[2020年冠状病毒肺炎 - 武汉加油] 使用回归模型和LSTM预测确诊病人数目
【2月7日更新模型】
针对之前的内容,有读者提出:
1.由于在疫情出现之后,全国各地对确诊或疑似患者进行隔离,阻止了部分病毒的传播,因此相较于指数拟合,Logistic增长模型更适合此次新型冠状病毒感染人数预测。
2.能够预测一个月之后的感染人数吗?(如果使用指数拟合当然是不行啦,我之所以使用指数拟合是因为在1月底发现当时的确诊曲线和指数函数很接近,因此简单的试了一下)
如果综合考虑以上两个问题,且不使用复杂的传染病模型,结合文章python实现logistic增长模型拟合2019-nCov确诊人数,我发现可以尝试一下使用逻辑斯蒂增长模型(Logistic growth model)做个预测,因此本次更新一下使用逻辑斯蒂函数预测的结果。事先声明,logistic增长模型也并不能准确地预估未来的确诊人数。
另外:我还发现了很多优秀的更复杂的预测模型,一并分享给大家:武汉肺炎传播的数学模型大全!
在高中生物中有提到过,种群的增长曲线有分"J"型和"S"型,其中"J"型为理想型,实际中种群的数量不可能一直像指数函数那样,而是一个S型曲线,如下图所示。
这个函数的曲线和机器学习中的Sigmoid函数
极其相似,其公式都有点像,logistic增长函数为:
其中K为环境最大容量,P0为初始容量,r为增长速率,r越大则增长越快(即更快的逼近上限)。
该模型的微分式是:
![[2020年冠状病毒肺炎 - 武汉加油] 使用回归模型和LSTM预测确诊病人数目_第1张图片](http://img.e-com-net.com/image/info8/ffbe4b5a20f84a1db527350265c4cab4.jpg)
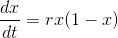
预估结果如下(预计到2月15左右新增开始明显减少),如果需要详细的代码,见[2020年冠状病毒肺炎 - 武汉加油] 使用Logistic增长模型预测确诊病人数目。
![[2020年冠状病毒肺炎 - 武汉加油] 使用回归模型和LSTM预测确诊病人数目_第2张图片](http://img.e-com-net.com/image/info8/4ab6fd56b41f4a4ca0b4f4e0681ea5c2.jpg)
(2月7日更新 完)
-----------------------------------------------------
(原文)
此次冠状病毒来势汹汹,如何通过数学模型预测肺炎的传播呢?有两个大的方向:
- 利用历史数据对未来的感染人数做预测:这是一个较为简单的预测模型,可以有以下几种思路:1. 利用历史数据进行拟合,得到拟合曲线后预测未来几天可能的感染数,但效果一般都不是太好。2. 使用时间序列模型如ARIMA对未来几天的感染人数进行预测。3. 使用神经网络如LSTM训练预测模型。
- 根据冠状病毒的传播特性以及统计数据建立传染病模型:这是一个较为复杂的问题,不过目前已经有了很多传染病模型如SIS、SIR等,可以结合此次肺炎疫情传播特性、现有样本数估计出一个大概的参数,建立适当的数学模型。这种模型能够较为精准的预估疫情的发展趋势。
在这里我只简单的尝试解决第一个问题:对数据进行拟合并对未来的感染人数进行预测。关于第二个传染病模型可以参看b站上毕导THU的科普视频简单算算,你宅在家里究竟能为抗击肺炎疫情做出多大贡献?以及一个写的很棒的带有可交互的的传染病模型文章Going-Critical(纯英文警告!)。
![[2020年冠状病毒肺炎 - 武汉加油] 使用回归模型和LSTM预测确诊病人数目_第3张图片](http://img.e-com-net.com/image/info8/7d7be34ee7ba4f7ab45f6202b2a928a2.jpg)
正文
1 使用多项式回归以及指数回归对确诊人数进行预测
我尝试分别使用多项式函数和指数函数对历史数据进行拟合,并对预测结果进行比较:发现指数函数拟合得到的预测结果偏高,多项式拟合的结果较为合理。由于官方平台公布的数据也在实时更新,因此预测结果仅作参考!
三个模型给出的1月30日确诊感染数量将在:9,900-11,000之间,由于大家都在竭尽全力抢救治疗以及对患者进行隔离,实际的确诊数量应该会低于理论值,我预测明天公布的感染数量应该在9,300至10,500之间。
数据来源:腾讯新型冠状肺炎病情实时跟踪
数据爬取日期:2020年1月30日 09点
下图是使用指数函数对历史数据进行拟合得到的后两天确诊数量预测结果(官方数据公布会有延后,如1月29的数据会在1月30日才公布,因此只有1月31号官方才会公布1月30的确诊数量):
![[2020年冠状病毒肺炎 - 武汉加油] 使用回归模型和LSTM预测确诊病人数目_第4张图片](http://img.e-com-net.com/image/info8/e90d6820b0f04764846aba4b7c9e55d1.jpg)
下图是使用四次函数对历史数据进行拟合得到的后两天确诊数量预测结果:
![[2020年冠状病毒肺炎 - 武汉加油] 使用回归模型和LSTM预测确诊病人数目_第5张图片](http://img.e-com-net.com/image/info8/9d7c2da1064c402d899b081d92e75b98.jpg)
下图是使用三次函数对历史数据进行拟合得到的后两天确诊数量预测结果:
![[2020年冠状病毒肺炎 - 武汉加油] 使用回归模型和LSTM预测确诊病人数目_第6张图片](http://img.e-com-net.com/image/info8/f969749b9831455ebeb7c59cdf1527ba.jpg)
源码:
from scipy.optimize import curve_fit
import urllib
import json
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
import plotly.express as px
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn import linear_model
import scipy as sp
from scipy.stats import norm
def date_encode(date):
# '01.24' -> 1 * 100 + 24 = 124
d = date.split('.')
month, day = int(d[0]), int(d[1])
return 100 * month + day
def date_decode(date):
# 124 -> '01.24'
return '{}.{}'.format(str(date // 100), str(date % 100))
def sequence_analyse(data):
date_list, confirm_list, dead_list, heal_list, suspect_list = [], [], [], [], []
data.sort(key = lambda x: date_encode(x['date']))
for day in data:
date_list.append(date_encode(day['date']))
confirm_list.append(int(day['confirm']))
dead_list.append(int(day['dead']))
heal_list.append(int(day['heal']))
suspect_list.append(int(day['suspect']))
return pd.DataFrame({
'date': date_list,
'confirm': confirm_list,
'dead': dead_list,
'heal': heal_list,
'suspect': suspect_list
})
def get_date_list(month):
month_day = [31, 29, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31]
ans = []
for i in range(1, month_day[month - 1] + 1):
if month == 1 and i < 13:
continue
ans.append(100 * month + i)
return np.array(ans)
url = 'https://view.inews.qq.com/g2/getOnsInfo?name=wuwei_ww_cn_day_counts'
response = urllib.request.urlopen(url)
json_data = response.read().decode('utf-8').replace('\n','')
data = json.loads(json_data)
data = json.loads(data['data'])
df = sequence_analyse(data)
x, y = df['date'].values[:-1], df['confirm'].values[:-1]
x_idx = list(np.arange(len(x)))
def func(x, a, b, c):
return a * np.exp(b * x) + c
def f_3(x, A, B, C, D):
return A*x*x*x + B*x*x + C*x + D
def f_4(x, A, B, C, D, E):
return A*x*x*x*x + B*x*x*x + C*x*x + D*x + E
plt.figure(figsize=(15,8))
plt.scatter(x, y, color='purple', marker='x', label="History data")
plt.plot(x, y, color='gray', label="History curve")
popt, pcov = curve_fit(func, x_idx, y)
test_x = x_idx + [i + 2 for i in x_idx[-2:]]
label_x = np.array(test_x) + 113
test_y = [func(i, popt[0],popt[1],popt[2]) for i in test_x]
plt.plot(label_x, test_y, 'g--', label="Fitting curve")
plt.title("{:.4}·e^{:.4}+({:.4})".format(popt[0], popt[1], popt[2]), loc="center", pad=-40)
plt.scatter(label_x[-2:], test_y[-2:], marker='x', color="red", linewidth=7, label="Predicted data")
plt.xticks(label_x, [date_decode(i) for i in label_x])
plt.ylim([-500, test_y[-1] + 2000])
plt.legend()
for i in range(len(x)):
plt.text(x[i], test_y[i] + 200, y[i], ha='center', va='bottom', fontsize=12, color='red')
for a, b in zip(label_x, test_y):
plt.text(a, b + 800, int(b), ha='center', va='bottom', fontsize=12)2 使用LSTM对未来几天的确诊人数进行预测
我尝试使用LSTM进行预测,但无奈当前的数据太少,而且数据本身只有一个递增的趋势,并不能提供太多的信息。因此预测效果并不理想,因此浅尝辄止了~
(武汉加油!)