UNIX再学习 -- 死磕内存管理
一个内存管理 C 语言部分讲,UNIX部分讲,Linux部分还讲,死磕到底!!
一、mallc/free简化实现
上篇文章已经讲解了动态内存分配/释放函数,参看:UNIX再学习 – 内存管理下面来讲一下,它的自定义函数实现,其中有三个部分:
1、内存控制块
内存控制块用于管理每次分配的内存块,记录该内存块的字节大小、忙闲状态,以及相关内存控制块的首地址。代码如下所示
typedef struct mem_control_block
{
size_t size; //本块大小
bool free; //空闲状态
struct mem_control_block *next; //后块指针
}MCB;
MCB *g_top = NULL; //栈顶指针讲解
上述代码中:定义了一个结构体 mem_control_block,别名为 MCB。
定义结构体成员 size,用于保存申请分配的内存块的字节数。
定义结构体成员 free,用于保存该内存是否被分配给进程。
定义结构体成员 next,用于保存下一个链表节点的地址。
定义链表栈的栈顶指针 g_top。
2、分配内存
遍历内存控制块链表,若有大小足够的空闲块,则重用该块,否则分配新的足量内存并将其控制块压入链表栈。代码如下所示:
void* my_malloc (size_t size)
{
MCB* mcb;
for (mcb = g_top; mcb; mcb = mcb->next)
if (mcb->free && mcb->size >= size)
break;
if (! mcb)
{
mcb = sbrk (sizeof (MCB) + size);
if (mcb == (void*)-1)
return NULL;
mcb->size = size;
mcb->next = g_top;
g_top = mcb;
}
mcb->free = false;
return mcb + 1;
}讲解
上述代码中,以下代码:void* my_malloc (size_t size)上述代码中,以下代码:
MCB* mcb;
for (mcb = g_top; mcb; mcb = mcb->next)
if (mcb->free && mcb->size >= size)
break;if (mcb->free && mcb->size >= size)
break;上述代码中,以下代码:
if (! mcb)
{
mcb = sbrk (sizeof (MCB) + size);
if (mcb == (void*)-1)
return NULL;
mcb->size = size;
mcb->next = g_top;
g_top = mcb;
} mcb = sbrk (sizeof (MCB) + size);
if (mcb == (void*)-1)
return NULL;上述代码中,以下代码:
mcb->free = false;上述代码中,以下代码:
return mcb + 1;3、释放内存
先将被释放内存块标记为空闲,然后遍历内存控制块链表,将靠近栈顶的连续空闲块及其内存控制块一并释放。代码如下所示
void my_free (void* ptr)
{
if (ptr)
{
MCB* mcb = (MCB*)ptr - 1;
mcb->free = true;
for (mcb = g_top; mcb->next; mcb = mcb->next)
if (! mcb->free)
break;
if (mcb->free)
{
g_top = mcb->next;
brk (mcb);
}
else if (mcb != g_top)
{
g_top = mcb;
brk ((void*)mcb + sizeof (MCB) + mcb->size);
}
}
}void my_free (void* ptr)上述代码中,以下代码:
if (ptr) 上述代码中,以下代码:
MCB* mcb = (MCB*)ptr - 1;上述代码中,以下代码:
mcb->free = true;上述代码中,以下代码:
for (mcb = g_top; mcb->next; mcb = mcb->next)
if (! mcb->free)
break; if (! mcb->free)
break;上述代码中,以下代码:
if (mcb->free)
{
g_top = mcb->next;
brk (mcb);
}上述代码中,以下代码:
else if (mcb != g_top)
{
g_top = mcb;
brk ((void*)mcb + sizeof (MCB) + mcb->size);
}4、完整代码
#include
#include
#include
//内存控制块
typedef struct mem_control_block
{
size_t size; // 本块大小
bool free; // 空闲标志
struct mem_control_block* next; // 后块指针
} MCB;
//单向链表栈
MCB* g_top = NULL;//栈顶指针
//malloc 函数的实现
void* my_malloc (size_t size)
{
MCB* mcb;
for (mcb = g_top; mcb; mcb = mcb->next)
if (mcb->free && mcb->size >= size)
break;
if (! mcb)
{
mcb = sbrk (sizeof (MCB) + size);
if (mcb == (void*)-1)
return NULL;
mcb->size = size;
mcb->next = g_top;
g_top = mcb;
}
mcb->free = false;
return mcb + 1;
}
//free 函数的实现
void my_free (void* ptr)
{
if (ptr)
{
MCB* mcb = (MCB*)ptr - 1;
mcb->free = true;
for (mcb = g_top; mcb->next; mcb = mcb->next)
if (! mcb->free)
break;
if (mcb->free)
{
g_top = mcb->next;
brk (mcb);
}
else if (mcb != g_top)
{
g_top = mcb;
brk ((void*)mcb + sizeof (MCB) + mcb->size);
}
}
}
int main()
{
int *p = my_malloc(sizeof(int));
*p = 10;
printf("%d\n", *p);
my_free(p);
return 0;
}
输出结果:
10 扩展部分
参看:Linux实验心得——内存管理参看:malloc的实现原理学习(2)
二、malloc 和 sbrk 关系
1、首先我想讲一个函数 malloc_usable_size
参看:MALLOC_USABLE_SIZE 讲解
#include
size_t malloc_usable_size (void *ptr);
1 这个函数返回调用 malloc 后实际分配的可用内存的大小,如果ptr 为NULL,则为 0
举个例子
#include
#include
int alloc_memory (char *p, int size)
{
p = (char*)malloc (size);
if (NULL == p)
perror ("malloc"), exit (1);
printf ("%d\n", malloc_usable_size (p));
}
int main (void)
{
char *p = NULL;
alloc_memory (p, 0);
alloc_memory (p, 10);
alloc_memory (p, 20);
return 0;
} 2、分析 malloc 和 sbrk
通过上面 malloc 函数的简化实现,可以看到,当内存控制块链表中找不到大小足够的空闲块进行分配时,分配新的足量内存并将其控制块压入链表栈。其中,以下代码: mcb = sbrk (sizeof (MCB) + size);
if (mcb == (void*)-1)
return NULL;sbrk 实现虚拟内存到内存的映射,是系统调用,是Unix/Linux系统提供的接口(只能在Unix/Linux系统下才能用的)。而malloc是标准c函数在,所以在Unix/Linux和windows下都能用。
在Unix/Linux下,malloc 底层实现就是通过系统调用sbrk实现的;在windows下malloc则是通过调用windows系统提供的接口实现。
描述:
这部分,在 UNIX环境高级编程第 7 章,也有讲到。虽然 sbrk 可以扩充或缩小进程的存储空间,但是大多数 malloc 和 free 的实现都不减小进程的存储空间。释放的空间可共以后再分配,但将它们保持在 malloc 池中而不返回给内核。
大多数实现所分配的存储空间比所要求的要稍大一些,额外的空间用来记录管理信息 – 分配块的长度、指向下一个分配块的指针等。这就意味着,如果超过一个已分配区的尾端或者在已分配区起始位置之前进行写操作,则会改写另一块管理记录信息。这种类型的错误是灾难性的,但是因为这种错误不会很快就暴露出来,所以也就很难发现。
举个例子说明:
#include
#include
#include
int main (void)
{
void *cur = sbrk (0);
printf ("cur 1 = %p\n", cur);
void *ptr = malloc (100);
void *ptr1 = malloc (100);
cur = sbrk (0);
printf ("cur 2 = %p\n", cur);
printf ("ptr = %p\n", ptr);
printf ("ptr1 = %p\n", ptr1);
free (ptr);
free (ptr1);
cur = sbrk (0);
printf ("cur 3 = %p\n", cur);
printf ("ptr = %p\n", ptr);
printf ("ptr1 = %p\n", ptr1);
return 0;
}
输出结果:
cur 1 = 0x8f17000
cur 2 = 0x8f38000
ptr = 0x8f17008
ptr1 = 0x8f17070
cur 3 = 0x8f38000
ptr = 0x8f17008
ptr1 = 0x8f17070 示例总结
参看:自己动手写malloc参看:UNIX再学习 – 内存管理
可以看出,malloc 所申请的空间的起始地址,第一次,比一开始的堆末尾地址向后移动了 8 个字节。第二次,后移了112个字节。这 8 个字节应该就是,用来记录管理信息的额外空间 – 分配块的长度、指向下一个分配块的指针等。而我们采用的是 8 字节对齐,申请 100 个字节,经过对齐,应为 104 个字节,再加上 8 个额外空间,即 112 个字节。而堆尾地址变为 0x8f38000,增加了 0x21000,十六进制 0x21000 转换成 十进制为 135168 = 33 * 4096 上面讲到当前系统内存页的大小为 4Kb。malloc 申请内存,系统会一次映射 33 个内存页。
三、虚拟内存机制
参看:linux内存管理1、为什么需要使用虚拟内存
大家都知道,进程需要使用的代码和数据都放在内存中,比放在外存中要快很多。问题是内存空间太小了,不能满足进程的需求,而且现在都是多进程,情况更加糟糕。所以提出了虚拟内存,使得每个进程用于3G的独立用户内存空间和共享的1G内核内存空间。(每个进程都有自己的页表,才使得3G用户空间的独立)这样进程运行的速度必然很快了。而且虚拟内存机制还解决了内存碎片和内存不连续的问题。为什么可以在有限的物理内存上达到这样的效果呢?
2、虚拟内存的实现机制
首先呢,提一个概念,交换空间(swap space),这个大家应该不陌生,在重装系统的时候,会让你选择磁盘分区,就比如说一个硬盘分几个部分去管理。其中就会分一部分磁盘空间用作交换,叫做swap space。其实就是一段临时存储空间,内存不够用的时候就用它了,虽然它也在磁盘中,但省去了很多的查找时间啊。当发生进程切换的时候,内存与交换空间就要发生数据交换一满足需求。所以啊,进程的切换消耗是很大的,这也说明了为什么自旋锁比信号量效率高的原因。
那么我们的程序里申请的内存的时候,linux内核其实只分配一个虚拟内存( 线性地址),并没有分配实际的物理内存。只有当程序真正使用这块内存时,才会分配物理内存。这就叫做延迟分配和请页机制。释放内存时,先释放线性区对应的物理内存,然后释放线性区;"请页机制"将物理内存的分配延后了,这样是充分利用了程序的局部性原来,节约内存空间,提高系统吞吐;就是说一个函数可能只在物理内存中呆了一会,用完了就被清除出去了,虽然在虚拟地址空间还在。(不过虚拟地址空间不是事实上的存储,所以只能说这个函数占据了一段虚拟地址空间,当你访问这段地址时,就会产生缺页处理,从交换区把对应的代码搬到物理内存上来)
3、物理内存与虚拟内存的布局
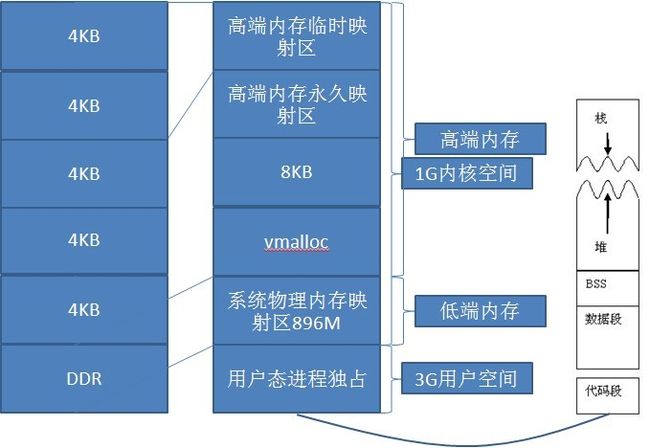
左边是物理地址分配,与实际的CPU相关。4KB的这些都是一些控制器所占有,比如lcdc sd卡,他们的寄存器地址就是这样定死的。但是呢,我们要访问这些寄存器的时候,还是不能直接用,要使用内存管理的规则,使用虚拟地址去访问它,所以在驱动等内核程序中需要使用虚拟地址访问寄存器。如果有人直接使用物理地址访问寄存器,那么唯一的解释就是没有开mmu。不过这样你的进程就没有4G内存可以用了。
物理地址分布:

这是偷的别人的图啦,物理地址有896M直接映射到虚拟地址的内存空间,这是一一对应的映射,只有起始地址不一样,偏移是一样的。这个大小大多是固定的,哪怕你的内存超过一个G,太小了就另外说了。注意:用户区的代码也是放在这段物理地址里面的,就是说物理地址可以进行二次映射。但不管怎么样,这段物理地址都是受内核管理。当你内存很大的时候,超过896M时,剩余的那些内存怎么办呢?这多出来的叫做高端内存,如果你使用vmalloc申请空间,就会在高端内存中分配,如果你使用kmalloc申请空间,就会在小于896的内存中分配。所以还是很讲究的啊!!如果你的程序需要使用高端内存,就要调用内核API来分配,所以高端内存并不是想用就能用的哦。不过通过系统把一些应用常住在高端内存到是个好注意。不过前提是你的内存灰常大啊。
为什么要这样做呢?先看看这里面放些什么?

虚拟地址分布:

关于0-3G用户空间内存的分布:

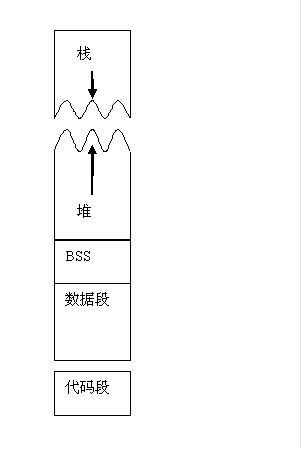
谈到段式分布,就要说说逻辑地址,线性地址与物理地址的关系:

linux通过段机制把逻辑地址转换为虚拟地址(就是线性地址),再通过页机制把虚拟地址转换为物理地址。所谓分段就是基址不同,偏移一样,比如说32位,一般程序里面都不会使用这么多的位,可以把前12位用作基址,后20位用作偏移,这样在特定段就可以只使用偏移寻址了。寻址很方便,不过linux页基址做的更好。
最后呢再说几个点:
1 线性地址空间:指linux系统中的虚拟地址空间。
2 cpu寻址是属于物理地址。所以在使用cpu寻址前要把地址转换好。
3 物理内存中的高端内存是DDR减去896M后多出来的那一段。虚拟地址里面的高端内存是指用于映射高端内存的虚拟地址空间。不过高端内存被映射到用户空间,那就是另外一回事了吧。
4 内核空间是可以访问用户空间的,级别高就是好啊。不过不是通过虚拟地址直接访问的。
四、总结
我有种预感,我在 CSND 写博客有点写不下去了,编辑器太烂了。初尝 Markdown 编辑器,字体超小,看着都伤眼睛。HTML 编译器,插入代码,各种字体冲突。美化文章布局上,就用去了很多时间。
CSND 博客故障处理,占用工作时间,也就算了。这个一直在用的编辑器这的让人头痛。