机器学习:非监督学习
文章目录
- 机器学习:非监督学习
- 聚类Clustering
- Kmean聚类
- 层次聚类 (Hierarchical Clustering, HC)
- 单连接层次聚类(single link)
- 全连接层次聚类(complete link)
- 组平均层次聚类(complete link)
- 离差平方和法(ward's method)
- 密度聚类 (Density-based clustering, DBSCAN)
- 高斯混合模型聚类(GMM)
- 几种聚类比较
机器学习:非监督学习
机器学习分为两种:监督学习和非监督学习。常见的非监督学习包括聚类(clustering)、主成分分析(principle component analysis)和独立成分分析(independent component analysis)等。
聚类Clustering
Kmean聚类
Kmean聚类是最基本的聚类算法,也是最常用的聚类算法之一,在了解该方法前,我们可以通过此处亲自尝试聚类的可视化操作,这对于我们了解K-均值聚类的作用非常有用。
在Kmean算法中:
- step1:首先选择K个随机的质心(簇的数量)(pick);
- step2:根据样本点距各个质心的距离,将每一个样本点划分到相应的簇(assign);
- step3:重新计算每个簇的质心,根据新的质心再次划分样本点(optimize);
- step4:重复step2和step3,直至簇不再发生变化或者达到最大的迭代次数。
由此可知,我们需要考虑距离度量和目标函数。Kmean采用误差平方和作为聚类的目标函数,两次运行K均值产生的两个不同的簇集,我们更喜欢误差平方和最小的那个。 S S E = ∑ i = 1 K ∑ x ∈ C i d i s t ( c i , x ) 2 SSE=\sum_{i=1}^K\sum_{x\in C_i}dist(c_i, x)^2 SSE=i=1∑Kx∈Ci∑dist(ci,x)2K表示K个质心,ci表示第几个中心,dist表示的是欧几里得距离。

Understanding K-means Clustering in Machine Learning介绍了sklearn中Kmean算法的使用,此处不再详细说明。也可以参考官方文档。
不难发现,Kmean算法比较重要的一点就是选择K,即选择簇的数量n_clusters。我们可以根据实际需要,数据的分布进行适当的选择,也可以通过指标—轮廓系数进行选择,除此之外,我们还有多种方法可以选择K。
第二个需要选择的参数是max_iter,默认为300。
Kmean的优点:
K-Means 的优势在于速度快,因为我们真正在做的是计算点和组中心之间的距离:非常少的计算!因此它具有线性复杂度 O(n)。
Kmean的局限:
- Kmean的表现完全取决于初始质心,初始质心设置不当会导致完全不同的结果。可以通过设置n_init这一参数控制算法初始化的次数。
- K值需要预先给定,属于预先知识,很多情况下K值的估计是非常困难的,对于可以确定K值不会太大但不明确精确的K值的场景,可以进行迭代运算,然后找出Cost Function最小时所对应的K值,这个值往往能较好的描述有多少个簇类。
- K均值算法并不是很所有的数据类型。它不能处理非球形簇、不同尺寸和不同密度的簇;
- Kmean对于异常值十分敏感,这种情况下,离群点检测和删除有很大的帮助。
对于Kmean的进一步使用可以参考我的另一篇博客:电影评分的 k 均值聚类
事实上,Kmean对于如图所示的聚类非常有效,尤其是当预先知道聚类的数量时:

但是如果是下面的分布呢?K-均值聚类算法并不能很好的分理出不同的簇。


这就是K-均值聚类中按照到质心距离定义类的弊端,这使得K-均值聚类方法总是试图寻找高维领域呈圆形、球形或者超球面形的类。同样的,K-mean聚类也不能分离月牙形状的类:


层次聚类 (Hierarchical Clustering, HC)
对于上面展示的一些K-mean难以分离的数据集,层次聚类和密度聚类可以起到很好的作用,我们先来看看层次聚类。
层次聚类(Hierarchical Clustering)是聚类算法的一种,通过计算不同类别的相似度类创建一个有层次的嵌套的树。
从上图我们可以看出层次聚类的一般步骤:
- (初始化)把每个样本归为一类,计算每两个类之间的距离,也就是样本与样本之间的相似度;
- 寻找各个类之间最近的两个类,把他们归为一类(这样类的总数就少了一个);
- 重新计算新生成的这个类与各个旧类之间的相似度;
- 重复2和3直到所有样本点都归为一类,结束。
最后由下而上生成的树我们称之为系统树图(dendrogram)。根据我们设定好的聚类的数量,系统树图将由上而下切割这棵树,将其划分成我们需要的聚类。
注意到,根据衡量类间相似度的距离度量,层次聚类可分成三种方法:
单连接层次聚类(single link)
单连接聚类法关注的是两类间的最短距离,然后进行比较,距离最短的两个类会被归为一类;
问题:可能会产生狭长的类,然而大部分情况下想要的是比较紧凑的类
又叫做 nearest-neighbor ,就是取两个类中距离最近的两个样本的距离作为这两个集合的距离。这种计算方式容易造成一种叫做 Chaining 的效果,两个 cluster 明明从“大局”上离得比较远,但是由于其中个别的点距离比较近就被合并了,并且这样合并之后 Chaining 效应会进一步扩大,最后会得到比较松散的 cluster 。

我们看一下K-mean聚类和单连接层次聚类的效果:

全连接层次聚类(complete link)
全连接层次聚类的运作模式与单连接层次聚类十分相似,全连接聚类法关注的是两个类中两点之间的最远距离,并将其定义为两个类的距离。
Complete Linkage的计算方法与Single Linkage相反,将两个组合数据点中距离最远的两个数据点间的距离作为这两个组合数据点的距离。Complete Linkage的问题也与Single Linkage相反,两个不相似的组合数据点可能由于其中的极端值距离较远而无法组合在一起。
这样的聚类方法会使得产生的类比较紧凑。
组平均层次聚类(complete link)
计算任意两类中任意两点之间的距离,取平均值后作为两类之间的距离。
Average Linkage的计算方法是计算两个组合数据点中的每个数据点与其他所有数据点的距离。将所有距离的均值作为两个组合数据点间的距离。这种方法计算量比较大,但结果比前两种方法更合理。
离差平方和法(ward’s method)
离差平方和法计算两类间的距离的方法是:首先找出两类中所有点的中心点(所有点之间的平均位置),计算所有点与中心点之间的距离平方和,然后分别减去类中的变量距各自中心点的距离平方和
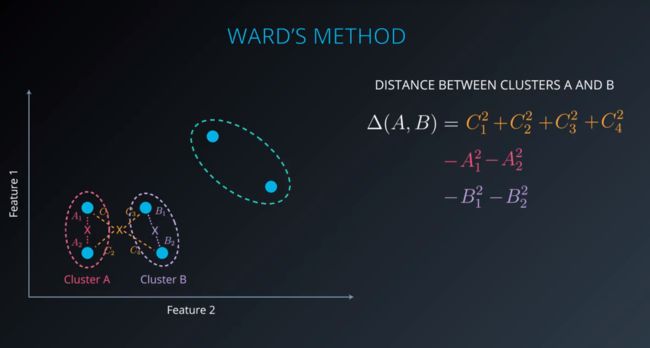
上述提到的几种层次聚类方法中,除单连接层次聚类外,可以统称为Agglomerative Hierarchical Clustering,AHC 凝聚层次聚类算法。这几种方法均是自下而上生成系统树图,然后根据需求进行切割。
scikit-learn框架中提供了非常方便的接口供我们使用,官方文档。

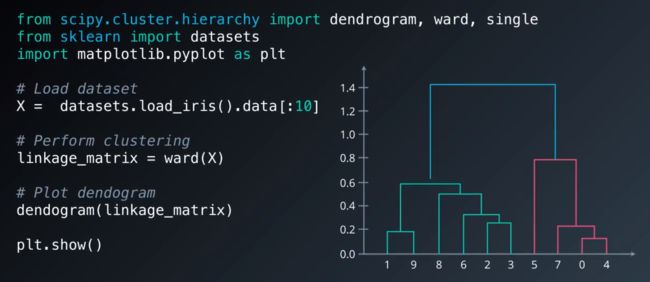
利用scipy绘制系统树图
最后,我们讨论一下层次聚类的优缺点:
优点:
- 层次聚类的结果描绘了数据间的层次关系;
- 聚类结构可视化;
- 非常适用于数据内部具有层次关系的数据集,例如进化生物学
缺点:
- 对噪声和离群值很敏感,所有提前清理数据集很有必要;
- 计算量大 O ( N 2 ) O(N^2) O(N2),不适合处理大规模数据集。
密度聚类 (Density-based clustering, DBSCAN)
我们先来看一下DBSCAN是怎么运作的:
可以看出,密度聚类与我们之前提到的聚类方法都有明显的差异,差异表现在不是所有的点都是类的一部分,DBSCAN把这些点标记成噪声(离群值),这也说明DBSCAN在处理具有噪声的数据集方面作用非常大。这是一个可视化DBSCAN的网址,在这里,我们可以任意更改参数并查看它在各种数据集上的工作方式。
理解DBSCAN的工作过程前,我们首先了解几个定义:
首先是密度的定义:事先给定半径r,数据集中点a的密度,要通过落入以点a为中心以r为半径的圆内点的计数(包括点a本身)来估计。
按照密度的定义,DBSCAN需要确定两个主要的参数,一是半径epsilon, 二是最小样本点minPoints。
DBSCAN将样本集中的点划分成以下三类:
-
核心点:在半径r区域内,含有超过MinPts数目(最小数目)的点,称为核心点;
-
边界点:在半径r区域内,点的数量小于MinPts数目,但是是核心点的直接邻居;
-
噪声点:既不是核心点也不是边界点的点
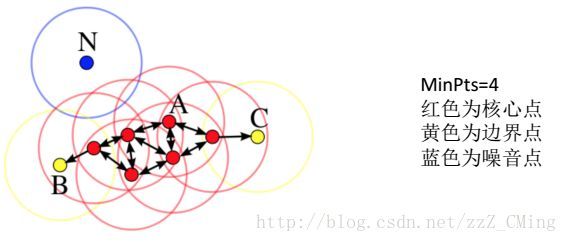
依照上图以及三种点的定义,可以得到:噪声点是不会被聚类纳入的点,边界点与核心点组成聚类的“簇”。 -
直接密度可达: 设 x , y ∈ X x,y\in X x,y∈X,若满足 y ∈ N ϵ ( q ) y \in N_{\epsilon }(q) y∈Nϵ(q)且 ∣ N ϵ ( q ) ∣ ≥ M i n P t s |N_{\epsilon }(q)|\geq MinPts ∣Nϵ(q)∣≥MinPts,则称 y y y从 x x x直接密度可达。
-
密度可达: 假设存在一串点 p 1 , p 2 , . . . , p n , p 1 = q , p n = p p_{1},p_{2},...,p{n},p_{1}=q,p_{n}=p p1,p2,...,pn,p1=q,pn=p,使得 p i + 1 从 p i p_{i+1}从p_{i} pi+1从pi是直接密度可达的,那么就认为 p p p从 q q q密度可达。
-
密度相连: 假设存在点 o , p , q o,p,q o,p,q其中 p , q p,q p,q均从 o o o密度可达,那么 p p p, q q q密度相连。密度相连具有对称性。
-
类簇: 设非空集合 C ⊂ X C\subset X C⊂X,若满足: ∀ p , q , \forall p,q, ∀p,q,
(1) p ∈ C p\in C p∈C,且 q q q从 p p p密度可达,那么 q ∈ C q\in C q∈C。
(2) p p p和 q q q密度相连。
则称 C C C构成一个类簇。
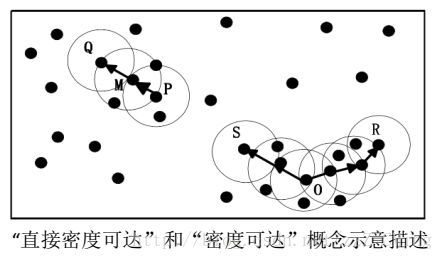
设MinPts=3,可以看出,M、P、O、R为核心点,S、Q为边界点;M是从P的“直接密度可达”,Q是从M的“直接密度可达”,那么Q是从P的“密度可达”,Q和P密度相连,所以M、P、Q三个中心点的邻域包含的点构成了一个类簇。
也就是说:核心点能够连通(密度可达),它们构成的以r为半径的圆形邻域相互连接或重叠,这些连通的核心点及其所处的邻域内的全部点构成一个簇。
DBSCAN的工作方式:
- DBSCAN通过检查数据集中每个点的r邻域来搜索簇,如果点p的r邻域包含多于MinPts个点,则创建一个以p为核心对象的簇;
- 然后, DBSCAN迭代的聚集从这些核心对象直接密度可达的对象,这个过程可能涉及一些密度可达簇的合并;
- 当没有新的带你添加到任何簇时,迭代过程结束。
和传统的K-Means算法相比,DBSCAN最大的不同就是不需要输入类别数k,当然它最大的优势是可以发现任意形状的聚类簇,而不是像K-Means,一般仅仅使用于凸的样本集聚类。同时它在聚类的同时还可以找出异常点,这点和BIRCH算法类似。
那么我们什么时候需要用DBSCAN来聚类呢?一般来说,如果数据集是稠密的,并且数据集不是凸的,那么用DBSCAN会比K-Means聚类效果好很多。如果数据集不是稠密的,则不推荐用DBSCAN来聚类。
DBSCAN的主要优点:
- 可以对任意形状的稠密数据集进行聚类,相对的,K-Means之类的聚类算法一般只适用于凸数据集。
- 可以在聚类的同时发现异常点,对数据集中的异常点不敏感。
- 聚类结果没有偏倚,相对的,K-Means之类的聚类算法初始值对聚类结果有很大影响。
DBSCAN的主要缺点:
4. 如果样本集的密度不均匀、聚类间距差相差很大时,聚类质量较差,这时用DBSCAN聚类一般不适合。
5. 如果样本集较大时,聚类收敛时间较长,此时可以对搜索最近邻时建立的KD树或者球树进行规模限制来改进。
6. 调参相对于传统的K-Means之类的聚类算法稍复杂,主要需要对距离阈值ϵ,邻域样本数阈值MinPts联合调参,不同的参数组合对最后的聚类效果有较大影响。
DBSCAN 参数的启发法:
-
1.很多小的聚类。超出了数据集的预期数量
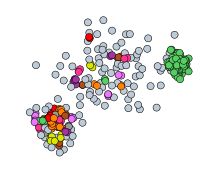
解决办法:同时增大epsilon和minPoints。 -
2.很多点聚成了同一类
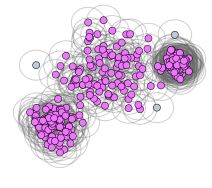
解决办法:降低epsilon,增大minPoints -
3.大部分/所有数据点都标记为噪点

解决办法:增大epsilon,降低minPoints
高斯混合模型聚类(GMM)
参考文章漫谈 Clustering (3): Gaussian Mixture Model
我们在此之前谈到的一系列聚类方法都属于硬聚类,即聚类结果把每一个数据点直接分配到了某一类中。事实上,接下来学习的高斯混合模型聚类与此不同,属于软聚类,学习到的不是一个单一的类别,而是给出这些数据点被assign到每个cluster的概率,因此又称为soft assignment。
Gaussian Mixture Model (GMM)。事实上,GMM 和 k-means 很像,不过 GMM 是学习出一些概率密度函数来(所以 GMM 除了用在 clustering 上之外,还经常被用于 density estimation ),简单地说,k-means 的结果是每个数据点被 assign 到其中某一个 cluster 了,而 GMM 则给出这些数据点被 assign 到每个 cluster 的概率,又称作 soft assignment 。
在GMM中,我们假设数据的分布服从混合高斯分布(Mixture Gaussian Distribution ),换句话说,数据可以被看做是由多个Gaussian Distribution中生成的,每一个Gaussian Distribution称为一个model,通过增加Model的个数,我们可以任意地逼近任何连续的概率密度分布。
每个 GMM 由 K K K 个 Gaussian 分布组成,每个 Gaussian 称为一个“Component”,这些 Component 线性加成在一起就组成了 GMM 的概率密度函数:
p ( x ) = ∑ k = 1 K p ( k ) ∣ p ( x ∣ k ) = ∑ k = 1 K π k N ( x ∣ μ k , σ k ) \displaystyle \begin{aligned} p(x) & =\sum_{k=1}^Kp(k)|p(x|k) \\ & =\sum_{k=1}^K\pi_k\mathcal{N}(x|\mu_k,\sigma_k) \end{aligned} p(x)=k=1∑Kp(k)∣p(x∣k)=k=1∑KπkN(x∣μk,σk)
假设我们有 N N N个数据点,假定它们是由GMM生成的,我们的工作就是根据这些数据去推断GMM的的概率分布,然后GMM的K个component就是我们寻找的K个cluster,这实际上就是去估计上式中的 π k , μ k , Σ k \pi_k,\mu_k,\Sigma_k πk,μk,Σk,因此这就转换成了参数估计的问题。
考虑到概率,又是参数估计,我们很自然地联想到极大似然估计,就是找到这样一组参数,使得它所确定的概率分布生成的这些点的数据点的概率最大。我们首先得到似然函数如下:
∏ i = 1 N p ( x i ) \prod_{i=1}^Np(x_i) i=1∏Np(xi)通常情况下,我们会将其转换成对数似然函数的形式:
∑ i = 1 N log p ( x i ) \sum_{i=1}^N\log p(x_i) i=1∑Nlogp(xi)
下一步就是将这个函数最大化(通常的做法是求导并令其导数等于0,然后求解方程),亦即找到这样一组参数值,它让似然函数取得最大值,我们就认为这是最合适的参数,这样就完成了参数估计的过程。
下面我们来看一看GMM的对数似然函数:
∑ i = 1 N log { ∑ k = 1 K π k N ( x ∣ μ k , σ k ) } \sum_{i=1}^N \log \left\{\sum_{k=1}^K\pi_k\mathcal{N}(x|\mu_k,\sigma_k)\right\} i=1∑Nlog{k=1∑KπkN(x∣μk,σk)}
实际上,我们没法直接用求导解方程的思想求解上述函数的最大值。GMM通常采用期望最大法(EM) 来解决这一问题。EM算法的详细推导和证明见(EM算法)The EM Algorithm,我们看看GMM中是如何使用EM算法的:
- 给定k个分布的 μ k , σ k \mu_k,\sigma_k μk,σk初始值(为每个高斯选择随机均值和随机方差);
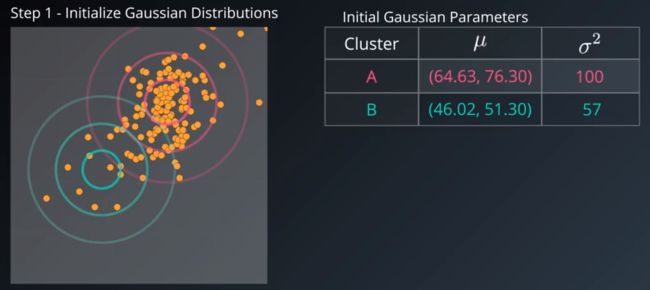
- (soft-cluster the data points , “Expectation” step)
估计数据由每个 Component 生成的概率(并不是每个 Component 被选中的概率):对于每个数据 x i x_i xi 来说,它由第 k k k 个 Component 生成的概率为
γ ( i , k ) = π k N ( x ∣ μ k , σ k ) ∑ i = 1 K π j N ( x ∣ μ j , σ j ) \gamma(i,k)=\frac{\pi_k\mathcal{N}(x|\mu_k,\sigma_k)}{\sum_{i=1}^K\pi_j\mathcal{N}(x|\mu_j,\sigma_j)} γ(i,k)=∑i=1KπjN(x∣μj,σj)πkN(x∣μk,σk)

- (re-estimate parameters of Gaussians - “Maximization” step)
估计每个 Component 的参数:现在我们假设上一步中得到的 γ ( i , k ) \gamma(i, k) γ(i,k) 就是正确的“数据 x i x_i xi 由 Component k k k 生成的概率”,亦可以当做该 Component 在生成这个数据上所做的贡献,或者说,我们可以看作 x i x_i xi 这个值其中有 γ ( i , k ) ⋅ x i \gamma(i, k) · x_i γ(i,k)⋅xi 的部分是由 Component k k k 所生成的。集中考虑所有的数据点,现在实际上可以看作 Component 生成了 γ ( 1 , k ) ⋅ x 1 , … , γ ( N , k ) ⋅ x N \gamma(1, k)·x_1, \ldots, \gamma(N, k)·x_N γ(1,k)⋅x1,…,γ(N,k)⋅xN 这些点。由于每个 Component 都是一个标准的 Gaussian 分布,可以很容易分布求出最大似然所对应的参数值:
μ k = 1 N k ∑ i = 1 N γ ( i , k ) ⋅ x i \mu_k=\frac{1}{N_k}\sum_{i=1}^{N}\gamma(i, k) · x_i μk=Nk1i=1∑Nγ(i,k)⋅xi σ k = 1 N k ∑ i = 1 N γ ( i , k ) ⋅ ( x i − μ k ) ⋅ ( x i − μ k ) T \sigma_k = \frac{1}{N_k}\sum_{i=1}^{N}\gamma(i, k) · (x_i-\mu_k)·(x_i-\mu_k)^T σk=Nk1i=1∑Nγ(i,k)⋅(xi−μk)⋅(xi−μk)T其中, N k = ∑ i = 1 N γ ( i , k ) N_k=\sum_{i=1}^N \gamma(i, k) Nk=∑i=1Nγ(i,k),并且 π k \pi_k πk 也顺理成章地可以估计为 N k / N N_k/N Nk/N.


- 重复迭代前面两步,直到似然函数的值收敛为止。
关于GMM的使用,可以看我的另一个项目机器学习工程师 — Udacity 创建客户细分中的聚类部分。
几种聚类比较
简单总结:
- GMM属于软聚类的方法,能够给出样本数据属于某一个类别的概率,然而其他的聚类方法均属于硬聚类;
- K-mean聚类和层次聚类对于异常值十分敏感,因此需要提前进行异常值的消除;
- DBSCAN适用于具有异常值的数据集,常常用来进行异常值的检测,不适用于密度不均匀的样本集;
- K-mean依赖于初始值和K,但是收敛速度快;
- 层次聚类可以帮助我们发现数据间的层次关系;