(四)微众Fate-横向联邦学习-预测
总目录
总目录
(一)联邦学习-入门初识
(二)联邦学习-Fate单机部署
(三)微众Fate-横向联邦学习实践-训练评估
(四)微众Fate-横向学习联邦-预测
(五)微众Fate-横向联邦学习实践-在线预测
上面通过训练得出模型home_lr_0,homo_lr_1,我们接下将基于上一章进行预测实践。
目录
- 1. 获取训练模型信息
- 2. 编写预测配置文件
- 3.开始预测
- 4. 查看预测结果
- 5. 获取所有预测结果
- 5.1 获取guest所有预测结果
- 5.2 获取host所有预测结果
- 6.总结
1. 获取训练模型信息
因为后面需要用到model_id以及model_version,我们需要通过命令行的方式读取。具体命令模板如下
python ${your_fate_install_path}/fate_flow/fate_flow_client.py -f job_config -j ${jobid} -r guest -p
${your_fate_install_path}: fate安装目录
-j :${jobid} :任务ID
-r: 角色
-p: ${guest_partyid}:partyId
-o: 文件数据路径
Dockre exec -it fate_python bash 进入fate容器
输入以下命令
python fate_flow/fate_flow_client.py -f job_config -j 202002280915402308774 -r guest -p 10000 -o examples/federatedml-1.x-examples/homo_logistic_regression
控制台输出相关信息如下:
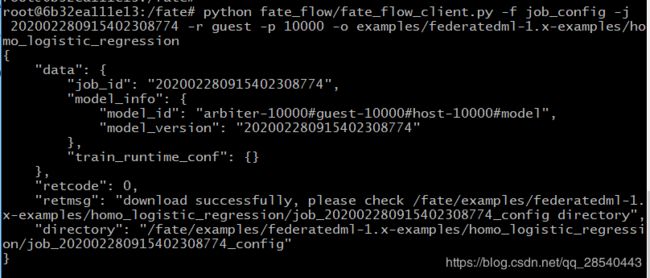
进入输出目录,可看到输出的文件

dsl.json:与训练时候定义的dsl配置相对应。
runtime_conf.json:与训练时候定义的运行配置相对应。
Model_info.json:模型信息,包括model_id model_verison
train_runtime_conf.json:暂时没有看到相关资料,后续补充
2. 编写预测配置文件
使用文件examples/federatedml-1.x-examples/homo_logistic_regression/test_predict_conf.json
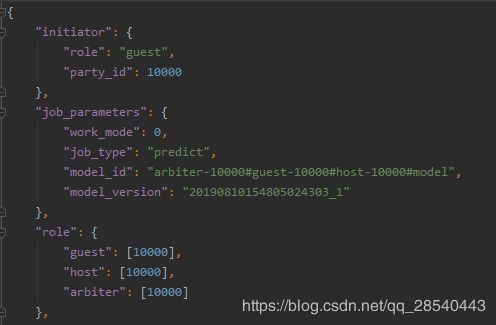
1. 发起人:指定发起人的角色和partyID,应与训练过程相同。
2. job_parameters:
work_mode:单机或者集群,它应与训练过程相同。
model_id \ model_version:##1中获取的信息匹配。
job_type:任务类型。分为train/predict 在这种情况下,它应该是“predict”。
3. 角色:指出所有角色的所有partyID,应与训练过程相同。
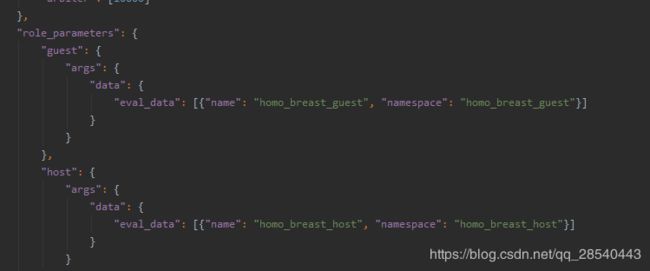
role_parameters:角色配置,guest使用homo_breast_guest数据进行预测,host使用homo_breast_host进行预测。
由于fate_python容器里面没有编辑软件我们输入以下命令下载一波
apt-get update
apt-get install vim
然后愉快地使用vi/vim命令编辑文件就行了。
3.开始预测
预测的模板命令如下:
python ${your_fate_install_path}/fate_flow/fate_flow_client.py -f submit_job -c ${predict_config}
${your_fate_install_path}: fate安装目录
-c:预测文件配置路径 ${predict_config}
控制台输入以下命令:
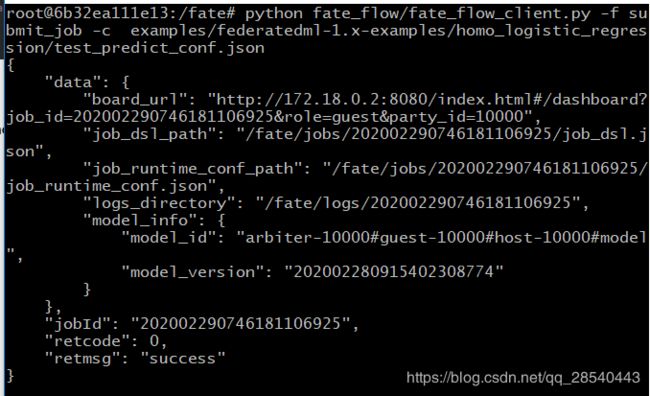
python fate_flow/fate_flow_client.py -f submit_job -c examples/federatedml-1.x-examples/homo_logistic_regression/test_predict_conf.json
输出以下结果表示成功:
4. 查看预测结果
通过监控平台以及job_id查看预测情况
总体情况如下:
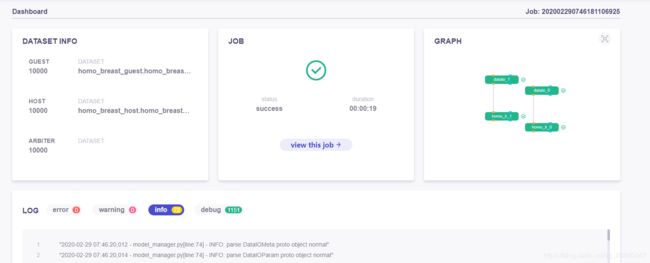
点击"view the job" 查看具体情况
先看这个图,这个图我们无法得知各个组件之间的输入输出关系。
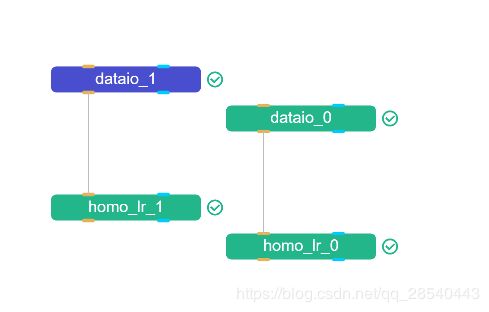
因此我们还是需要看他的dsl,继续##1的查询命令
python fate_flow/fate_flow_client.py -f job_config -j 202002290746181106925 -r guest -p 10000 -o examples/federatedml-1.x-examples/homo_logistic_regression
查看输出目录的dsl.json,找到对应配置如下:
{
"components": {
"dataio_0": {
"CodePath": "federatedml/util/data_io.py/DataIO",
"input": {
"data": {
"data": [
"args.eval_data"
]
},
"model": [
"pipeline.dataio_0.dataio"
]
},
"module": "DataIO",
"output": {
"data": [
"train"
]
}
},
"dataio_1": {
"CodePath": "federatedml/util/data_io.py/DataIO",
"input": {
"data": {
"data": [
"args.eval_data"
]
}
},
"module": "DataIO",
"output": {
"data": [
"eval_data"
]
}
},
"homo_lr_0": {
"CodePath": "federatedml/linear_model/logistic_regression/homo_logsitic_regression/homo_lr_guest.py/HomoLRGuest",
"input": {
"data": {
"eval_data": [
"dataio_0.train"
]
},
"model": [
"pipeline.homo_lr_0.homolr"
]
},
"module": "HomoLR",
"output": {
"data": [
"train"
]
}
},
"homo_lr_1": {
"CodePath": "federatedml/linear_model/logistic_regression/homo_logsitic_regression/homo_lr_guest.py/HomoLRGuest",
"input": {
"data": {
"eval_data": [
"dataio_1.eval_data"
]
},
"model": [
"pipeline.homo_lr_1.homolr"
]
},
"module": "HomoLR",
"output": {
"data": [
"predict"
]
}
}
}
}
查看data_output,对别label与predict_result
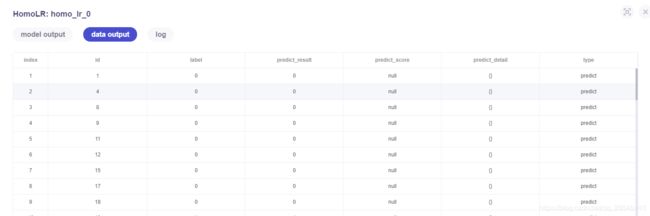
5. 获取所有预测结果
Fate_board默认查看100条,我们想要获取全部数据可以通过命令行实现。
模板命令如下:
python ${your_fate_install_path}/fate_flow/fate_flow_client.py -f component_output_data -j ${job_id} -p ${party_id} -r ${role} -cpn ${component_name} -o ${predict_result_output_dir}
${job_id}: 预测任务ID
${party_id}: 用户partyID
${role}: 角色
${component_name}: 获取预测结果的组件
${predict_result_output_dir}: 输出目录
5.1 获取guest所有预测结果
控制台输入以下命令:
homo_lr_0预测结果:
python fate_flow/fate_flow_client.py -f component_output_data -j 202002290746181106925 -p 10000 -r guest -cpn homo_lr_0 -o examples/federatedml-1.x-examples/homo_logistic_regression/predict
homo_lr_1预测结果:
python fate_flow/fate_flow_client.py -f component_output_data -j 202002290746181106925 -p 10000 -r guest -cpn homo_lr_1 -o examples/federatedml-1.x-examples/homo_logistic_regression/predict
控制台输出:

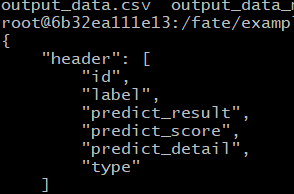
进入目录可以看到两个文件
![]()
output_data.csv:输出csv的数据;
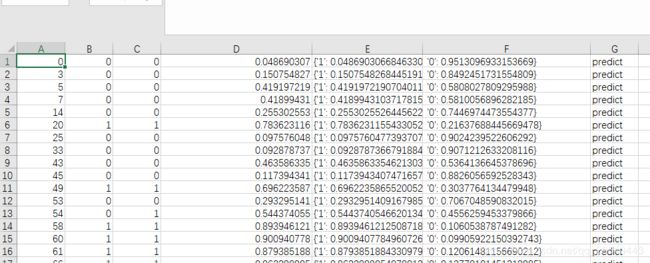
output_data_meta.json:输出数据的表头字段
5.2 获取host所有预测结果
host的操作只需要修改role跟相对的partyid即可
6.总结
预测的操作与训练相似,上面的步骤只编辑一个预测配置文件即可,其实按照我的体验来说,dsl文件也是可以更改自定义的,不一定用它的默认的配置,只要不跟训练对应模型的冲突就行。