编程珠玑-学习心得-算法设计技术
第九章-代码调优
1、顺序搜索
提高效率的高层次方法:问题定义、系统结构、算法设计、数据结构选择
低层次方法:代码调优-首先确定程序中开销较大的部分。
C中取模运算大约需要100ns,其他算数运算10ns
k=(j+rotdist)%n;修改为
k=j+rotdist;
if(k>n)
{ k-=n;}问题3:顺序搜素
int ssearch(t)
{
for i= [0,n)
if x[i]==t;
return i;
return -1;
}平均花费4.06ns 查找x中元素,平均花在查找一个元素的时间是8.1ns;
内循环两种测试:一种测试i检验i是否到达数组末尾,第二种测试检验x[i]是否为所需的元素,只要在该数组末尾防止一个哨兵值,就可以把第一种测试替换为第二种测试;
int ssearch2(t)
hold = x[n]
x[n]=t;
for(i=0;;i++)
if x[i]==t;
break;
x[n]=hold;
if i == n;
return -1;
else
return i;该算法将时间降低至3.87ns,上述代码已经为该数组分配了内存,因此x[n]可以被临时覆盖,改代码保存了x[n]并且在搜索后进行了恢复,在大多数场合是不需要的。
最终的顺序搜索程序将循环展开8次来删除自增,进一步展开不会取得更好的效果:
int ssearch3(t)
x[n]=t;
for(i = 0; ; i+=8)
if(x[i ] == t) { break;}
if(x[i+1] == t) {i+=1; break;}
if(x[i+2] == t) {i+=2; break;}
if(x[i+3] == t) {i+=3; break;}
if(x[i+4] == t) {i+=4; break;}
if(x[i+5] == t) {i+=5; break;}
if(x[i+6] == t) {i+=6; break;}
if(x[i+7] == t) {i+=7; break;}
if i==n;
return -1;
else
return n;运行时间降低至1.7ns
2、二分搜索
优化折中


原理
1、效率的角色
2、度量工具
3、设计层面
第10章 节省空间
10.3数据空间技术
不存储、重新计算(适用于只需要存储对象,并且可以根据其对象重新计算)
稀疏数据结构()
数据压缩()
分配策略(空间使用方式比使用量更重要)
动态分配(需要时才分配空间)
垃圾回收(对废弃的空间进行回收)
旅行商问题,共享磁盘的方法
函数定义()
解释程序()
翻译成机器语言()
10.4原理
空间开销
空间的热点
空间度量
折中
与环境协作(编译器、系统运行函数表达方式、内存分配策略、分页策略)
使用适合任务的正确工具
应用
11 排序
11.1插入排序
for i=[1,n)
for(j=i;j>0&&x[j-1]>x[j];j--)
{
swap(j-1,j)
}快速排序:
void qsort3(l,u){
if l>u;
return;
t = x[l];i=l;j=u+l;
loop
do i++ while i,=u&&x[i]t;
if(i>j)
break;
swap(i,j);
swap(l,j)
qsort3(l,j-1)
qsort(j+1,u)
} 改进的快速排序
void qsort4(l,u){
if u-lt;
if(i>j)
break;
swap(i,j);
swap(l,j)
qsort4(l,j-1)
qsort4(j+1,u)
} 12章、取样问题
12.3设计空间
打破空间壁垒
用set表示集合
void gensets(int m,int n){
set S;
while(S.size()::iterator i;
for(i=S.begin();i!=S.end();i++)
cout<< *i<<"\n";
} 该算法空间占用较大,时间O(mlogm,当m相对于n较小时),解决这个问题需要打乱前m个元素
void genshuf(int m,int n)
{
int i,j;
int *x = new int[n];
for(i=0;i
算法需要n个元素的空间、以及O(n+mlogm)的时间
12.4原理
正确理解遇到的问题(讨论问题产生的背景)
提炼出抽象问题(简介、明确的问题陈述不仅可以帮助我们解决当前遇到的问题,还有助于把解决方案应用到其他问题)
考虑尽可能多的解法(伪代码表示控制流、抽象数据类型表示关键的数据结构)
实现一种解决方案(应用代码实现解决方案的最优的一种)
回顾(改进的余地是总有的)
第13章 搜索
13.1接口
class IntSetTmp{
public :
IntSetTmp(int maxelements, int maxval);
void insert(int t);
int size();
void report(int *v);
};
void gensets(int m,int maxval){
int *v = new int[m];
IntSetImp S(m,maxval);
while (S.size()
insert函数不会在集合中放入重复元素,因此不需要在插入前测试元素是否在集合中。
class IntSetSTL{
private:
set S;
public:
intSetSTL(int maxelements,int maxval){ }
int size() {return S.size();}
void insert(int t) {S.insert(t);}
void report(int *v){
int j=0;
ser::iteratior i;
for(i = S.begin(); i!=S.end();++i)
v[j++]=*i;
}
}
13.2线性结构
void inset( t)
{ for (i =0;x[i]=i;j--)
x[j+l] = x[j];
x[i] = t;
n++;
}
private:
int n;
struct node{
int val;
node *next;
node( int v,node *p){val=v;next=p;}
}
链表中的每个节点都具有一个整数值和一个指向链表下一节点的指针,node函数将两个参数的值赋给这两个字段;
IntSetList(maxelements,maxval){
sentinel = head = new node(maxval,0)
n=0;
}
void report(int *v){
j=o;
for( p =head;p!=sential;p=p->next )
v[j++] = p->val
}
report函数遍历链表,将排序好的元素写入输出向量
递归函数,插入有序链表:
void insert(t)
head = rinsert(head,t)
递归部分非常清晰:
node *rinsert(p,t)
if p->valnext,t)
else if p->val >t
p= new node(t,p)
n++;
return p;
13.3二分搜索树
private:
int n, *v,vn;
struct node{
int val;
node *left,*right;
node(int i) {val =i;left = right=0;};
node *root;
}
//初始化该树的时候将根设为空,并通过调用递归函数执行其他操作:
IntSetBST(int maxelement,int maxval) {root = 0; n= 0;}
void insert(int t) {root = rinsert(root,t);}
void report (int *x) { v=x; vn=0;traverse(root);}
插入函数遍历这棵树,直到该值(搜索终止)或在整棵树中都没有找到该值(插入该结点)
node *rinsert(p,t)
if p == 0
p = new node(t)
n++;
else if(tval)
p->left = rinsert(p->left,t)
else if(t>p->val == t)
p->right = rinsert(p->right,t)
//do nothing if p->val == t
return p
中序遍历 先处理左子树,接着输出节点本身,最后处理右子树
void traverse(p)
if( p==0)
return ;
traverse(p->left)
v[vn++] = p-val;
traverse(p->right)
利用变量vn来索引向量V中下一个可用元素
13.4用于整数的结构
enum { BITSPERWORD = 32, SHIFT = 5, MASK = 0x1F};
int n,hi,*x;
void set(int i) { x[i>>SHIFT] != (i<<(i&MASK));}
void clr(int i){ x[i>>SHIFT] &= -(l<<(i&MASK));}
int test(int i){ return x[i>>SHIFT] & (l<<(i&MASK))}
void report(v)
j=0;
for i=[0,bins)
for(node *p = bin[i];p!=sentinel;p=p->next)
v[j++] = p->val
void insert(t)
i = t/(l+maxval/bins)
bin[i] = rinsert(bin[i],t)
13.5原理
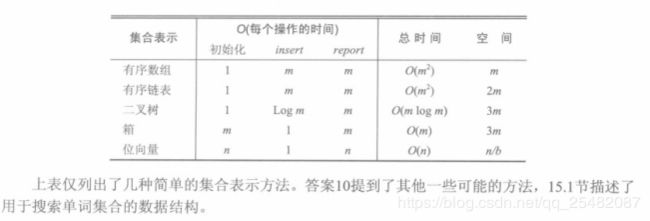
若m相对n来说比较小,结构性能如上图
库的作用:函数库的利用与实际数据结构的解决
空间的重要性:链表虽然完成的工作只有数组一半,但是却需要两倍于数组的时间,因为数组中每个元素占用的时间只有链表的一半,而且数组是顺序访问内存的,使用定制的内存方案可以使空间降为原来的三分之一,时间降为原来的一半。
代码调优算法:用分配一个较大内存块的方案来替换通用内存分配
14 堆
解决问题:
1、排序。采用堆排序算法对n元数组排序,所花时间不超过O(nlogn),而且只需要几个字的额外空间
2、优先级队列。堆通过对插入新元素和提取最小元素这两种操作来维护元素集合,每个操作所需的时间都为O(logn)
14.1 数据结构
堆是一种用来表示元素集合的数据结构。实际上堆中的元素可以是任何有序类型。
堆的性质,任何结点的值都小于或者等于其子结点的值,这意味着集合的最小值位于根结点,但是它未说明左右子节点的相对顺序;第二个性质就是形状,像△一样;

堆的实现适合于具有形状性质的二叉树
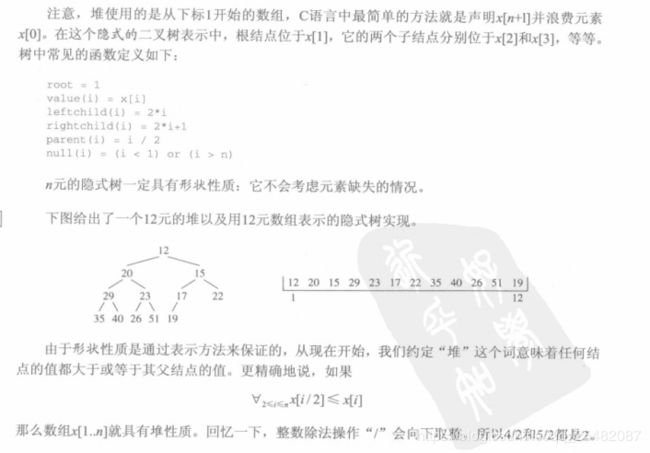
14.2两个关键函数

14.3优先级队列
14.4 一种排序算法

14.5 原理
高效性:形状性质保证了堆中所有结点和根结点之间相差的层数在log2n之内,因此siftup ,siftdown运行效率高
正确性:编写循环代码之前需要正确说出其不定式
抽象性:过程抽象和抽象数据类型
过程抽象:在不知道排序函数实现细节的情况下用它排序
抽象数据类型:
15章 字符串
C++


C语言:

