DeepDive自动化信息抽取---全网首发DeepDive偷工减料超速部署方式
文章目录
- 1. DeepDive
- 1.1 系统架构
- 2. 部署DeepDive
- 2.1 环境准备
- 2.2 工具人偷工减料超速部署方式
- 2.2.1 下载相关文件
- 2.2.2 部署
- 2.3 官方部署方式
- 2.3.1 下载解压
- 2.3.2 安装
- 参考资料
1. DeepDive
DeepDive (http://deepdive.stanford.edu/) 是斯坦福大学开发的信息抽取系统,能处理文本、表格、图表、图片等多种格式的无结构数据,从中抽取结构化的信息。系统集成了文件分析、信息提取、信息整合、概率预测等功能。Deepdive的主要应用是特定领域的信息抽取,系统构建至今,已在交通、考古、地理、医疗等多个领域的项目实践中取得了良好的效果;在开放领域的应用,如TAC-KBP竞赛、维基百科的infobox信息自动增补等项目中也有不错的表现。
开源地址:https://github.com/HazyResearch/deepdive
本文用的支持中文的deepdive来自于http://www.openkg.cn/dataset/cn-deepdive,修改了自然语言处理的model包,使它支持中文。
1.1 系统架构
DeepDive的系统架构如下图所示,大致分为数据处理、数据标注、学习推理和交互迭代四个流程:

基于DeepDive的系统可以被没有机器学习经验的用户使用包括古生物学、基因学等。DeepDive是一个使用机器学习算法的训练系统来减少各种形式的噪音和不确定性,通过Mindtagger接口、基于规则的丰富的结构化领域的知识让用户能够在较低的反馈下完成系统训练的工作。DeepDive是要让没有机器学习实践的专家们也能使用它,它的一个关键的技术创新包括解决大范围的概率统计推断问题。它和传统的系统几个不一样的地方在于:
- DeepDive要求开发者思考特征而不是算法,而其他机器学习系统要求开发者思考聚类算法、分类算法的使用等,而DeepDive基于联合推理的算法让用户只需要关心信号或者特征本身。
- DeepDive系统能够获得更高的质量:PaleoDeepDive在科学领域知识抽取能力和实体关系抽取能力上比人类更胜一筹。
- DeepDive很明确的知道数据经常有噪声和误差:名字被误拼、自然语言有多意或者人类自己犯错。通过考虑这些误差,DeepDive为每一个决断进行复杂的可能性计算,比如如果DeepDive告知可能性为0.9,那么证明事实为真的概率为90%。
- DeepDive可以把多种数据源作为数据的来源,如文档、网页、PDF、图表和表格。
- DeepDive允许特定领域的开发者使用简单的规则来影响学习的过程以提升结果的质量,DeepDive也考虑到用户的反馈来更正预测的准确度来更加精准的预测。
- DeepDive能够使用数据来立即学习。大部分的机器学习系统需要为每一次预测构建大量的训练,而许多DeepDive应用,尤其是早期,可以完全不需要训练数据。
- DeepDive的关键在于其可扩展性、优质的推理和学习引擎。在项目中应用到的技术包括部分商业和开源工具:MADlib、Impala(Oracle的一款产品产品)和底层工具如Hogwild,它们同时也被微软的Adam和其他主要的网络公司集成。
2. 部署DeepDive
官方已经提供的良好的部署教程http://deepdive.stanford.edu/installation,但是经过一轮踩坑跟看别人踩坑之后,作为区区一介工具人,肯定是不能忍受又要挂代理又要改脚本还要改系统环境变量,等等等略麻烦的操作,因此下面将演示两种部署方式,分别是工具人偷工减料超速部署方式以及官方部署方式,总有一种适合你。
2.1 环境准备
| 系统工具 | 版本 | 备注 |
|---|---|---|
| CentOS | 7 | |
| Docker | 18.09.4 | |
| Docker-compose | 1.23.2 | 参考:CentOS7安装Docker-compose推荐方案 |
2.2 工具人偷工减料超速部署方式
身处2020,有容器方式的环境不用偏要走二进制的路,那是不符合经济效率的,经过工具人一顿摸索,也就是对官方的install.sh部署脚本了解一波后,DeepDive支持docker+docker-compose的方式部署,具体相关文件如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bslUbtlj-1585127687960)(C:\Users\lps\Documents\myblog\deepdive\DeepDive.assets\image-20200325093108937.png)]
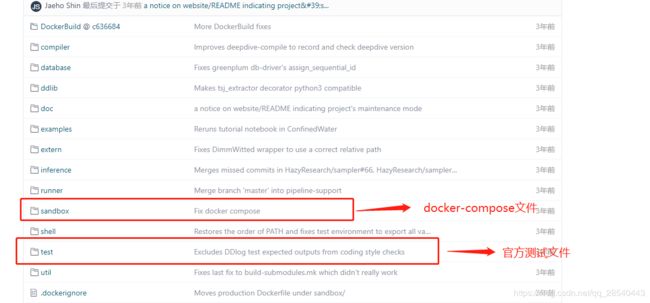
以上来自DeepDive的源码地址https://github.com/HazyResearch/deepdive
我们只需要上面红色框框圈住的两个文件夹即可。
2.2.1 下载相关文件
下载上面的sandbox跟test两个文件夹,就两条路
- 下载全部源码,嫌弃下载慢的话,参考以下博客如何快速clone github代码库
- 只下载这两个文件夹
 工具人演示一下怎么从github.com上面只下载单文件夹
工具人演示一下怎么从github.com上面只下载单文件夹
-
以
sandbox为例,GitHub的文件具体路径为:https://github.com/HazyResearch/deepdive/tree/master/sandbox -
工具人私藏n年github小工具今天终于得见天日!国内有人clone一波的专门下载github单文件的在线工具:http://zhoudaxiaa.gitee.io/downgit
-
打开downgit之后,复制github上面文件/文件夹路径
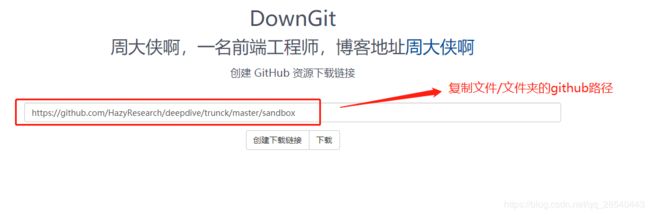
4. 有仔细看的大佬肯定发现,工具人你downgit上面的路径跟github的路径有差别!是的,差别在于原本的~/tree/~
改成了~/trunck~/,所有丢这里的github地址都这样改就对了。
- 然后就点击创建下载链接或者下载就可了。
将sandbox跟test 文件夹放在同级目录
2.2.2 部署
进入~/sandbox 目录
可以看到里面就一个docker-compose文件
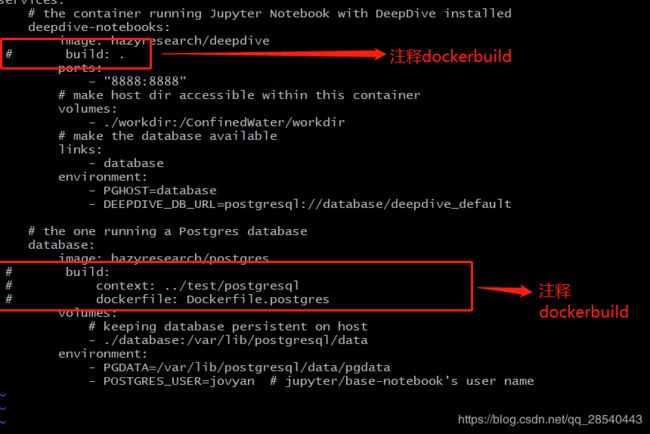
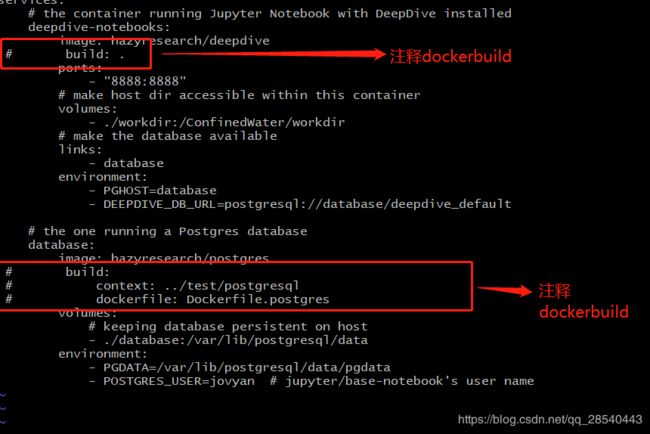
注释docker镜像构建脚本,直接从dockerhub下载(所谓工具人偷工减料超速部署的核心)
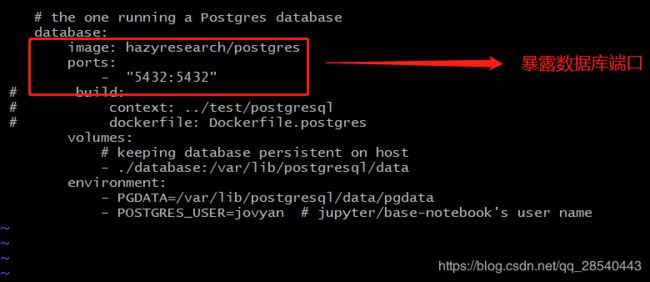
暴露数据库端口
当前目录执行以下命令:
docker-compose up -d
执行完成后,循例 docker ps |grep deepdive检查容器是否正常启动中。
![]()
访问http://host:8888进入jupyter
2.3 官方部署方式
2.3.1 下载解压
支持中文的Deepdive下载地址:
github上的官方下载地址:
https://github.com/HazyResearch/deepdive/releases
openkg.cn上的下载地址(百度网盘的形式,也慢哪,不过可以用速盘下载):
http://openkg.cn/tool/cn-deepdive
速盘下载地址(用这个解析百度云盘下载地址,会快很多):
https://www.speedpan.com
mkdir /home/deepdive && cd deepdive
unzip CNdeepdive.zip
解压后目录结构如下:
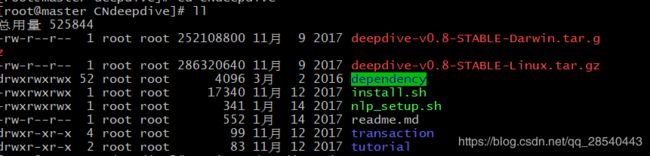
2.3.2 安装
在~/CNdeepdive目录执行部署
./install.sh
先删除以下文件
rm deepdive-v0.8-STABLE-Darwin.tar.gz && rm deepdive-v0.8-STABLE-Linux.tar.gz
然后重新执行 ./install.sh
控制台出现以下提示,按照提示选择如下,
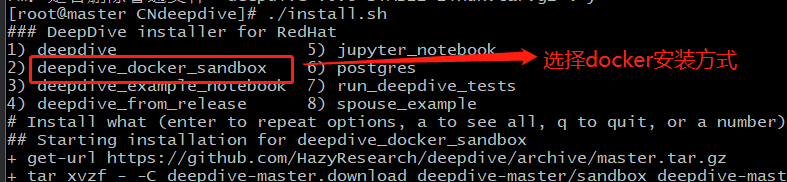
这里我们选择docker的方式,按照install.sh的逻辑会去下载对应github仓库的源码
https://github.com/HazyResearch/deepdive/
由于最近github尤其地慢,所以建议参考以下博客如何快速clone github代码库 ,然后修改install.sh,将原本的github.com地址改成gitee地址
然后等待部署成功就行。
参考资料
http://deepdive.stanford.edu/installation