微信好友信息统计-图、词云和热图
文章目录
- 一、背景
- 二、效果展示
- 三、wordcloud
- 四、jieba
- 五、matplotlib
- 六、pyecharts
- 七、关键步骤
- 八、打包成exe时遇到的问题
- 九、demo下载
一、背景
上一篇文章我们讲解了微信机器人,主要使用了wxpy这个库,如果还不会登录机器人的话可以可以快速浏览上一篇文章,微信聊天机器人-存储好友分享消息。这篇文章我们继续使用wxpy统计微信账号好友信息。主要包括:好友信息词云、好友所在省份分布、城市分布、好友性别和好友地理位置热力图等
二、效果展示
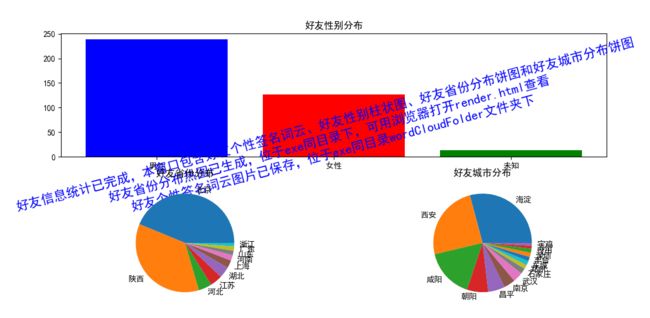
1、好友信息:男女比例柱状图、好友省份饼图、好友城市饼图
2、好友个性签名词云

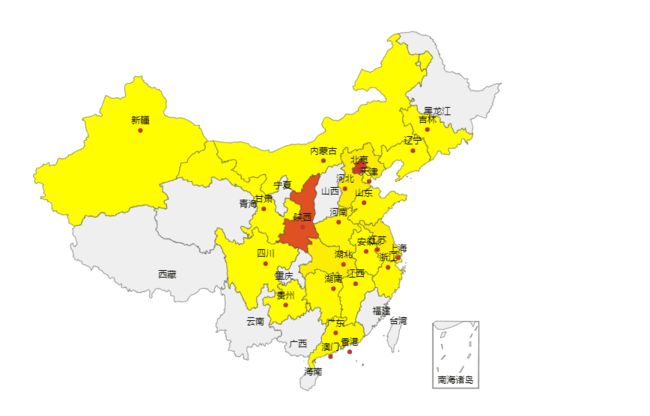
3、好友所在位置热力图
三、wordcloud
wordcloud是生成词云的包,使用起来也是比较简单
1、安装wordcloud包
pip install wordcloud
2、导入词云包
from wordcloud import WordCloud, ImageColorGenerator
3、构造WordCloud对象
wc = WordCloud(
background_color = p_background
, max_words = p_max_words #显示最大词数
, font_path = "msyh.ttf"
, min_font_size = p_min_font_size
, max_font_size = p_max_font_size
, width = p_width #图幅宽度
, height = p_height
, mask = cloud_mask
)
4、生成词云结果
result = wc.generate(cloud_text)
5、保存词云结果为图片
wordCloudFile = os.getcwd() + "\\wordCloud.png"
if os.path.exists(wordCloudFile) :
os.remove(wordCloudFile)
result.to_file(wordCloudFile)
四、jieba
jieba是一个分词工具,可以把已知文本串进行分词,分词的结果是一个列表,wordcloud正好需要这么一个列表
1、安装jieba包
pip install jieba
2、导入分词工具包
import jieba
3、添加建议词组,即不被分割的词组
jieba.suggest_freq(('微博'), True)
4、加载用户自定义词组
jieba.load_userdict(os.getcwd() + "\\jieba_user_dict.txt")
5、分词
segs = jieba.cut(text)
五、matplotlib
matplotlib是一个python图表包,包含各种图表控件,本文中主要使用了饼图和柱状图
1、安装matplotlib
pip install matplotlib
2、导入图表控件
import matplotlib.pyplot as plt
3、构造一个figure对象
```fig = plt.figure(num = bot.self.name + u’的好友签名词云’, figsize=(6.5, 6))``
4、添加plot
plt.plot()
plt.axis('off')
plt.title(bot.self.name + u"的好友个性签名词云")
plt.imshow(result)
5、为了解决乱码问题,需要在构造figure前设置下编码
plt.rcParams['font.sans-serif'] = ['SimHei']
6、显示
plt.show()
六、pyecharts
pyecharts是热力图包,需要在浏览器中查看
1、安装pyecharts包
pip install pyecharts
2、导入
from pyecharts import Map, Page
3、构造一个Map对象
friends_map = Map("微信好友全国分布图", width = 1200, height=600)
4、添加好友省份数据
friends_map.add(
""
, province_dict.keys()
, province_dict.values()
, is_label_show = True
, is_visualmap = True
, maptype='china'
, visual_range = [0, max(province_dict.values())]
, visual_text_color = 'red'
, visual_range_text = ['少', '多']
, visual_range_color = ['#FFFF00', '#D6292B'] # [黄,红]由低到高
)
5、渲染,会生成一个index.html文件在同目录下,使用浏览器打开即可
6、如果发现地图上没有数据,需要下载地图数据包
echarts-countries-pypkg 是全球国家地图,echarts-china-provinces-pypkg是中国省级地图, harts-china-cities-pypkg是中国城市地图
pip install echarts-countries-pypkg
pip install echarts-china-provinces-pypkg
pip install echarts-china-cities-pypkg
七、关键步骤
1、获取好友男女信息
#获取好友性别、省份
def generateInfo():
male = female = other = 0
for sex, count in friends_stat["sex"].items():
# 1代表MALE, 2代表FEMALE
if sex == 1:
male = count
print ("MALE %d" % count)
elif sex == 2:
female = count
print ("FEMALE %d" % count)
else :
other = count
print ("other %d" % count)
total = male + female + other
print ("男性朋友:%.2f%%" % (float(male) / total * 100))
print ("女性朋友:%.2f%%" % (float(female) / total * 100))
print ("其他:%.2f%%" % (float(other) / total * 100))
2、好友省份
province_dict = {}
friend_privince = []
for province, count in friends_stat["province"].items():
if province != "":
friend_privince.append([province, count])
province_dict[province] = count
、好友城市
friend_city = []
for city, count in friends_stat["city"].items():
if city != "":
friend_city.append([city, count])
4、签名数据清洗
fs = bot.friends()
for f in fs :
pattern = re.compile(r'[一-龥]+')
filterdata = re.findall(pattern, f.signature)
text = text + ''.join(filterdata)
八、打包成exe时遇到的问题
1、jieba包在打包成exe,运行时可能会报找不到dict.txt文件,因此导入jieba包时执行以下代码,并将dict.txt文件拷贝到exe目录下
import jieba
jieba.set_dictionary(".\dict.txt")
jieba.initialize()
或者看源码目录里的log.txt文件解决方案
2、wordcloud打包时,也会遇到stopwords文件缺失,解决办法是修改源码
wordcloud.py文件中30行代码修改
to :STOPWORDS = set(map(str.strip, open(os.path.join(os.path.dirname(sys.executable), 'stopwords')).readlines()))
from :STOPWORDS = set(map(str.strip, open(os.path.join(FILE, 'stopwords')).readlines()))
打包完毕,开发时需要还原
九、demo下载
需要完整源码的可以下载:微信好友信息统计-图、词云和热图
 |
 |
很重要–转载声明
-
本站文章无特别说明,皆为原创,版权所有,转载时请用链接的方式,给出原文出处。同时写上原作者:朝十晚八 or Twowords
-
如要转载,请原文转载,如在转载时修改本文,请事先告知,谢绝在转载时通过修改本文达到有利于转载者的目的。