AdaBoost基本原理与算法描述
一. 前言
最近在看集成学习方法,前面已经对XGBoost的原理与简单实践做了介绍,这次对AdaBoost算法做个学习笔记,来巩固自己所学的知识,同时也希望对需要帮助的人有所帮助。
关于集成学习主要有两大分支,一种是bagging方法,一种是boosting方法。
bagging方法的弱学习器之间没有依赖关系,各个学习器可以并行生成,最终通过某种策略进行集成得到强学习器(比如回归问题用所有弱学习器输出值的平均值作为预测值;分类问题使用投票法,即少数服从多数的方法来得到最终的预测值;也可以使用学习法,即每个弱学习器的输出值作为训练数据来重新学习一个学习器,而该学习器的输出值作为最终的预测值,代表方法有stacking方法,感兴趣的同学可以自己去了解一下)。bagging方法采用自助采样法,即在总样本中随机的选取m个样本点作为样本m1,然后放回,继续随机选取m个样本点作为样本m2,如此循环下去直到选取的样本个数达到预设定值n,对这n个样本进行学习,生成n个弱学习器。随机森林算法就是bagging方法的代表算法。
boosting方法的若学习器之间有强的依赖关系,各个弱学习器之间串行生成。它的工作机制是初始给每个样本赋予一个权重值(初始权重值一般是1/m,m表示有m个样本),然后训练第一个弱学习器,根据该弱学习器的学习误差率来更新权重值,使得该学习器中的误差率高的训练样本点(所有的训练样本点)的权重值变高,权重值高的训练样本点在后面的弱学习器中会得到更多的重视,以此方法来依次学习各个弱学习器,直到弱学习器的数量达到预先指定的值为止,最后通过某种策略将这些弱学习器进行整合,得到最终的强学习器。boosting方法的代表算法有AdaBoost和boosting tree算法,而AdaBoost算法就是本文接下来要介绍的算法。
在介绍AdaBoost之前,要先搞清楚boosting系列算法主要解决的一些问题,如下:
- 弱学习器的权重系数
 如何计算?
如何计算? - 样本点的权重系数
 如何更新?
如何更新? - 学习的误差率
 如何计算?
如何计算? - 最后使用的结合策略是什么?
下面我们就来看看AdaBoost是如何解决以上问题的。
二. AdaBoost基本原理介绍
2.1 AdaBoost分类问题
以二分类为例,假设给定一个二类分类的训练数据集![]() ,其中
,其中 表示样本点,
表示样本点, 表示样本对应的类别,其可取值为{-1,1}。AdaBoost算法利用如下的算法,从训练数据中串行的学习一系列的弱学习器,并将这些弱学习器线性组合为一个强学习器。AdaBoost算法描述如下:
表示样本对应的类别,其可取值为{-1,1}。AdaBoost算法利用如下的算法,从训练数据中串行的学习一系列的弱学习器,并将这些弱学习器线性组合为一个强学习器。AdaBoost算法描述如下:
输入:训练数据集![]()
输出:最终的强分类器G(x)
(1) 初始化训练数据的权重分布值:(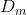 表示第m个弱学习器的样本点的权值)
表示第m个弱学习器的样本点的权值)
![]()
![]()

(2) 对M个弱学习器,m=1,2,...,M:
(a)使用具有权值分布![]() 的训练数据集进行学习,得到基本分类器
的训练数据集进行学习,得到基本分类器 ![]() ,其输出值为{-1,1};
,其输出值为{-1,1};
(b)计算弱分类器![]() 在训练数据集上的分类误差率
在训练数据集上的分类误差率![]() ,其值越小的基分类器在最终分类器中的作用越大。
,其值越小的基分类器在最终分类器中的作用越大。
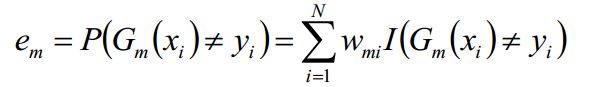
其中,![]() 取值为0或1,取0表示分类正确,取1表示分类错误。
取值为0或1,取0表示分类正确,取1表示分类错误。
(c)计算弱分类器![]() 的权重系数
的权重系数![]() :(这里的对数是自然对数)
:(这里的对数是自然对数)
![]()
一般情况下![]() 的取值应该小于0.5,因为若不进行学习随机分类的话,由于是二分类错误率等于0.5,当进行学习的时候,错误率应该略低于0.5。当
的取值应该小于0.5,因为若不进行学习随机分类的话,由于是二分类错误率等于0.5,当进行学习的时候,错误率应该略低于0.5。当![]() 减小的时候
减小的时候![]() 的值增大,而我们希望得到的是分类误差率越小的弱分类器的权值越大,对最终的预测产生的影响也就越大,所以将弱分类器的权值设为该方程式从直观上来说是合理地,具体的证明
的值增大,而我们希望得到的是分类误差率越小的弱分类器的权值越大,对最终的预测产生的影响也就越大,所以将弱分类器的权值设为该方程式从直观上来说是合理地,具体的证明![]() 为上式请继续往下读。
为上式请继续往下读。
(d)更新训练数据集的样本权值分布:
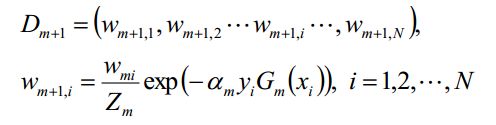
对于二分类,弱分类器![]() 的输出值取值为{-1,1},
的输出值取值为{-1,1},![]() 的取值为{-1,1},所以对于正确的分类
的取值为{-1,1},所以对于正确的分类 ![]() ,对于错误的分类
,对于错误的分类![]() ,由于样本权重值在[0,1]之间,当分类正确时
,由于样本权重值在[0,1]之间,当分类正确时![]() 取值较小,而分类错误时
取值较小,而分类错误时![]() 取值较大,而我们希望得到的是权重值高的训练样本点在后面的弱学习器中会得到更多的重视,所以该上式从直观上感觉也是合理地,具体怎样合理,请往下读。
取值较大,而我们希望得到的是权重值高的训练样本点在后面的弱学习器中会得到更多的重视,所以该上式从直观上感觉也是合理地,具体怎样合理,请往下读。
其中,![]() 是规范化因子,主要作用是将
是规范化因子,主要作用是将![]() 的值规范到0-1之间,使得
的值规范到0-1之间,使得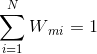 。
。
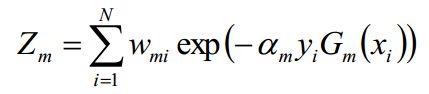
(3) 上面我们介绍了弱学习器的权重系数α如何计算,样本的权重系数W如何更新,学习的误差率e如何计算,接下来是最后一个问题,各个弱学习器采用何种结合策略了,AdaBoost对于分类问题的结合策略是加权平均法。如下,利用加权平均法构建基本分类器的线性组合:
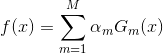
得到最终的分类器:
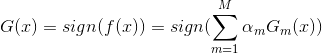
以上就是对于AdaBoost分类问题的介绍,接下来是对AdaBoost的回归问题的介绍。
2.2 AdaBoost回归问题
AdaBoost回归问题有许多变种,这里我们以AdaBoost R2算法为准。
(1)我们先看看回归问题的误差率问题,对于第m个弱学习器,计算他在训练集上的最大误差:
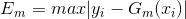
然后计算每个样本的相对误差:(计算相对误差的目的是将误差规范化到[0,1]之间)
![]() , 显然
, 显然 ![]()
这里是误差损失为线性时的情况,如果我们用平方误差,则![]() ,如果我们用指数误差,则
,如果我们用指数误差,则![]()
最终得到第k个弱学习器的误差率为:
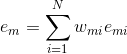 ,表示每个样本点的加权误差的总和即为该弱学习器的误差。
,表示每个样本点的加权误差的总和即为该弱学习器的误差。
(2)我们再来看看弱学习器的权重系数α,如下公式:
![]()
(3)对于如何更新回归问题的样本权重,第k+1个弱学习器的样本权重系数为:
![]()
其中![]() 是规范化因子:
是规范化因子: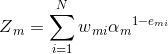
(4)最后是结合策略,和分类问题不同,回归问题的结合策略采用的是对加权弱学习器取中位数的方法,最终的强回归器为:
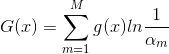 ,其中
,其中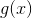 是所有
是所有![]() 的中位数(m=1,2,...,M)。
的中位数(m=1,2,...,M)。
这就是AdaBoost回归问题的算法介绍,还有一个问题没有解决,就是在分类问题中我们的弱学习器的权重系数![]() 是如何通过计算严格的推导出来的。
是如何通过计算严格的推导出来的。
2.3 AdaBoost前向分步算法
在上两节中,我们介绍了AdaBoost的分类与回归问题,但是在分类问题中还有一个没有解决的就是弱学习器的权重系数![]() 是如何通过公式推导出来的。这里主要用到的就是前向分步算法,接下来我们就介绍该算法。
是如何通过公式推导出来的。这里主要用到的就是前向分步算法,接下来我们就介绍该算法。
从另一个角度讲,AdaBoost算法是模型为加法模型,损失函数为指数函数,学习算法为前向分步算法时的分类问题。其中,加法模型表示我们的最终得到的强分类器是若干个弱分类器加权平均得到的,如下:
损失函数是指数函数,如下:
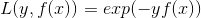
学习算法为前向分步算法,下面就来介绍AdaBoost是如何利用前向分布算法进行学习的:
(1)假设进过m-1轮迭代前向分布算法已经得到![]() :
:
![]()
![]()
在第m轮的迭代得到![]() ,
,![]() 和
和![]() .
.
![]()
目标是使前向分布算法得到的![]() 和
和![]() 使
使![]() 在训练数据集T上的指数损失最小,即
在训练数据集T上的指数损失最小,即
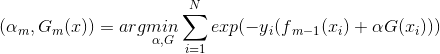
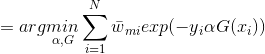
![]()
上式即为我们利用前向分步学习算法得到的损失函数。其中,![]() 。因为
。因为![]() 既不依赖也不依赖于G,所以在第m轮迭代中与最小化无关。但
既不依赖也不依赖于G,所以在第m轮迭代中与最小化无关。但![]() 依赖于
依赖于![]() ,随着每一轮的迭代而发生变化。
,随着每一轮的迭代而发生变化。
上式达到最小时所取的![]() 和
和![]() 就是AdaBoost算法所得到的
就是AdaBoost算法所得到的![]() 和
和![]() 。
。
(2)首先求分类器![]() :
:
我们知道,对于二分类的分类器G(x)的输出值为-1和1,![]() 表示预测错误,
表示预测错误,![]() 表示正确,每个样本点都有一个权重值,所以对于一个弱分类器的输出则为:
表示正确,每个样本点都有一个权重值,所以对于一个弱分类器的输出则为: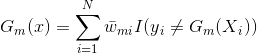 ,我们的目标是使损失最小化,所以我们的具有损失最小化的第m个弱分类器即为:
,我们的目标是使损失最小化,所以我们的具有损失最小化的第m个弱分类器即为:
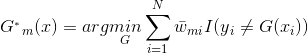 其中,
其中,![]()
为什么用![]() 表示一个弱分类器的输出呢?因为我们的AdaBoost并没有限制弱学习器的种类,所以它的实际表达式要根据使用的弱学习器类型来定。
表示一个弱分类器的输出呢?因为我们的AdaBoost并没有限制弱学习器的种类,所以它的实际表达式要根据使用的弱学习器类型来定。
此分类器即为Adaboost算法的基本分类器![]() ,因为它是使第m轮加权训练数据分类误差率最小的基本分类器。
,因为它是使第m轮加权训练数据分类误差率最小的基本分类器。
(3)然后就是来求![]() ,
,
将![]() 代入损失函数(1)式中,得:
代入损失函数(1)式中,得:
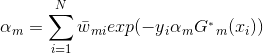
我们的目标是最小化上式,求出对应的![]() 。
。
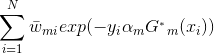
![]()
![]()
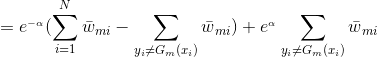
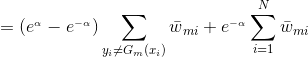
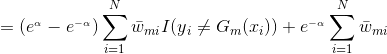
![]()
由于,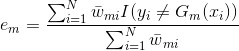
注意:这里我们的样本点权重系数![]() 并没有进行规范化,所以
并没有进行规范化,所以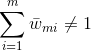
(2)式为: 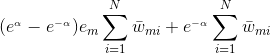
则我们的目标是求:
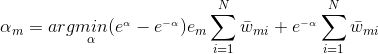
上式求偏导,并令偏导等于0,得:
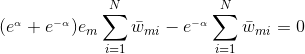 ,进而得到:
,进而得到:
![]() ,求得:
,求得:![]() ,其中
,其中![]() 为误差率:
为误差率:
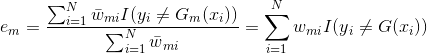
(4)最后看样本权重的更新。
利用前面所讲的![]() ,以及权值
,以及权值 ![]()
可以得到如下式子:
![]()
这样就得到了我们前面所讲的样本权重更新公式。
2.4 AdoBoost算法的正则化
为了防止过拟合,AdaBoost算法中也会加入正则化项,这个正则化项我们称之为步长也就是学习率。定义为v,对于前面的弱学习器的迭代有:
![]()
加入正则化项,就变成如下:
![]()
v的取值范围为(0,1]。对于同样的训练集学习效果,较小的v意味着我们需要更多的弱学习器的迭代次数。通常我们用学习率和迭代最大次数一起来决定算法的拟合效果。
到这里,我们的AdaBoost算法介绍完毕。
三. AdaBoost算法流程描述
3.1 AdaBoost分类问题的算法流程描述
关于AdaBoost的分类问题,sklearn中采用的是SAMME和SAMME.R算法,SAMME.R算法是SAMME算法的变种。sklearn中默认采用SAMME.R,原因是SAMME.R算法比SAMME算法收敛速度更快,用更少的提升迭代次数实现了更低的测试误差。接下来我们先介绍AdaBoost的分类算法流程,可以将二元分类算法视为多元分类算法的一个特例。
3.1.1 SAMME算法流程描述:
输入:样本集![]() ,输出为
,输出为![]() ,弱分类器的迭代次数为M,样本点的个数为N。
,弱分类器的迭代次数为M,样本点的个数为N。
输出:最终的强分类器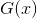
(1)初始化样本点的权重为:
![]()
![]()
(2)对于m=1,2,..,M
(a)使用带有权重的样本来训练一个弱学习器![]() ;
;
(b)计算弱分类器![]() 的分类误差率:
的分类误差率:
(c)计算弱分类器的系数:
![]() ,
,
其中,K表示K元分类,可以看出当K=2时,![]() ,余下的
,余下的![]() 与我们二元分类算法所描述的弱分类器系数一致。
与我们二元分类算法所描述的弱分类器系数一致。
(d)更新样本的权重分布:
(3)构建最终的强分类器:
3.1.2 SAMME.R算法流程描述:
输入:样本集![]() ,输出为
,输出为![]() ,弱分类器的迭代次数为M,样本点的个数为N。
,弱分类器的迭代次数为M,样本点的个数为N。
输出:最终的强分类器
(1)初始化样本点的权重为:
![]()
![]()
(2)对于m=1,2,..,M
(a)使用带有权重的样本来训练一个弱学习器![]() ;
;
(b)获得带有权重分类的概率评估:
![]() ,
,
其中![]() 表示第m个弱学习器将样本
表示第m个弱学习器将样本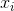 分为第k类的概率。k=1,2,...,K,K表示分类的类别个数。
分为第k类的概率。k=1,2,...,K,K表示分类的类别个数。
(c) 使用加权概率推导出加法模型的更新,然后将其应用于数据:
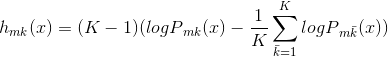 ,
,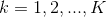
(d)更新样本点权重系数:
![]()
(e)标准化样本点权重;
(3)构建最终的强分类器:
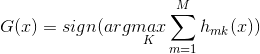 ,表示使
,表示使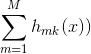 最大的类别即为我们所预测的类别。
最大的类别即为我们所预测的类别。
3.2 AdaBoost回归问题的算法流程描述
在sklearn中,回归使用的算法为 AdaBoost.R2算法,具体的流程描述如下:
输入:样本集![]() ,输出为
,输出为![]() ,弱分类器的迭代次数为M,样本点的个数为N。
,弱分类器的迭代次数为M,样本点的个数为N。
输出:最终的强分类器
(1)初始化样本点的权重为:
![]()
![]()
(2)对于m=1,2,..,M
(a)使用具有权重![]() 的样本集来训练数据,得到弱学习器
的样本集来训练数据,得到弱学习器![]()
(b)计算训练集上的最大误差
![]() ,
,
(c)计算每个样本点的相对误差:
如果是线性误差:则![]()
如果是平方误差,则![]()
如果是指数误差,则![]()
(d)计算回归误差率:
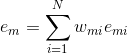
(c)计算弱学习器的系数:
![]()
(d)更新样本集的权重分布:
![]() ,其中
,其中![]() 是规范化因子,
是规范化因子,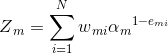
(3)构建最终的强学习器:
,其中是所有![]() 的中位数(m=1,2,...,M)。
的中位数(m=1,2,...,M)。
四. AdaBoost算法的优缺点
4.1 优点
(1)不容易发生过拟合;
(2)由于AdaBoost并没有限制弱学习器的种类,所以可以使用不同的学习算法来构建弱分类器;
(3)AdaBoost具有很高的精度;
(4)相对于bagging算法和Random Forest算法,AdaBoost充分考虑的每个分类器的权重;
(5)AdaBoost的参数少,实际应用中不需要调节太多的参数。
4.2 缺点
(1)AdaBoost迭代次数也就是弱分类器数目不太好设定,可以使用交叉验证来进行确定。
(2)数据不平衡导致分类精度下降。
(3)训练比较耗时,每次重新选择当前分类器最好切分点。
(4)对异常样本敏感,异常样本在迭代中可能会获得较高的权重,影响最终的强学习器的预测准确性。
五. 参考文献/博文
(1)李航,《统计学习方法》 第八章
(2)Multi-class AdaBoost 论文
(3)Boosting for Regression Transfer AdaBoost回归论文
(4)https://www.cnblogs.com/pinard/p/6133937.html