R o+w /kkb
[root@node01 ~]#
#创建文件存放目录
#在hadoop用户下操作
mkdir -p /kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/tempDatas
mkdir -p /kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/namenodeDatas
mkdir -p /kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/datanodeDatas
mkdir -p /kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/dfs/nn/edits
mkdir -p /kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/dfs/snn/name
mkdir -p /kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/dfs/nn/snn/edits
12、格式化hadoop(只在node01设置)
[root@node01 ~]# su - hadoop
[hadoop@node01 hadoop]$ hdfs namenode -format
[hadoop@node01 ~]$ hdfs namenode -format
19/08/23 04:32:34 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: user = hadoop
STARTUP_MSG: host = node01.kaikeba.com/192.168.52.100
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.6.0-cdh5.14.2
STARTUP_MSG: classpath = /kkb/install/hadoop-2.6.0-19/08/23 04:32:35 INFO common.Storage: Storage directory /kkb/install/hadoop-2.6.0-
#显示格式化成功。。。
cdh5.14.2/hadoopDatas/namenodeDatas has been successfully formatted.
19/08/23 04:32:35 INFO common.Storage: Storage directory /kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/dfs/nn/edits has been successfully formatted.
19/08/23 04:32:35 INFO namenode.FSImageFormatProtobuf: Saving image file /kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/namenodeDatas/current/fsimage.ckpt_0000000000000000000 using no compression
19/08/23 04:32:35 INFO namenode.FSImageFormatProtobuf: Image file /kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/namenodeDatas/current/fsimage.ckpt_0000000000000000000 of size 323 bytes saved in 0 seconds.
19/08/23 04:32:35 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
19/08/23 04:32:35 INFO util.ExitUtil: Exiting with status 0
19/08/23 04:32:35 INFO namenode.NameNode: SHUTDOWN_MSG:
#此处省略部分日志
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at node01.kaikeba.com/192.168.52.100
************************************************************/
[hadoop@node01 ~]$
13、启动集群
[hadoop@node01 ~]$ start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
19/08/23 05:18:09 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting namenodes on [node01]
node01: starting namenode, logging to /kkb/install/hadoop-2.6.0-cdh5.14.2/logs/hadoop-hadoop-namenode-node01.kaikeba.com.out
node01: starting datanode, logging to /kkb/install/hadoop-2.6.0-cdh5.14.2/logs/hadoop-hadoop-datanode-node01.kaikeba.com.out
node03: starting datanode, logging to /kkb/install/hadoop-2.6.0-cdh5.14.2/logs/hadoop-hadoop-datanode-node03.kaikeba.com.out
node02: starting datanode, logging to /kkb/install/hadoop-2.6.0-cdh5.14.2/logs/hadoop-hadoop-datanode-node02.kaikeba.com.out
Starting secondary namenodes [node01]
node01: starting secondarynamenode, logging to /kkb/install/hadoop-2.6.0-cdh5.14.2/logs/hadoop-hadoop-secondarynamenode-node01.kaikeba.com.out
19/08/23 05:18:24 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
starting yarn daemons
starting resourcemanager, logging to /kkb/install/hadoop-2.6.0-cdh5.14.2/logs/yarn-hadoop-resourcemanager-node01.kaikeba.com.out
node03: starting nodemanager, logging to /kkb/install/hadoop-2.6.0-cdh5.14.2/logs/yarn-hadoop-nodemanager-node03.kaikeba.com.out
node02: starting nodemanager, logging to /kkb/install/hadoop-2.6.0-cdh5.14.2/logs/yarn-hadoop-nodemanager-node02.kaikeba.com.out
node01: starting nodemanager, logging to /kkb/install/hadoop-2.6.0-cdh5.14.2/logs/yarn-hadoop-nodemanager-node01.kaikeba.com.out
[hadoop@node01 ~]$测试:
在浏览器地址栏中输入http://192.168.52.100:50070/dfshealth.html#tab-overview查看namenode的web界面.

14、运行mapreduce程序
mapreduce程序(行话程为词频统计程序(中文名),英文名:wordcount),就是统计一个文件中每一个单词出现的次数 ;
我们接下来要运行的程序(wordcount)是一个分布式运行的程序,是在一个大数据集群中运行的程序。wordcount程序能够正常的运行成功,输入结果,意味着我们的大数据环境正确的安装和配置成功
#1.使用hdfs dfs -ls / 命令浏览hdfs文件系统,集群刚开始搭建好,由于没有任何目录所以什么都不显示.
[hadoop@node01 ~]$ hdfs dfs -ls /
#2.创建测试目录
[hadoop@node01 ~]$ hdfs dfs -mkdir /test
#3.在此使用hdfs dfs -ls 发现我们刚才创建的test目录
[hadoop@node01 ~]$ hdfs dfs -ls /test
19/08/23 05:22:25 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 2 items
drwxr-xr-x - hadoop supergroup 0 2019-08-23 05:21 /test/
[hadoop@node01 ~]$
#4.使用touch命令在linux本地目录创建一个words文件
[hadoop@node01 ~]$ touch words
#5.文件中输入如下内容
[hadoop@node01 ~]$ vi words
i love you
are you ok#6.将创建的本地words文件上传到hdfs的test目录下
[hadoop@node01 ~]$ hdfs dfs -put words /test
#7.查看上传的文件是否成功
[hadoop@node01 ~]$ hdfs dfs -ls -r /test
Found 1 items
-rw-r--r-- 3 hadoop supergroup 23 2019-06-30 17:28 /test/words
#/test/words 是hdfs上的文件存储路径 /test/output是mapreduce程序的输出路径,这个输出路径是不能已经存在的路径,mapreduce程序运行的过程中会自动创建输出路径,数据路径存在的话会报错,这里需要同学注意下.
[hadoop@node01 ~]$ hadoop jar /kkb/install/hadoop-2.6.0-cdh5.14.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.14.2.jar wordcount /test/words /test/output
19/08/23 05:21:22 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
19/08/23 05:21:23 INFO client.RMProxy: Connecting to ResourceManager at node01/192.168.52.100:8032
19/08/23 05:21:23 INFO input.FileInputFormat: Total input paths to process : 1
19/08/23 05:21:23 INFO mapreduce.JobSubmitter: number of splits:1
19/08/23 05:21:24 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1566551905266_0001
19/08/23 05:21:24 INFO impl.YarnClientImpl: Submitted application application_1566551905266_0001
19/08/23 05:21:24 INFO mapreduce.Job: The url to track the job: http://node01:8088/proxy/application_1566551905266_0001/
19/08/23 05:21:24 INFO mapreduce.Job: Running job: job_1566551905266_0001
19/08/23 05:21:31 INFO mapreduce.Job: Job job_1566551905266_0001 running in uber mode : true
19/08/23 05:21:31 INFO mapreduce.Job: map 100% reduce 0%
19/08/23 05:21:33 INFO mapreduce.Job: map 100% reduce 100%
19/08/23 05:21:33 INFO mapreduce.Job: Job job_1566551905266_0001 completed successfully
19/08/23 05:21:33 INFO mapreduce.Job: Counters: 52
File System Counters
FILE: Number of bytes read=140
FILE: Number of bytes written=226
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=374
HDFS: Number of bytes written=309275
HDFS: Number of read operations=41
HDFS: Number of large read operations=0
HDFS: Number of write operations=18
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Other local map tasks=1
Total time spent by all maps in occupied slots (ms)=0
Total time spent by all reduces in occupied slots (ms)=0
TOTAL_LAUNCHED_UBERTASKS=2
NUM_UBER_SUBMAPS=1
NUM_UBER_SUBREDUCES=1
Total time spent by all map tasks (ms)=677
Total time spent by all reduce tasks (ms)=1357
Total vcore-milliseconds taken by all map tasks=0
Total vcore-milliseconds taken by all reduce tasks=0
Total megabyte-milliseconds taken by all map tasks=0
Total megabyte-milliseconds taken by all reduce tasks=0
Map-Reduce Framework
Map input records=2
Map output records=6
Map output bytes=46
Map output materialized bytes=54
Input split bytes=94
Combine input records=6
Combine output records=5
Reduce input groups=5
Reduce shuffle bytes=54
Reduce input records=5
Reduce output records=5
Spilled Records=10
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=0
CPU time spent (ms)=2210
Physical memory (bytes) snapshot=774352896
Virtual memory (bytes) snapshot=6196695040
Total committed heap usage (bytes)=549453824
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=23
File Output Format Counters
Bytes Written=28
[hadoop@node01 ~]$
测试结果:
[hadoop@node01 ~]$ hdfs dfs -text /test/output/part-r-00000
19/12/23 22:02:32 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
666 1
tangpeng 1
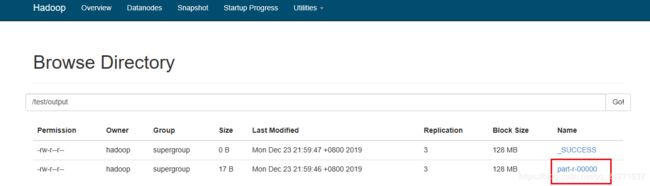
[hadoop@node01 ~]$ hdfs dfs -ls /test/output
19/12/23 22:05:15 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 2 items
-rw-r--r-- 3 hadoop supergroup 0 2019-12-23 21:59 /test/output/_SUCCESS
-rw-r--r-- 3 hadoop supergroup 17 2019-12-23 21:59 /test/output/part-r-00000
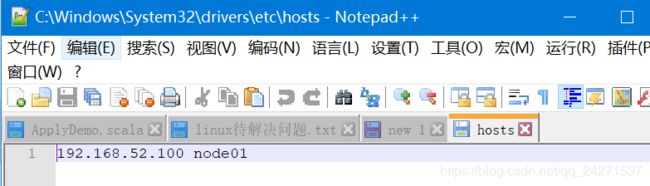
如果想在浏览器查看或者下载,需要在host文件中配置映射
然后就可以查看了

15、停止集群
[hadoop@node1 ~]$ stop-all.sh