大数据告诉我基金定投日应该设置在1、2号(附代码)
小小的声明
这个结果是我从1991年-2018年的上证、沪深的股票数据分析得来,主要用于学习交流。入市有风险,投资需谨慎。
统计思路
-
获取数据
上海证券交易所A股股票日线数据,1095支股票,时间区间为 1999.12.09 至 2016.06.08,前复权,剔除假期休市
深证证券交易所A股股票日线数据,1766支股票,时间区间为 1999.12.09 至 2016.06.08,前复权,剔除假期休市 -
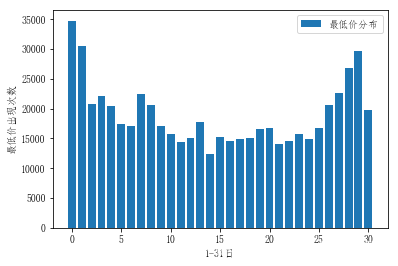
对每个月的最低开盘价进行统计,取出当月最低价的日期
-
将日期中的天数取出来,用一个长度31的数组进行累计计算
代码
- 先导入必要的包,定义常量
import numpy as np
import pandas as pd
import os
import matplotlib.pyplot as plt
from datetime import datetime
# 定义股票文件数据的文件夹路径
STOCK_LIST_PATH = 'stocklistdata'
# 定义累计天数的数组
COUNT_DAY = [0] * 32
- 读取和加载文件
def read_stock_list(stocklistpath):
return os.listdir(stocklistpath)
def read_stock_data_from_csv(filepath):
# 第二列是日期,第四列是开盘价,我们数据分析只用到这两列
return np.loadtxt(filepath, usecols=[2, 4], encoding='gbk', dtype=np.str, delimiter=',')
- 核心处理逻辑
def dealwith_one(filepath):
# 根据文件路径把数据读进来
datas = read_stock_data_from_csv(filepath)
# 删除表头
datas = np.delete(datas,0,axis=0)
# 转换成dataframe类型容易计算
df = pd.DataFrame(datas)
#第0列的字符串转成日期时间类型,方便使用dataframe的API进行操作
df[0] = pd.to_datetime(df[0])
# 新增一列,就是把第0列的日期复制的第2列,为了方便后面的统计
df[2] = datas[:,0]
# 把第0列设置为时间索引
df = df.set_index(0)
# 对数据重采样,取出每个月的最小值并去除nan的行
# 这个时候第2列的日期是不准确的,并不是对应最低价的那一天,所以只有月份是有效的
min_df = df.resample('M').min().dropna(axis=0,how='any')
# 转换为list
min_day_old = min_df.values
# 把时间和数据取出来跟当月的数据作比较,如果相等就把当天的日期取出来,对日期进行累计
for data, date in min_day_old:
dt = datetime.strptime(date, "%Y-%m-%d")
values = df[str(dt.year)+'-'+str(dt.month)].values
monthall = df[str(dt.year)+'-'+str(dt.month)].values[:,0]
for i,x in enumerate(monthall):
if x == data:
dt2 = datetime.strptime(values[i][1], "%Y-%m-%d")
COUNT_DAY[dt2.day] += 1
- 最后运行得结果
for f in read_stock_list(STOCK_LIST_PATH):
dealwith_one(STOCK_LIST_PATH + '/'+f)
count_day.pop(0)
- 最后看看结果
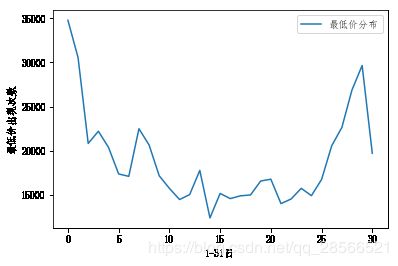
很明显1号2号最低价出现的次数最多,其次是月底28号。
用直方图来看看