新一代AI顾泽苍:自组织概率模型SDL主导的机器学习(公号回复“顾泽苍AI”下载PDF资料,欢迎转发、赞赏支持科普)
新一代AI顾泽苍:自组织概率模型SDL主导的机器学习(公号回复“顾泽苍AI”下载PDF资料,欢迎转发、赞赏支持科普)
原创: 秦陇纪 科学Sciences 今天
科学Sciences导读:自组织概率模型SDL主导的机器学习是新一代人工智能理论技术。工学博士顾泽苍教授提出并工程落地。他带领下“探究新一代人工智能理论沙龙”三年多来经常热烈讨论AI理论、技术、活动信息,极大促进领域发展。由中国嵌入式系统产业联盟与北京经开投资开发股份有限公司联合在2018年北京世界机器人大会上主办的“新一代人工智能创新专题论坛”于2018年8月18日上午隆重召开。本文根据顾博士PPT总结,附顾泽苍博士简历。欢迎留言探讨科学、技术、工程、方案。
新一代AI顾泽苍:自组织概率模型SDL主导的机器学习(15023字)目录
A新一代AI顾泽苍:自组织概率模型SDL主导的机器学习(11886字)
1 顾泽苍:新一代人工智能——产业推动的核心理论
2 新一代人工智能自组织机器学习介绍
3 北京世界机器人大会:新一代人工智能创新研讨会2018北京共识
4 不适合深度学习的情况
B顾泽苍博士、阿波罗集团简历(2866字)
1 创始人顾泽苍简介
2 网屏编码技术介绍
3 阿波罗集团介绍
参考文献(769字)Appx.数据简化DataSimp社区简介(835字)
A新一代AI顾泽苍:自组织概率模型SDL主导的机器学习(11886字)
新一代AI顾泽苍:自组织概率模型SDL主导的机器学习
文|顾泽仓2017-11-19Sun,整理|秦陇纪2018-08-26Sun
2017年11月19日,中国光谷国际人工智障产业峰会上,中国嵌入式系统产业联盟新一代人工智能专业委员会主任顾泽苍博士,作了题为《新一代人工智能「产业推动的核心理论」-探究Hindon的Capsules理论的实现行踪》(Ph.D.顧澤蒼)的报告。报告PPT目录CATALOG分为:1.人工智能所面临的重大危机与挑战;2.可实现全面产业化的SDL模型的构成;3.SDL模型的应用展望,三部分内容如下。
A1 顾泽苍:新一代人工智能——产业推动的核心理论
各位专家来宾辛苦了!请稍微允许我做一个简短讲演,今天在中国光谷人工智能盛会上,我想奉献一个新一代人工智能产业推动的核心理论,这将是一个全新的人工智能模型。在这里我想分三个部分介绍,一是人工智能所面临的重大危机和挑战,在大家对人工智能群情激扬的时候,我想泼一些冷水。第二可实现全面产业化SDL模型的构成,我们想以我们的算法抛砖引玉;我相信通过今天听到我们这个模型以后,我们在座每个人自己就能造模型。三是介绍一下SDL模型的应用展望。

1 人工智能所面临的重大危机与挑战
近年以来,阿尔法GO战胜了全人类棋手,全世界为此震惊,可以讲,当今没有一项技术被全世界如此这么大资源所关注,我们在座的每一个专家,我想也是群情激扬,立志在这一次人工智能高潮中建功立业,我想没有一个人不这么想的。
但是,我们出问题了,人工智能主流算法“深度学习”严重的破绽被发现了、深度学习发明者提出“我不干了”,这个可能在座的大家都知道。为什么他出现破绽?简单讲我是20多年前曾经解决过大规模集成电路的组合问题,确实也是当时从算法上找不到跟今天阿尔法GO同样的算法,通过概率、模糊关系,通过对抗学习,很成功的在当时仅16位的计算机上实现了相当大规模集成电路的组合。所以我今天看阿尔法GO其实就是一个算法,我们不要认为它是一个很神奇的东西,它所用的方法和二十多年前相差不了多少。所以我觉得我们还是有话语权的。
面对人工智能殖民了,我们是不是眼前一片黑暗?不是,面对这种情况我们要重新的、冷静的审视一下。有三个问题要大家搞清楚。
第一,我们要重新考虑究竟什么叫人工智能。可能大家最讨厌的就是这个问题了,我们已经讨论N次了。我说不是,我们到今为止就是追求有严密性,这是做教材、写书。我是搞应用,我是站在让这一代全产业应用人工智能。如果上一代人工智能特点是知识库、专家系统,这一代人工智能是机器学习解决概率问题。如果把这个概念讲清楚了,整个产业都会应用人工智能。
第二,我们要感谢Hinton,他在关键时候把人工智能方向挑战过来了。人工智能要解决概率问题,不是用大模型解决小问题,所以这一次Hinton提出要用概率模型,我非常要感谢他,如果我提出搞概率模型,大家谁都不会信;但是他说搞,大家都跟着他走。但是,我们再不能盲目崇拜他了,说句实话,他的深度学习我们已经经历了。如何看待Hinton?我个人的观点是定义什么叫CapsNet理论,按照空间定义是三个条件:第一是网络结构,不要离开神经网络,从网络结构上还是要坚持,但是再也不要传统神经网络了,它是走不下去的。第二它是概率信息的传输,第三目前模拟大脑的结构是不可能的,我们模拟大脑的机能。我待会会介绍,如何模拟一个完整的大脑机能。
第三,产业界不是光要图象识别、声音识别,我们机器当中有很多环节,今后在各个环节上都要用上人工智能。产业应用是各种各样情况的,各种各样的情况要用各种各样的模型,各种各样的模型要靠我们在座的每一个人自己来创造模型。大家说中国宣布了四个大平台,大家很担忧,是不是又被垄断了,我马上回答说不一定,因为CapsNet的观念大家理解了,我们每个人都可以造平台了,你的平台没有人用了。
1.1 人工智能面临的重大的危机与挑战:
玻尔滋曼梦想破灭!!
分析还原思想产物!!
公式性的算法!!
在人工智能发展的关键时刻Hindon宣布了主流算法被终结!!

1.2 人工智能发展如何实现「零」的腾飞:
我们要审慎的重新讨论什么是人工智能?
我们要审慎的评价CapsNet到底有多强大??
我们要审慎的考虑如何才能在产业界大规模应用???

1.3 如何解决跨越欧几里德空间与概率空间的距离?
(一)满足距离尺度:
1,非负性:∀w,v,d(w,v)≥0
2.非退化性:d(w,v)=0, 则w=v
3.对称性:∀w,v,d(w,v)=d(v,w)
4.三角不等式:∀w,r,v d(w,v)≤d(w,r)+d(r,v)
问题点:是概率空间距离的近似解,存在着v(x)≠0等问题
(二)Kullback-Leibler距离:公式如下图
问题点:是概率空间距离的近似解,存在着非线性函数的问题,以及v(x)≠0等问题
(三)L2距离:公式如下图
问题点:日本学者2013年提出的,声称是可以实现距离尺度的对称性,但是就因为这种定义的方法不符合概率空间距离是不对称的特性。
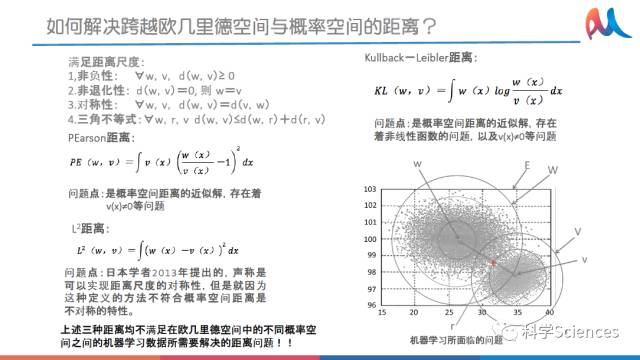
图4 机器学习所面临的问题
小结:上述三种距离均不满足在欧几里德空间中的不同概率空间之间的机器学习数据所需要解决的距离问题!!
2 可实现全面产业化的SDL模型的构成
下面我抛砖引玉,介绍一下我们新的模型,我们自己怎么造模型。这里面我们经过二十多年的发展,有两个比较重要的成果。
2.1 首次提出可以统一欧式空间与概率空间的距离的定义
第一,面对我们现在在人工智能当中所面临的数据,人工智能的是概率分布,是无数个空间关系问题,归根到底,人工智能要解决两个概率分布中间有一个数,这个数属于谁,这是最基本的问题。在这里就遇到了概率空间具体问题,大家也说了,概率空间距离数学家们搞了很多,但是今天咱们不讲这个问题,简单讲一下都没有走通,到最后都进行了某些化简,2003年日本一个学者自己又定义了一个模型。所以,我们可以看出,从数学角度上想找到一个不同距离尺度的公式是非常难的。我们在大量的应用实践当中发现,作为一个数据,从欧几里得空间进入到概率空间的时候,它产生了什么误差,我们从这个角度找到了误差的表达公式,我们就构建了一个非常严谨的,在欧几里得空间的、各个概率空间之间的距离,我们看这个公式,如果仅看上面就是欧几里得的距离公式,下面得出的值是数据进入概率空间之后的误差,用这个简单的办法解决了实体当中的应用。
为提高机器学习效率,在不同空间之间的不同距离尺度,以及即使是概率空间目前也没有一个严密的距离的解的情况下,提出了可以统一欧几里德空间与概率空间的距离:

图5 Δ(v)为不同空间之间针对v概率分布的方向的距离误差
2.2 自组织(Self-Organization)的无监督学习模型
再一个问题,如何解决无监督学习问题。大家都在议论,未来是小数据、是无监督学习,但是大家也认为无监督学习还需要相当长的时间才能出现。其实个模型二十年前就出来了,只不过我们没有公布,只是作为企业内部的诀窍,2004年才申报了专利。介绍无监督学习之前我们先谈一下,大家追求的机器学习都需要追求哪些方面?首先,是要有强大性,所以我们未来的模型一定是处理能力,或者说我在处理精度上是可以无限深入的模型。另外,叫“学习数据无限小、数据结果要无限大”,以及提出一个系统当中的机器学习不是一个,而是很多个分散系统,这样的话这个系统才海大。另外是适用性,手机也可以用。全系统的原理是透明的,没有黑箱问题。
基于这样的理念我们搞的这个无监督学习,它实际上是一个迭代公式,用了一个概率的尺度,而不是欧几里得空间的距离。你给了若干个数据,它能得出一个最大概率的值,另外它可以给出最大概率的尺度,这个尺度就是神经元的法值。

图6 概率尺度自组织机器学习单元符号
上图是我们所追求的机器学习,以及概率尺度自组织机器学习特点。
2.3 图像识别的SDL分散机器学习模型
这就是全新的人工智能网络,大家会耳目一新的,这是以图象识别为例介绍的,这种新型神经网络有三层:第一是感知层,第二是神经层,第三是脑皮层,和大脑是一样的。我也征求了一下我国著名的哲学和复杂系的数学专家,他有一个三元理论,他说应该是符合三元的。但是这样的理论我们神经网络只有三层,目前我们理解能力范围内认为是三层。

图7 用于图像识别的SDL分散机器学习模型:识别对象(空间映射1,2,n)->感知层->神经层->脑皮层,对应现在的CNN特征映射、GAN博弈模型、强化学习模型。
第一层是感知层,我们发现感知层和图像之间就是无监督学习,它可以把给定的区域通过无监督学习得到特征值,另外无监督学习抽取信息的时候可以迁移,就是这种无监督学习可以随着概率的位置发生变化的时候自动迁移,所以这就是CNN的特征映射。我们现在已经不是针对一个具体的位置进行学习了,而是抽取图像的若干个最大概率之间是什么结构,正如刚才IBM的老师介绍的,咱们固定的位置叫图象识别,我把它解构出来就变成了图象理解,你不用告诉它整体图象,你只需要给一部分就可以了。
感知层和神经层干什么?因为我们要小数据,小数据一定要把对象的概率分布通过无监督学习学习下来,所以感知层和神经层之间的机器学习主要是学习概率分布。在最终结果的时候我们有三个结果,最初是完全按照人的大脑,当样本数据进来以后,让样本数据和已经学习的最大概率的值进行比对,比对的数据如果在概率分布的尺度以内,就认为这是对的,就输出1,这和咱们的大脑就非常接近,而且我们也是在大量的观察当中,就是人的脑在看一个图像,怎么看这个图像都不变,而我们现在用一个摄像机人不动的拍,拍出来也是十个样子。所以,我们感觉到人的眼是固定空间的传感器,它观测到的是最大概率值,从这个角度讲它就可以使咱们的性能提高。
这个系统怎么样让它无限的深入?深度学习的无限深入是增加层,而我们是增加节点,甚至这一次CapsNet理论提出我有两个图象你能不能都识别?其实可以做几个并行的CapsNet层的一样的结果,它也可以分别学习图象,然后两个重合做一起,同样可以分别识别。
今天时间关系,我就把这个模型讲清楚了,后面的应用我顺便说一下。
2.4 图像直接变换代码ITC(Image To Code)的实现
因为这个模型比较强大,所以它识别的图象已经不用作为文件形式记录,可以直接变成代码。我们2014年就申报了专利,把图象变成代码,同样可以把声音变成代码,把人脸变成代码。我们最近还有一个很新的成果,就是在这组模型基础之上,实现了多函数的、多目标的知识获得。这种技术如果用在现在的自动驾驶里面,可以把优良驾驶员的驾驶情况变成数据。今天我们也公布了,在各个目标函数下它的概率分布是什么,再通过机器学习,我就可以在控制上——做到超越优良驾驶员的驾驶水平。我想这样概念作为谷歌也好,作为百度也好,他们还没有理解到,其实自动驾驶竞争的核心、人工智能竞争的核心还是在这方面。

SDL模型在国际上最为关注的是可以通过手机就可以实现各种AI的应用。目前已经成功的是可将手机拍照的任何图像,经过SDL模型可生成10^36的二维码,还可应用到人脸识别,和语音识别,以及高精度的金融预测等领域。
2.5 自动驾驶多目的控制机器学习的「知识获得」模型的提出
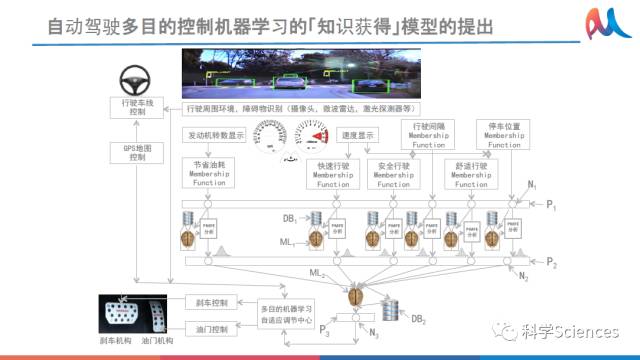
由GPS地图控制、行驶周围环境、障碍物识别、车况信息、刹车油门机构等集成的行驶车线控制,可以实现自动驾驶。
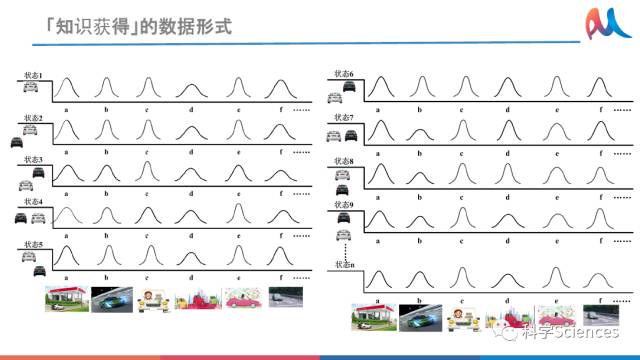
2.6 「知识获得」的数据形式
自动驾驶过程中产生的状态表征,可以看成是“知识获得”的数据形式。
3 SDL模型的应用展望
3.1 未来应用前景
未来应用前景:挑战四维空间视频检索、在流行学习上的机器学习能力确认、大众手机识别真伪、金融预测领域的应用等方面。

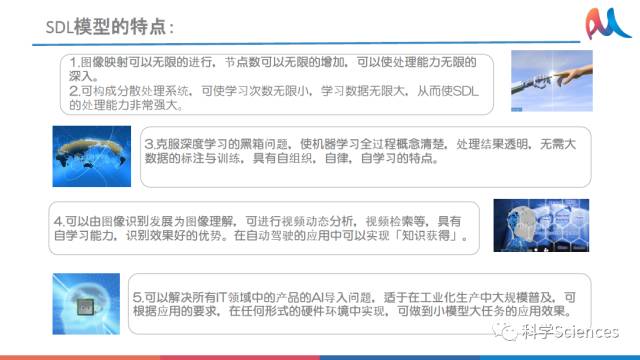
3.2 SDL模型总结
SDL模型的5大特点,图像映射可以通过节点无限增加、SDL可分布式处理学习数据、克服DL黑箱问题、图像识别可以发展成图像理解、解决IT产品AI导入问题,如下图。
4 参考文献
[1]S.Amari and H.Nagaoka. Methods ofInformaRon Gaometry. Oxford University Press,Providence,RI,USA,2006
[2]X.Nguyen, M.J.Wainwright, andM.I.Jordan. EsRmaRng Divergence FuncRonals and the Liklihood RaRo by ConvexRisk MinmizaRon. IEEE TransacRons on InformaRon Theory, 56(11): 58475861,2010
[3]M.Sugiyama, T.Suzuki, and T.Kanamori.Density RaRo EsRmaRon in Machine Learning. Cambridge University Press,Cambridge, UK,2012.
[4]M.Sugiyama, Tsuzuki, S.Nakajima,H.kashima, P.von Bunau, and M.Kawanabe. Direct Importance EsRmaRon forCovariate Shif AdaptaRon. Annals of the InsRtute of StaRsRcal MathemaRcs,60(4):699746,2008.
[5]C.Cortes, Y.Mansour, and M.Mohri.Learning Bounds for Importance WeighRng. In J.Lafferty, C.K.I.Williams, R.Zemel,J.ShaweTaylor, and A.Culoka, editors, Advances in Neural InformaRon ProcessingSystems 23,Pages 442-450,2010.
[6]M.yamada, T.Suzuki, T.Kanamori,H.Hchiya, and M.Sugiyama. RelaRve Density-RaRo EsRmaRon for Robust DistribuRonComparison. Neral ComputaRon, 25(5):1324-1370, 2013.
[7]S.Kullback and R.A.Leibler.On InformaRonand Sufficiency. The Annals of MathemaRcal StaRsRcs, 22:79-86,1951.
[8]Z.GU,S.Yamada, and S.Yoneda: “A DecomposiRon of VLSI Network Based on Fuzzy Clustering Theory”, Proc. JTCCSCC’91, pp.483488 (1991).
[9]Z.GU,S.Yamada, and S.Yoneda: “A FuzzyTheoreRc Block Placement Algorithm for VLSIDesign”, IEICE Trans, Vol.E74,No.10,pp,30653071(1991).
[10]Z.Gu, S.Yamada, K.Fukunaga,and andS.Yoneda: “A New Algorithm on VLSIBlock PlacementUsing Fuzzy Theory”, Proc. JTCCSCC’90, pp599604 (1990).
[11]Z.Gu, S.Yamada, and S.Yoneda: “TimingDriven Placement Method Based on Fuzzy Theory”, IEICE Trans., Vol.E75A, No.7, pp917919(1992).
[12]Z.Gu, S.Yamada, K.Fukunaga,andS.Yoneda: “A FuzzyTheoreRc TimingDriven Placement Method”, IEICE Trans, Vol.E75A, No.10, pp12801285 (1992).
[13]K.Pearson: “On the Criterion that aGiven System of DeviaRons from the Probable in the Case of a Correlated Systemof Variables is Such that it can be Reasonably Supposed to have Arisen fromRandom Sampling”, Philosophical Magazine Series 5, 50(302):pp157175,1900.
[14]M.R. Anderberg: “Cluster Analysis forApplicaRons”, Academic Press, Inc. 1973.
[15]Alex Krizhevsky, Ilya Sutskever, GeoffreyE. Hinton :”ImageNet ClassificaRon with Deep ConvoluRonal NeuralNetworks”,Advances in Neural InformaRon Processing Systems 25: pp1097-1105(2012).
最后我谈一下参加这个会的体会,我感觉到了武汉的领导、武汉人工智能界的专家学者们对人工智能非常重视,所以我既然被请来了,我也想为武汉作贡献,如果在座的学者们非常愿意投身到这种人工智能模型的开发上,在我们本身所面临的产业上的应用,不管需要我们提供什么技术支持,或者咱们一起共同研究,我们都非常欢迎,感谢大家!
A2 新一代人工智能自组织机器学习介绍
新一代人工智能自组织机器学习介绍
文|顾泽苍,2018年8月18日
2016年随着AlphaGo战胜全人类棋手,使世界为之震惊,历史上从来没有过,对于一个技术投入了世界上如此巨大的资源。国际大的IT公司利用这个契机,为了牟取暴利,取得世界人工智能的发展主导权,极力宣传“深度学习模型”,把“深度学习模型”神化,同时又抛出了各种类型的“深度学习模型”的开源程序,以及大型GPU服务器。
在这种势力的推动下,我国年轻的人工智能研究者只能在开源程序下研究,不了解“深度学习模型”的所以然,因此,受害匪浅。
其实,“深度学习模型”存在着训练不可能得到最佳解,作为补救措施的SGD也只能得到局部最佳解。因此“深度学习模型”不可解决黑箱问题,因此不可用于工业控制等场所。再加上属于大模型解决小任务,投入产出不对称等等原因,最终被“深度学习模型”发明者英国Hinton教授宣告旧的“深度学习模型”终结。
在此之后,开启了新一代人工智能的时代。一个经过20多年的声音识别,图像识别检验的,引领新一代人工智能发展的自组织机器学习Self-Organization Learning(SOL),在2018年北京世界机器人大会的新一代人工智能创新专题论坛上正式发布。
自组织机器学习的原理是,首先立足于一个最大概率的尺度,可以产生最大概率的空间,在最大概率空间又可以生成新的最大概率尺度,依次迭代;最终可以获得超越统计学公式化的最大概率的解,以及最大概率的空间范围,并可以把目标函数的最大概率的分布信息获得。这样的三个结果,几乎是我们遇到的所有目标函数都希望获得的,例如在图像识别上,希望得到最大概率的特征抽出,最大概率的图像识别结果等等,因此可作为普遍应用的机器学习模型。
自组织机器学习的特点还有,可以自律的朝着大概率的方向迁移,最终可以越过小概率的扰动的阻挡,最终在最大概率的区域上停止,因此自组织机器学习概念清楚,透明性强,可做到不管遇到什么状况,都具有可分析性。
再有自组织机器学习还具有模仿人眼神经网络机能的特点,人眼在反复的看到一个物体时,其图像是没有任何变化的,但是通过光电识读若干次得到的图像差别很大,自组织机器学习的出现,使人们搞清了人眼的神经网络的机理,人的眼神经是在概率空间上观察物体的,所获的的信息是最大概率的信息,在最大概率空间中所得到的信息是一样的,所以最大概率的尺度就是人眼神经网络的阀值,所以采用自组织机器学习,可以获得同人眼近似的图像识别效果。
自组织机器学习是属于小数据的无监督机器学习,无须训练也可以工作,5-10次以上的训练就足可以满足使用要求。不需要大数据的人工标注,降低了应用成本。
自组织机器学习处理效率高,可以降低计算复杂度,根据应用的规模,可以小到手机,或一个CPU,大到GPU大型服务器,都可以高效率的导入自组织机器学习。特别是自组织机器学习可以解决几乎所有IT领域的问题,因此可以通过无穷多的自组织机器学习搭建出具有超出人们想象的功能的巨型人工智能系统。
早在2016年,通过自组织及其学习连接成具有三层节点的新型神经网络诞生了。新型神经网络有感知层、神经层以及脑皮层,与生物神经结构吻合。感知层与神经层之间的节点之间连接着自组织机器学习,随着处理对象的复杂性,多样性等的应用要求,感知层与神经层的节点可以无限延伸,但是计算复杂度不变,不会因为系统的处理功能的提高而降低计算的效率,这是一般系统很难达到的系统结构。
由自组织机器学习应用于自动驾驶应用中,显示出独特的威力。针对目前自动驾驶控制的空前的复杂性,几乎成为NP控制问题,是通过传统控制方法无法解决自动驾驶系统的所有可能的控制。利用自组织机器学习搭建的人工智能系统,参与到自动驾驶的控制系统中,通过机器向人学习,机器的意识决定等可以使自动驾驶系统突破L3级,成为完全可以摆脱人的操作的新型自动驾驶系统。
自组织机器学习代表了新一代的人工智能,可以被广泛应用,并将使所有的应用领域发生颠覆性的改变。自组织机器学习可以引发新的工业革命的产生,可以实现人们不可想像的应用效果,可以大大加快机器代替人的社会发展步伐,可以让奋战在人工智能研究和应用领域中的每一位专家、学者和工程技术人员在本次人工智能的高潮中都有建功立业的机会。
A3 北京世界机器人大会:新一代人工智能创新研讨会2018北京共识
2018北京世界机器人大会:新一代人工智能创新研讨会北京共识
2018年8月18日
2018年北京世界机器人大会的“新一代人工智能创新专题论坛”,2018年8月18日上午隆重召开,中国嵌入式系统产业联盟与北京经开投资开发股份有限公司联合主办。中国工程院李伯虎院士等专家应邀出席上午论坛,并进行了大会讲演。下午,新一代人工智能创新研讨会上,与会专家们就新一代人工智能的创新发展进行了广泛讨论,最后达成了如下的新一代人工智能创新发展2018北京共识。与会专家认为:
2016年随着AlphaGo战胜全人类棋手,使世界为之震惊,历史上从来没有过,对于一个技术投入了世界上如此巨大的资源。国际大的IT公司利用这个契机,为了谋取暴力,取得世界人工智能的发展主导权,极力宣传“深度学习模型”,把“深度学习模型”神化,同时又抛出了各种类型的“深度学习模型”的开源程序,以及大型GPU服务器。
在这种势力的推动下,我国的年轻的人工智能研究者只能在开源程序下研究,不了解“深度学习模型”的所以然,因此,研究的深入与前瞻性被束缚。
从另一角度,其实“深度学习模型”,存在着训练不可能得到最佳解,作为补救措施的SGD也只能得到局部最佳解,因此“深度学习模型”不可避免的存在黑箱问题,既然有黑箱问题就不可以在工业控制等大多数场合的普及,再加上深度学习属于大模型解决小任务,投入产出不对称等等原因,况且已经被发明者英国的Hinton教授宣告“深度学习模型”的终结。
为了获得人工智能发展的主动权,摆脱国际大公司的束缚,拨乱反正,一定要推动新一代人工智能的时代展开,我们共同认识到:
1. 新一代人工智能的技术境界是以具有自组织能力的概率模型为主导的机器学习;
2. 是可以超越公式化算法的模型,是不需要传统神经网络那样只能通过穷举法才可获得最佳训练解的新型网络;
3. 是具有强对抗能力的机器学习模型;
4. 是可以处理欧几里的空间中的概率空间的数据;
5. 具有可以统一欧几里德空间与概率空间尺度关系的分类能力;
6. 是具有小数据或无数据训练,可降低导入成本的特点;
7. 具有可以模拟人眼生物神经网络的能力;
8. 具有可以根据应用的要求,用众多的机器学习构建成一个完整的分散处理的人工智能大系统能力;
9. 具有自主决策和自主Agent能力的;
10. 具有可以无穷的深入处理的能力而计算复杂度不变的特性;
总之,新一代人工智能具有强大性,实用性,透明性,可分析性,以及概念性强等的特点,适于广泛的实际应用推广。
与会专家一致认为,要深入贯彻国务院有关“发展新一代人工智能的规划”精神,充分利用社会资源与政府资源,将以自组织机器学习为核心的人工智能模型进行普遍宣传扩大认知度,尽快深入行业,按行业开发出样板工程,以点带面,尽快提供开源程序以利普及。
与会专家提议,新一代人工智能的应用不仅要在图像识别,声音识别上推广应用,更重要的是应该在产业界进行重点推广,突破人工智能不能用于产业界的禁令,为新一次工业革命的到来提供技术支持。
为了在人工智能领域中拨乱反正,把人工智能的研究人员从追求抽象的概念,过于务虚的现状扭转过来,必须针对如何在本次人工智能的高潮中,利用社会给予的巨大资源,为社会贡献,因此必须旗帜鲜明的指出:本次人工智能的特点就是“机器学习解决随机问题,绕开NP问题”,理解了这个结论才可以在本次人工智能的高潮中建功立业发挥作用,不辜负社会的期望。
最后,针对历史上人工智能发展曲折的问题,与会专家认为:人工智能所以出现反复,主要原因是绝大多数人工智能专家力图从生物神经的结构中探索计算论的神经模型,但是由于生物科学与计算科学是完全不同的科学领域,具有相当的差异性,如同飞机并不可能仿真飞鸟那样,人工智能就是针对复杂系问题的人为介入的高级阶段的算法,用具有雄厚数学基础理论支持的算法逼近生物学神经的机能是人工智能发展的必由之路,也是新一代人工智能的基因。
本次共识是基于针对人工智能的工程性的探讨,基于可以实证性的理论或试验所产生的结论,是本着如何最大限度的能在本次人工智能高潮中获得最大社会效益的意愿,不含盖人工智能未来长期性发展的研究。
本共识仅在传统的神经网络深度学习被终结,新一代人工智能的时代的开启中,为担负着人工智能的研究开发,以及应用的专家技术人员提供一个启发。
中国嵌入式系统产业联盟新一代人工智能专业委员会
新一代人工智能研究会主持提出2018年8月18日

A4 不适合深度学习的情况
不适合深度学习的情况
文|秦陇纪,来源:人工智能学家,2018-08-28
学习了新一代人工智能理论SDL技术,我们回顾一下现在流行的人工智能技术——神经网络的概念。神经网络主要是指一种仿造人脑设计的简化的计算模型,这种模型中包含了大量的用于计算的神经元,这些神经元之间会通过一些带有权重的连边以一种层次化的方式组织在一起。每一层的神经元之间可以进行大规模的并行计算,层与层之间进行消息的传递。
并非所有应用都需要使用到深度学习,在有些情况下,使用深度学习是不合适的,我们需要选择一些别的方案。先看一下这些不适合的情况。
(1)深度学习不适用于小数据集
深度网络为了获得高性能,需要非常多标注的数据集。数据越多,模型性能就越好。但获得标注良好的数据,既昂贵又耗时。雇佣人工手动收集图片并标记图像,根本没有效率可言。在现在高潮的深度学习时代,数据无疑成为最有价值的资源。最新研究表明,实现高性能网络通常需要经过数十万甚至数百万样本的训练。对许多应用来说,这样大的数据集并不容易获得,并且获取成本高且耗时。对于较小数据集,传统ML算法(如回归、随机森林和支持向量机)通常优于深度网络。
(2)深度学习运用于实践是困难且昂贵的
深度学习仍然是一项非常尖端的技术。虽然有很多快速简便解决方案,如使用API调用Clarifai和Google的AutoML。但想做定制化功能,这样的服务是不够的。除非你愿意把钱花在研究上,否则你就会局限于做一些和其他人稍微相似的事情。这也是很昂贵,不仅是因为需要获取数据和计算能力所需的资源,还因为需要雇佣研究人员。深度学习研究现在非常热门,所以这三项费用都非常昂贵。当你做一些定制化的事情时,你会花费大量的时间去尝试和打破常规。
(3)深层网络不易解释
深层网络就像是一个“黑盒子”。到现在,研究人员也不能完全理解深层网络内部。深层网络具有很高的预测能力,但可解释性较低。由于缺乏理论基础,超参数和网络设计也是一个很大的挑战。虽然最近有许多工具,如显著性映射(saliencymaps)和激活差异(activation differences),它们在某些领域非常有效,但它们并不能完全适用于所有应用程序。这些工具的设计主要用于确保您的网络不会过度拟合数据,或者将重点放在虚假的特定特性上。仍然很难将每个特征的重要性解释为深层网络的整体决策。

另一方面,经典ML算法,如回归或随机森林,由于涉及到直接的特征工程,就很容易解释和理解。此外,调优超参数和修改模型设计的过程也更加简单,因为我们对数据和底层算法有了更深入的了解。当必须将网络的结果翻译并交付给公众或非技术受众时,这些内容尤其重要。我们不能仅说“我们卖了那只股票”或“我们在那个病人身上用了这药”是因为我们的深层网络是这么说的,我们需要知道为什么。不幸的是到目前为止,深度学习所有证据或解释都是经验主义的。
B顾泽苍博士、阿波罗集团简历(2866字)
顾泽苍博士、阿波罗集团简历
文|秦陇纪,汇编自:百度百科、阿波罗官网,2018-08-28Tue
1 创始人顾泽苍简介
顾泽苍博士现任南开大学教授,天津软件园驻日本国首席代表,阿波罗集团首席科学家。中文名:顾泽苍,职业:南开大学教授,毕业院校:日本大阪府立大学,所修专业:信息处理。

图1 董事长顾泽苍
顾泽苍,毕业于日本大阪府立大学博士后期课程,并获工学博士学位,所修专业为信息处理。在博士课程的研究阶段里,顾泽苍博士通过不断的努力钻研,运用Fuzzy事项概率理论成功地解决了国际上多目的组合理论中一直没能解决的最优化问题,被国际上若干个权威机构所肯定,认为是在多目的最优化组合理论中,90年代的代表性提案。目前,该理论已被应用于大规模集成电路的最优化设计中。此外,顾泽苍博士还在模式识别理论上提出了概率尺度的Clustering提案,这一提案解决了最佳识别的问题,已被国际上广泛应用于声音识别及图象识别技术中。[3]
大阪府立大学大学院,修工学博士(信息处理)
2000年在中国天津市,创立天津市阿波罗信息技术有限公司
2005年在日本神戸市,创立日本阿波罗株式会社
凭借个人在学术研究领域中所取得的成绩,及多年积累的技术经验,顾泽苍博士抓住机遇,创建阿波罗集团。他勇于开拓进取的精神,使得阿波罗集团的业绩逐年来稳步攀升,公司向着规模化、现代化迈进。
顾泽苍博士研发项目与创办企业的宗旨是,以高科技产品开发为先导,以科技成果商品化、产业化、国际化为重点,发挥人才优势,融信息、人才、成果和市场四位一体,全面发展,使公司逐步成为技术密集与外向型,信息与产业相结合的多功能企业集团。
词条标签:行业人物,科研人员。词条统计:浏览29106次,编辑8次历史版本,最近更新:2018-05-17,创建者:安徽苏舟。[4]

2016年,中国嵌入式系统产业联盟新一代人工智能专业委员会成立,顾泽苍出任首届专委会主任。2018年8月18日在北京召开的的“2018北京世界机器人大会”上,提出新一代人工智能创新研讨会北京共识。[6]

图3 顾泽苍
2018年2月26日(周一)晚21:30的《非你莫属》中,一位旅日30年的人工智能科学家登上了求职舞台。半辈子专注科研,参与了世界上多个品牌项目的研发,在他的职业生涯中曾获得过150项专利证书,如今,他希望发挥余热为国做出贡献。
顾泽苍,一位64岁的老先生,来自广东,大阪府立大学大学院信息学专业博士。1988年到日本留学至今,已在海外生活了30余年,曾参与谷歌眼镜的研发,东芝复印机内部核心内容的研发,国内早期点读笔的研发,是日本人工智能领域的首席科学家。在他的职业生涯中曾获得150多项的专利认证,就专利项目每年即可获得600万人民币的专利授权费。来到《非你莫属》,他只要求月薪2万元。顾先生的到来,令在场的老板们十分兴奋。在接下来的面试中,他展示了一项怎样奇特的高科技发明令现场赞叹不已?他的专业性也令老板们深感敬佩,但同时一个问题出现了,哪位老板能够“驾驭”这位科学家?最终,双方会如何选择?今晚(周一)晚21:30,《非你莫属》精彩继续!
网站关键词:非你莫属20180226期顾泽苍个人资料背景经历 64岁科学家求职。
以下内容选自http://www.apollo-asia.com/info.html阿波罗集团公司官网。[3]
2 网屏编码技术介绍
所谓的网屏编码,就是【带有印刷网屏特性的信息埋入码】
一听到【码】让人想到的,也许是买东西时所用的条形码,或者通过手机浏览网页的QR码。
网屏编码与上面所提到的码有什么不同呢?不同之处在于网屏编码是通过肉眼看不到的微小的点埋入信息。刚才提到的条形码和QR码,用眼睛能看到的。网屏编码的特征是肉眼难以识别。因此,据说是最适合重视图案性的印刷物的码了。另外,因为网屏编码适合于多种用途,所以在用于保密的码、用于能发音的印刷物的码等,可以用于多种用途。
围绕网屏编码所展开的主要事业
统合纸出版与电子出版的多媒体印刷事业
面向金融、保险的自动读取事业
针对网络服务器的手机读取事业
针对打印机和复印机的复印禁止与防止伪造等的安全保密事业
网屏编码的社会贡献
世界首创!可以实现下列功能
无法篡改的文件
不可伪造的商标品牌
不可偷听的秘密文件的密码化
不可伪造的纸币做成
详细介绍请见PDF文件
有关网屏编码的问题和解答请见PDF文件
3 阿波罗集团介绍
株式会社阿波罗日本
設立:2005年3月
所在地:横浜市鶴見区小野町75-1 LVP1号館
業務内容:隐形码相关产品的开发
資本金:4,000万円
代表取締役顧 澤蒼
大阪府立大学大学院卒(工学博士:信息処理)
横滨市居住
天津市阿波罗信息技术有限公司
総裁:顧 澤蒼
設立:2000年11月
資本金:1,150万元 (1.6億円相当)
業務内容:隐形码相关产品开发
業務伙伴:日本生命集团 东芝 三菱电机等

3.1 公司概要
公司名称:日本阿波罗株式会社
地址:(横滨事务所)邮编:230-0046 神奈川县横滨市鹤见区小野町75-1
横滨超前创业广场1号馆503号
TEL045-633-7868FAX 045-633-7867
创立时间:2005年3月29日
注册资本:27,350,000日元
业务领域:1、面向教育领域的多媒体印刷系统
2、纸文件的安全整体解决方案
3、针对金融保险的申请单以及面向法人的商业表格的自动读取
4、手机的网屏编码读取
5、其他有关的事业
6、软件受托业务
业务的内容:1、有关网屏编码的读取机器的制造和销售
2、有关网屏编码的软件的开发和销售
3、网屏编码IC芯片以及有关零部件的销售
4、网屏编码的特许许可的销售
5、另外,相关商品的开发和销售
往来客户:三菱电机株式会社
三菱电机コントロールソフトウェア株式会社
三菱电机エンジニアリング株式会社
日生信息技术株式会社
株式会社ルック
学校图书株式会社
松香フォニックス研究所
文教スタジオ株式会社
东芝テック株式会社
3.2 集团企业
集团名称:天津市阿波罗信息技术有限公司
地址:天津市华苑产业园区榕苑路15号1-B-1803
TEL022-58171578 FAX 022-58171576
创立时间:2000年11月
注册资本:1150万元
负责人:工学博士 顾泽苍
业务内容:1、印刷和打印机基板的CTP系统的开发与销售
2、CTP专用板的生产与销售
3、印刷DTP组版系统的开发与销售
4、使用网屏编码开发金融帐票的自动读取系统以及销售
5、软件包的开发与销售
6、计算机有关器材的生产与销售
7、其他的相关器材零部件生产与销售
主要的往来客户: 东レエンジニアリング(株)
三菱电机(株)
(株)岛津ビジネスシステムズ
株式会社ルック
ニッセイ情報テクノロジ(株)
三菱电机MCR(株)
天津丰田汽车有限公司
天津板硝子有限公司
ハニウエル社(米国)
ウェナル社(ドイツ)
About Apollo-公司简介-联系方法-招聘信息-客户服务-隐私政策
天津市阿波罗信息技术有限公司
地址:天津市河北区博爱道君临大厦2817
电话:022-83710807 传真:022-83710942
-END-
参考文献(769字)
1.顾泽苍,中国嵌入式系统产业联盟新一代人工智能专业委员会主任报告:新一代人工智能「产业推动的核心理论」-探究Hindon的Capsules理论的实现行踪,中国光谷国际人工智障产业峰会,2017-11-20.
2.责任编辑:蔡芳华.湖北>湖北地方资讯>正文,顾泽苍:新一代人工智能——产业推动的核心理论.[EB/OL]凤凰网湖北综合,http://hb.ifeng.com/a/20171120/6164658_0.shtml,2017-11-20.
3-6.产业智能官.【人工智能】2018北京世界机器人大会,新一代人工智能创新研讨会北京共识.[EB/OL]产业智能官,https://mp.weixin.qq.com/s?__biz=MzI3NDI4MzIyNQ==&mid=2247489459&idx=1&sn=4841172b46a6d88cacecc3ca45df81ee,2018-08-18.
4.阿波罗集团.创始人简介.[EB/OL]天津市阿波罗信息技术有限公司,http://www.apollo-asia.com/info.html,访问日期2018-08-28.
5.创建者:安徽苏舟.顾泽苍.[EB/OL]百度百科,https://baike.baidu.com/item/%E9%A1%BE%E6%B3%BD%E8%8B%8D/2102871,2018-05-17.
x.秦陇纪.数据简化社区2018年全球数据库总结及18种主流数据库介绍;数据科学与大数据技术专业概论;人工智能研究现状及教育应用;信息社会的数据资源概论;纯文本数据溯源与简化之神经网络训练;大数据简化之技术体系.[EB/OL]数据简化DataSimp(微信公众号),http://www.datasimp.org,2017-06-06.
新一代AI顾泽苍:自组织概率模型SDL主导的机器学习(15023字)
秦陇纪
简介:新一代AI顾泽苍:自组织概率模型SDL主导的机器学习,附顾泽苍博士简历。(公号回复“顾泽苍AI”,文末“阅读原文”可下载19图17k字18页PDF资料,欢迎转发、赞赏支持科普。)蓝色链接“科学Sciences”关注后下方菜单项有文章分类页。作者:顾泽苍。来源:顾博士授权、数据简化社区秦陇纪微信群聊公众号,引文出处请看参考文献。主编译者:秦陇纪,数据简化社区、科学Sciences、知识简化新媒体创立者,数据简化OS架构师、C/Java/Python/Prolog程序员,IT教师。每天大量中英文阅读/设计开发调试/文章汇译编简化,时间精力人力有限,欢迎转发/赞赏/加入支持社区。版权声明:科普文章仅供学习研究,公开资料©版权归原作者,请勿用于商业非法目的。秦陇纪2018数据简化DataSimp综合汇译编,投稿合作,或出处有误、侵权、错误或疏漏(包括原文错误)等,请联系[email protected]沟通、指正、授权、删除等。欢迎转发:“数据简化DataSimp、科学Sciences、知识简化”新媒体聚集专业领域一线研究员;研究技术时也传播知识、专业视角解释和普及科学现象和原理,展现自然社会生活之科学面。秦陇纪发起未覆盖各领域,期待您参与~~强烈谴责超市银行、学校医院、政府公司肆意收集、滥用、倒卖公民姓名、身份证号手机号、单位家庭住址、生物信息等隐私数据!
Appx.数据简化DataSimp社区简介(835字)
信息社会之数据、信息、知识、理论持续累积,远超个人认知学习的时间、精力和能力。应对大数据时代的数据爆炸、信息爆炸、知识爆炸,解决之道重在数据简化(DataSimplification):简化减少知识、媒体、社交数据,使信息、数据、知识越来越简单,符合人与设备的负荷。数据简化2018年会议(DS2018)聚焦数据简化技术(DataSimplificationTechniques):对各类数据从采集、处理、存储、阅读、分析、逻辑、形式等方面做简化,应用于信息及数据系统、知识工程、各类数据库、物理空间表征、生物医学数据,数学统计、自然语言处理、机器学习技术、人工智能等领域。欢迎投稿数据科学技术、简化实例相关论文提交电子版(最好有PDF格式)。填写申请表加入数据简化DataSimp社区成员,应至少一篇数据智能、编程开发IT文章:①高质量原创或翻译美欧数据科技论文;②社区网站义工或完善S圈型黑白静态和三彩色动态社区LOGO图标。论文投稿、加入数据简化社区,详情访问www.datasimp.org社区网站,网站维护请投会员邮箱[email protected]。请关注公众号“数据简化DataSimp”留言,或加微信QinlongGEcai(备注:姓名/单位-职务/学校-专业/手机号),免费加入投稿群或“科学Sciences学术文献”读者微信群等。长按下图“识别图中二维码”关注三个公众号(搜名称也行,关注后底部菜单有文章分类页链接):
数据技术公众号“数据简化DataSimp”:

科普公众号“科学Sciences”:

社会教育知识公众号“知识简化”:

(转载请写出处:©秦陇纪2010-2018汇译编,欢迎技术、传媒伙伴投稿、加入数据简化社区!“数据简化DataSimp、科学Sciences、知识简化”投稿反馈邮箱[email protected]。)
普及科学知识,分享到朋友圈

转发/留言/打赏后“阅读原文”下载PDF
阅读原文

微信扫一扫
关注该公众号