数据合并和重塑(全)
01.通过concat函数设定的key参数提取数据?
转载:https://www.zhihu.com/question/67816246
import pandas as pd import numpy as np train = pd.DataFrame(np.arange(9).reshape(3,3),columns=["a","b","c"]) test = pd.DataFrame(np.arange(9,18).reshape(3,3),columns=["a","b","c"]) result = pd.concat([train,test],ignore_index=True) print(result)
输出:
a b c
0 0 1 2
1 3 4 5
2 6 7 8
3 9 10 11
4 12 13 14
5 15 16 17
result = pd.concat([train,test],ignore_index=False) print(result)
输出:
a b c
0 0 1 2
1 3 4 5
2 6 7 8
0 9 10 11
1 12 13 14
2 15 16 17
result = pd.concat([train,test],ignore_index=True,keys=["train","test"]) print(result)
输出:
a b c
0 0 1 2
1 3 4 5
2 6 7 8
0 9 10 11
1 12 13 14
2 15 16 17
result = pd.concat([train,test],ignore_index=False,keys=["train","test"]) print(result)
输出:
a b c
train 0 0 1 2
1 3 4 5
2 6 7 8
test 0 9 10 11
1 12 13 14
2 15 16 17
#提取数据用loc print(result.loc["train"])
输出:
a b c
0 0 1 2
1 3 4 5
2 6 7 8
02.Pandas_数据合并concat
转载:https://blog.csdn.net/sinat_33761963/article/details/53893903
#coding = utf-8 import numpy as np import pandas as pd #numpy的concat arr1 = np.random.randint(0,10,(3,4)) print(arr1)
输出:
[[8 9 0 2]
[3 2 2 5]
[9 5 1 6]]
arr2 = np.random.randint(0,10,(3,4)) print(arr2)
输出:
[[0 4 3 0]
[4 4 8 8]
[4 6 4 7]]
print([arr1,arr2])
输出:
[array([[8, 9, 0, 2],
[3, 2, 2, 5],
[9, 5, 1, 6]]), array([[0, 4, 3, 0],
[4, 4, 8, 8],
[4, 6, 4, 7]])]
#调用.concatenate,并将两个ndarray组成list传入,默认是纵向合并 print(np.concatenate([arr1,arr2]))
输出:
[[8 9 0 2]
[3 2 2 5]
[9 5 1 6]
[0 4 3 0]
[4 4 8 8]
[4 6 4 7]]
#指定轴方向,axis=1时是横向合并 print(np.concatenate([arr1,arr2],axis=1))
输出:
[[8 9 0 2 0 4 3 0]
[3 2 2 5 4 4 8 8]
[9 5 1 6 4 6 4 7]]
#Series上的concat #index没有重复的情况 ser_obj1 = pd.Series(np.random.randint(0,10,5),index=range(0,5)) print(ser_obj1)
输出:
0 8
1 8
2 4
3 5
4 5
dtype: int32
ser_obj2 = pd.Series(np.random.randint(0,10,4),index=range(5,9)) print(ser_obj2)
输出:
5 9
6 8
7 2
8 2
dtype: int32
ser_obj3 = pd.Series(np.random.randint(0,10,3),index=range(9,12)) print(ser_obj3)
输出:
9 6
10 1
11 5
dtype: int32
#设置横向合并 print(pd.concat([ser_obj1,ser_obj2,ser_obj3],axis=1))
输出:
0 1 2
0 8.0 NaN NaN
1 8.0 NaN NaN
2 4.0 NaN NaN
3 5.0 NaN NaN
4 5.0 NaN NaN
5 NaN 9.0 NaN
6 NaN 8.0 NaN
7 NaN 2.0 NaN
8 NaN 2.0 NaN
9 NaN NaN 6.0
10 NaN NaN 1.0
11 NaN NaN 5.0
#合并后索引保持不变 print(pd.concat([ser_obj1,ser_obj2,ser_obj3]))
输出:
0 8
1 8
2 4
3 5
4 5
5 9
6 8
7 2
8 2
9 6
10 1
11 5
dtype: int32
#相当于多个Series的链接 print(pd.concat([ser_obj1,ser_obj2,ser_obj3],axis=1,join='inner'))
输出:
Empty DataFrame
Columns: [0, 1, 2]
Index: []
df_obj1 = pd.DataFrame(np.random.randint(0,10,(3,2)),index=["a","b","c"],
columns=["A","B"])
print(df_obj1)
输出:
A B
a 9 5
b 6 1
c 9 1
df_obj2 = pd.DataFrame(np.random.randint(0,10,(2,2)),index=["a","b"],
columns=["C","D"])
print(df_obj2)
输出:
C D
a 1 8
b 9 0
f = pd.concat([df_obj1,df_obj2]) print(f)
输出:
A B C D
a 9.0 5.0 NaN NaN
b 6.0 1.0 NaN NaN
c 9.0 1.0 NaN NaN
a NaN NaN 1.0 8.0
b NaN NaN 9.0 0.0
g = pd.concat([df_obj1,df_obj2],axis=1) print(g)
输出:
A B C D
a 9 5 1.0 8.0
b 6 1 9.0 0.0
c 9 1 NaN NaN
03.python合并相关函数
转载:https://www.jianshu.com/p/baaf8c89c9e2
#建立数据集
import pandas as pd
import numpy as np
df1 = pd.DataFrame({'key':['a','b','c','d','e'],"data1":np.arange(5)})
print(df1)
输出:
key data1
0 a 0
1 b 1
2 c 2
3 d 3
4 e 4
df2 = pd.DataFrame({"key":['a','b','c'],'data2':np.arange(3)})
print(df2)
输出:
key data2
0 a 0
1 b 1
2 c 2
#merge函数 data = pd.merge(df1, df2, on='key') print(data)
输出:
key data1 data2
0 a 0 0
1 b 1 1
2 c 2 2
data = pd.merge(df1,df2,how="left") print(data)
输出:
key data1 data2
0 a 0 0.0
1 b 1 1.0
2 c 2 2.0
3 d 3 NaN
4 e 4 NaN
data = pd.merge(df1, df2, on='key',how="left") print(data)
输出:
key data1 data2
0 a 0 0.0
1 b 1 1.0
2 c 2 2.0
3 d 3 NaN
4 e 4 NaN
#通过indicator表明merge的方式(这个功能日常工作中我比较少用 data=pd.merge(df1,df2,on='key',how='left',indicator=True) print(data)
输出:
key data1 data2 _merge
0 a 0 0.0 both
1 b 1 1.0 both
2 c 2 2.0 both
3 d 3 NaN left_only
4 e 4 NaN left_only
#当两个数据集合并的列名不相同时用 left_on,right_on
df1=df1.rename(columns={'key':'key1'})
data=pd.merge(df1,df2,left_on='key1',right_on='key',how='left')
print(data)
输出:
key1 data1 key data2
0 a 0 a 0.0
1 b 1 b 1.0
2 c 2 c 2.0
3 d 3 NaN NaN
4 e 4 NaN NaN
data数据集将两个列名不相同的数据合并在一起了!
注:merge函数默认连接方式是inner,另外有left,right,outer等
#针对合并后的数据再合并,不是一次性合并几个数据集
df1=pd.DataFrame({'key':['a','b','c','d','e'],'data1':np.arange(5)})
df2=pd.DataFrame({'key':['a','b','c'],'data2':np.arange(3)})
df3=pd.DataFrame({'key':['a','b','c','d'],'data3':np.arange(4)})
data=pd.merge(pd.merge(df1,df2,on='key',how='left'),df3,on='key',how='left')
print(data)
输出:
key data1 data2 data3
0 a 0 0.0 0.0
1 b 1 1.0 1.0
2 c 2 2.0 2.0
3 d 3 NaN 3.0
4 e 4 NaN NaN
#多条件合并
df1=pd.DataFrame({'key':['a','b','c','d','e'],'key1':
['one','one','two','one','two'],'data1':np.arange(5)})
df2=pd.DataFrame({'key':['a','b','c'],'key1':
['one','one','two'],'data2':np.arange(3)})
data=pd.merge(df1,df2,on=['key','key1'],how='left')
print(data)
输出:
key key1 data1 data2
0 a one 0 0.0
1 b one 1 1.0
2 c two 2 2.0
3 d one 3 NaN
4 e two 4 NaN
#Concat(类似numpy的concatenate) #合并两个数据集,可在行或者列上合并(axis) # data=pd.concat([df1,df2]) data1=pd.concat([df1,df2],axis=1) # print(data1)
输出:
key data1 key data2
0 a 0 a 0.0
1 b 1 b 1.0
2 c 2 c 2.0
3 d 3 NaN NaN
4 e 4 NaN NaN
#ignore_index 不保留原来连接轴上的索引,生成一组新索引 data = pd.concat([df1, df2], ignore_index=True) print(data)
输出:
data1 data2 key
0 0.0 NaN a
1 1.0 NaN b
2 2.0 NaN c
3 3.0 NaN d
4 4.0 NaN e
5 NaN 0.0 a
6 NaN 1.0 b
7 NaN 2.0 c
#纵向合并(axis=1是列) data1=pd.concat([df1,df2],axis=1) print(data1)
输出:
key data1 key data2
0 a 0 a 0.0
1 b 1 b 1.0
2 c 2 c 2.0
3 d 3 NaN NaN
4 e 4 NaN NaN
# 多个数据集合并时 data1=pd.concat([df1,df2,....]) # keys 可以判断数据来自哪个数据集,生成一个多重索引。 data = pd.concat([df1, df2], keys=[0, 1]) print(data)
输出:
data1 data2 key
0 0 0.0 NaN a
1 1.0 NaN b
2 2.0 NaN c
3 3.0 NaN d
4 4.0 NaN e
1 0 NaN 0.0 a
1 NaN 1.0 b
2 NaN 2.0 c
# Join索引上的合并,是增加列而不是增加行 df3=pd.DataFrame([[1,2],[3,4],[5,6]],index=['a','b','c'],columns=['ao','bo']) df4=pd.DataFrame([[7,8],[9,10],[10,12]],index=['e','b','c'],columns=['aoe','boe']) print(df3.join(df4,how='outer'))
输出:
ao bo aoe boe
a 1.0 2.0 NaN NaN
b 3.0 4.0 9.0 10.0
c 5.0 6.0 10.0 12.0
e NaN NaN 7.0 8.0
#当合并的数据表列名字相同,通过lsuffix='', rsuffix='' 区分相同列名的列 df5=pd.DataFrame([[7,8],[9,10],[10,12]],index=['e','b','c'],columns=['aoe','boe']) df6=pd.DataFrame([[7,8],[9,10],[10,12]],index=['e','b','c'],columns=['aoe','boe']) print(df5.join(df6,how='outer',lsuffix='_l', rsuffix='_r'))
输出:
aoe_l boe_l aoe_r boe_r
e 7 8 7 8
b 9 10 9 10
c 10 12 10 12
# Combine_first # 若df7的数据缺失,则用df8的数据值填充df1的数据值 df7 = pd.DataFrame([[np.nan, 3., 5.], [-4.6, np.nan, np.nan],[np.nan, 7., np.nan]]) df8 = pd.DataFrame([[-42.6, np.nan, -8.2], [-5., 1.6, 4]], index=[1, 2]) print(df7.combine_first(df8))
输出:
0 1 2
0 NaN 3.0 5.0
1 -4.6 NaN -8.2
2 -5.0 7.0 4.0
04.python 数据表格的合并和重塑--pd.concat
转载:https://blog.csdn.net/norsaa/article/details/77692944
concat函数是在pandas底下的方法,可以将数据根据不同的轴作简单的融合
pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False)
参数说明
objs: series,dataframe或者是panel构成的序列lsit
axis: 需要合并链接的轴,0是行,1是列
join:连接的方式 inner,或者outer
其他一些参数不常用,用的时候再补上说明。
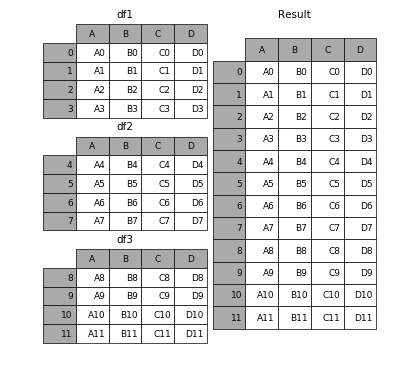
1.1 相同字段的表首尾相接
-
# 现将表构成list,然后在作为concat的输入
-
In [4]: frames = [df1, df2, df3]
-
In [5]: result = pd.concat(frames)
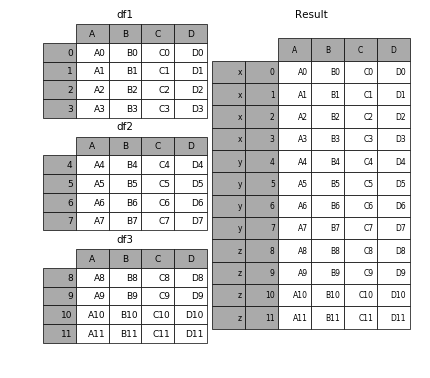
要在相接的时候在加上一个层次的key来识别数据源自于哪张表,可以增加key参数
In [6]: result = pd.concat(frames, keys=['x', 'y', 'z'])
输出:
1.2 横向表拼接(行对齐)
1.2.1 axis
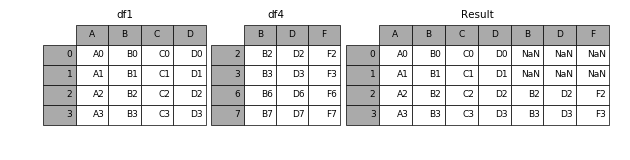
当axis = 1的时候,concat就是行对齐,然后将不同列名称的两张表合并
In [9]: result = pd.concat([df1, df4], axis=1)

1.2.2 join
加上join参数的属性,如果为’inner’得到的是两表的交集,如果是outer,得到的是两表的并集。
In [10]: result = pd.concat([df1, df4], axis=1, join='inner')

1.2.3 join_axes
如果有join_axes的参数传入,可以指定根据那个轴来对齐数据
例如根据df1表对齐数据,就会保留指定的df1表的轴,然后将df4的表与之拼接
result = pd.concat([df1, df4], axis=1, join_axes=[df1.index])
1.3 append
result = df1.append(df2)
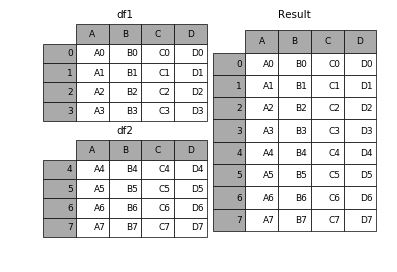
1.4 无视index的concat
如果两个表的index都没有实际含义,使用ignore_index参数,置true,合并的两个表就睡根据列字段对齐,然后合并。最后再重新整理一个新的index。

1.5 合并的同时增加区分数据组的键
前面提到的keys参数可以用来给合并后的表增加key来区分不同的表数据来源
1.5.1 可以直接用key参数实现
result = pd.concat(frames, keys=['x', 'y', 'z'])

1.5.2 传入字典来增加分组键
pieces = {'x': df1, 'y': df2, 'z': df3}
result = pd.concat(pieces)
1.6 在dataframe中加入新的行
append方法可以将 series 和 字典就够的数据作为dataframe的新一行插入
In [34]: s2 = pd.Series(['X0', 'X1', 'X2', 'X3'], index=['A', 'B', 'C', 'D'])
In [35]: result = df1.append(s2, ignore_index=True)
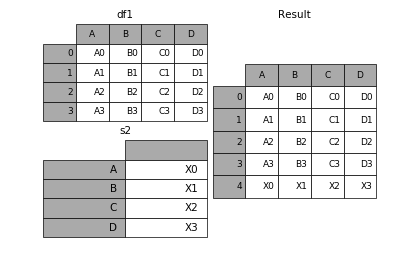
表格列字段不同的表合并
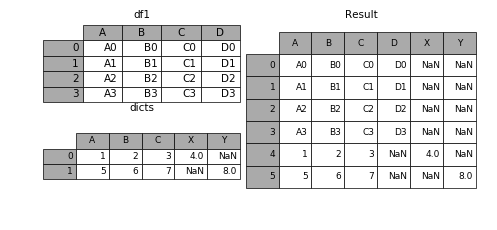
如果遇到两张表的列字段本来就不一样,但又想将两个表合并,其中无效的值用nan来表示。那么可以使用ignore_index来实现
dicts = [{'A': 1, 'B': 2, 'C': 3, 'X': 4}, {'A': 5, 'B': 6, 'C': 7, 'Y': 8}]
result = df1.append(dicts, ignore_index=True)