MSG-GAN
论文链接:https://arxiv.org/pdf/1903.06048.pdf
解决了训练生成高分辨率图像时不稳定的问题。
此论文发与2019.03.22,生成效果还不错。先上图:

Abstract
GAN成功的同时,有难点:训练不稳定。
一个原因是,训练过程中学习的不平衡,导致梯度在经过判别器传到生成器时很快变得没啥信息量。
我们提出MSG-GAN,用一个简单且有效的技术去解决这个问题,使得生成多尺度图片有了稳定的提升。
我们提出了数学MSG-GAN框架的非常直观的实现,该框架在判别器计算中使用串联操作。
我们在CIFAR10和Oxford102flower数据集上验证,并将其与其他多尺度合成技术进行了比较。
此外,我们还提供了有关CelebA-HQ数据集的实验细节,用于合成1024 x 1024高分辨率图像。
Introduction
GAN可优秀了……balabala。但有两个问题(1)模型崩塌;(2)训练不稳定。
当生成器网络只能抓住数据分布的局部方差特征时,就会产生模型崩塌问题。
不稳定的一个理论是,生成器(G)并不是在最小化真实数据和生成数据间的JS散度。
一个主要原因是,只有当所有可能的生成器(G)存在时(从好到烂的所有),判别器(D)才能最优;而所有可能的G不可能存在除非有最优的D。
所以GAN里的纳什均衡和散度最小化里的纳什均衡不一样。
我们研究了,在不依赖于先前的贪婪方法(例如渐进式增长技术)的情况下,梯度在多尺度中怎么才能被用于生产高分辨率图像(一般大多挑战都是由于空间维度)。
我们的D不仅看G的最终结果,还看中间层。
结果,D变成了G的输出的多尺度方程,更重要的是,同时将梯度传递到了所有尺度。
1.提出MSG-GAN,提升了训练稳定性
2.验证。我们鲁棒地在许多数据集生生成了高质量图片,还没有超参数调整。
Motivation(可跳过)
Arjovsky和Bottou [1]指出,GAN训练不稳定的原因之一是当真实和假分布的支持之间存在非实质重叠时,从D到G传递的梯度很随机(无信息)。
最近有两项工作专注于缓解这个问题。 “变分判别瓶颈”(VDB)和“GAN的渐进式增长”(ProGANs)。
VDB的解决方案是在输入图像与D之间应用相互信息瓶颈,并为它们提供最深刻的表示。这迫使鉴别器仅关注图像中最具辨别力的特征,以便区分真实和生成。
我们的工作与VDB技术正交,我们把研究MSG-GAN和VDB的组合工作留到以后。
(VDB论文链接:https://arxiv.org/pdf/1810.00821.pdf)
ProGAN技术通过逐层训练GAN来解决不稳定性问题,逐步将生成的图像分辨率加倍。
在训练中的每个点,所有先前训练的层都是可训练的,并且每当新的层被添加到训练时,它就慢慢地消失,使得保留先前层的学习。
直观地,该技术有助于解决不稳定性问题,因为对于添加的每个新层,网络学习更精细的细节,同时保留先前学习的低频细节,从而逐步生成合理且更高分辨率的图像。
学习和保留低频细节可确保生成图像的分布更接近真实图像的分布,从而减少训练期间不稳定的可能性。
(ProGANs论文链接:https://arxiv.org/pdf/1710.10196.pdf)
我们根据这两篇文章,做了提升。
Multi-Scale Greadient GAN
网络结构:

左边是生成器,生成器和原来一样,还是从潜码Z解码到图片。
现在根据层数,把这个生成器写成:
![]()
如图,即一共有k层,每层feature尺寸都会比原来大,是个解码的过程。
现在定义一个函数 r(就是图里的红色方块,1*1 的 Conv),把当前的feature卷到3通道。即:

也就是说,![]() 是第 i 层的所有feature map生成的图像。
是第 i 层的所有feature map生成的图像。
而生成的这些大大小小尺寸不一的图片![]() ,全都要喂给判别器判别。这样就能让梯度信息立即流入当前层。
,全都要喂给判别器判别。这样就能让梯度信息立即流入当前层。
右边是判别器,r' 是 r 的逆向操作,即有个1*1的卷积操作,把feature从3通道卷回原来的通道数。
判别器每层的公式记作:
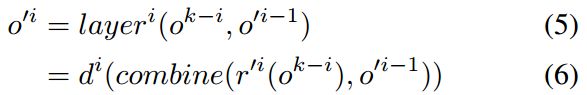
也就是说,生成器每层的feature经过 r 和 r' 操作,与和其相同尺寸的判别器feature合并作为当前层,然后一起卷积成下一个尺寸(进入下一层)。
合并可以是任何加权重合并的方式,但本文采用了concatenation操作(pytorch中的cat操作)
整个判别器的公式记作:
![]()
损失函数:
文章发现HigeGAN的损失函数表现特别好:
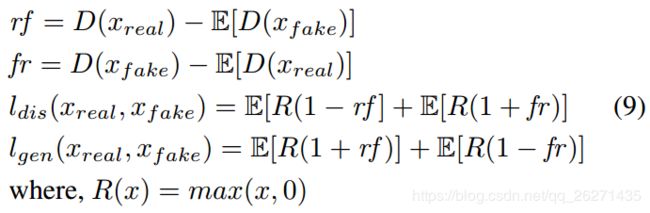
Experiments