scrapy框架实现2019-nCoV省级疫情每日数据爬取
环境
win 10 + python 3.6 + pycharm + scrapy 3.2.3
获取URL
从腾讯新闻肺炎疫情进入:https://news.qq.com/zt2020/page/feiyan.htm#/
F12打开开发者工具,切换到Network,F5刷新页面,关注新出现的内容,找到我们所需要的url (https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5&callback=jQuery341007164458125928896_1583443338409&_=1583443338410)。
并且可以知道,这是一个json格式的请求。
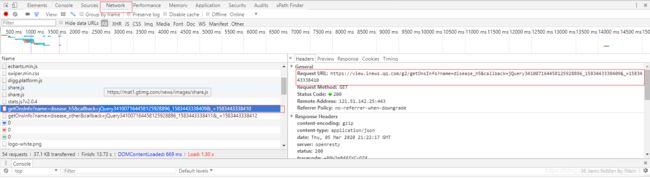
对url地址、请求方法、参数、应答格式等信息进行深入分析:
callback是回调函数,尝试清空;
“=1583443338410”中的数字为时间戳,验证方法:
import time
print(time.time())
由此,可以构造符合我们需求的url,并进行抓取:
# -*- coding: utf-8 -*-
import scrapy
from yiqing.items import YiqingItem
import time
import json, requests
class YiqingSpiderSpider(scrapy.Spider):
name = 'yiqing_spider'
allowed_domains = ['view.inews.qq.com']
start_urls = ['https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5&callback=&_=%d'%int(time.time()*1000)]
def parse(self, response):
#查看是否请求回数据
print(response.text)
print(type(response.text))分析抓取的内容
借助在线json校验格式化工具解析抓取到的内容,以json.load()和json.loads()方法对内容节点进行分析,最终得到我们所需数据的节点。


实现数据结构(items.py)
在此基础上,可以增加更多的变量,如市级、其他国家等内容。
import scrapy
class YiqingItem(scrapy.Item):
# 日期
crawl_date = scrapy.Field()
# 省名
province_name = scrapy.Field()
# 今日确诊
province_confirm = scrapy.Field()
# 今日疑似
province_suspect = scrapy.Field()
# 死亡
province_dead = scrapy.Field()
# 治愈
province_heal = scrapy.Field()数据处理并保存(yiqing_spyder.py)
记得yield进行保存,老忘记~
def parse(self, response):
# 查看是否请求回数据
# # print(response.text)
text = response.text
print(type(text))
data1 = json.loads(text)
print(type(data1))
data = json.loads(data1['data'])['areaTree'][0]['children']
print(type(data))
data_date = json.loads(data1['data'])['lastUpdateTime']
yiqing_item = YiqingItem()
yiqing_item['crawl_date'] = data_date
yield yiqing_item
for item in range(0,len(data)):
yiqing_item = YiqingItem()
# 省名
yiqing_item['province_name'] = data[item]['name']
# 今日确诊
yiqing_item['province_confirm'] = data[item]['today']['confirm']
# 今日疑似
yiqing_item['province_suspect'] = data[item]['today']['confirmCuts']
# 死亡
yiqing_item['province_dead'] = data[item]['total']['dead']
# 治愈
yiqing_item['province_heal'] = data[item]['total']['heal']
yield yiqing_item运行并导出为csv文件
中文出现乱码,记得用notepad++转为utf-8 Bom保存后,再用excel打开查看。
from scrapy import cmdline
# 运行
# cmdline.execute('scrapy crawl yiqing_spider'.split())
# 导出
cmdline.execute('scrapy crawl yiqing_spider -o test.csv'.split())结果展示
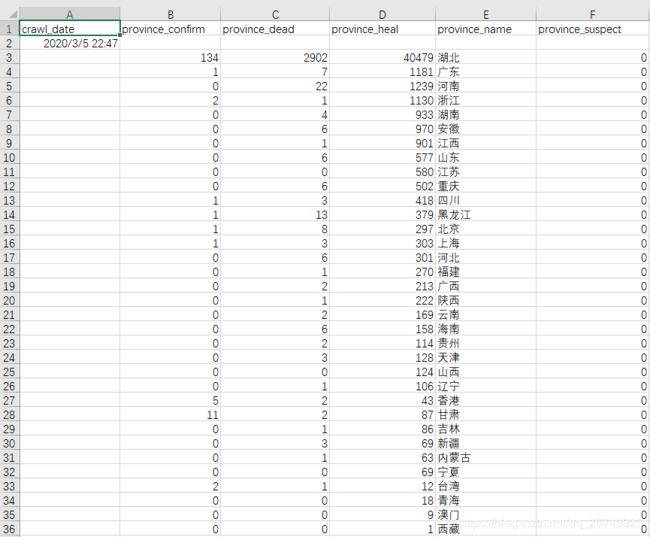
注意事项
json.load()与json.loads()的区别:
简单地说,load()是json转为dict;而loads()是str转为dict。
‘data’节点读取完后,需要将str转为dict再进行后续操作,否则会报错。
data = json.loads(data1['data'])['areaTree'][0]['children']存在的问题
- 未能实现历史数据的爬取。
- 请求访问速度好慢,不知道是什么原因。
如果有大神知道,求不吝赐教,小菜在此谢过~
推荐资料
我感觉这两位大神做的挺好的,在此推荐给大家一起学习:
疫情可视化分析系统:http://www.graphvis.cn/graphvis/sari/index.html
爬虫及可视化:https://blog.csdn.net/xufive/article/details/104093197