分析Elasticsearch的Aggregation有感(一)
Elasticsearch除了全文检索之外,引以为傲的便是各种聚合算法,如kibana中最为常用的以时间轴的刻度为桶bucket进行统计、累加等聚合计算。

分析Elasticsearch的聚合统计为什么能做到实时响应?其实原理相当简tong单,主要依赖fielddata(内存常驻,逐渐被doc_values取代),将需要排序的字段记录事先排好序记录在内存中或保存在节点磁盘上;加上集群分布式计算能力,能做到聚合计算极快。
桶中桶的聚合计算则是Elasticsearch的噩梦,经常在不怎么大的数据量下出现OOM;Elasticsearch所有的计算都采用以下方式;
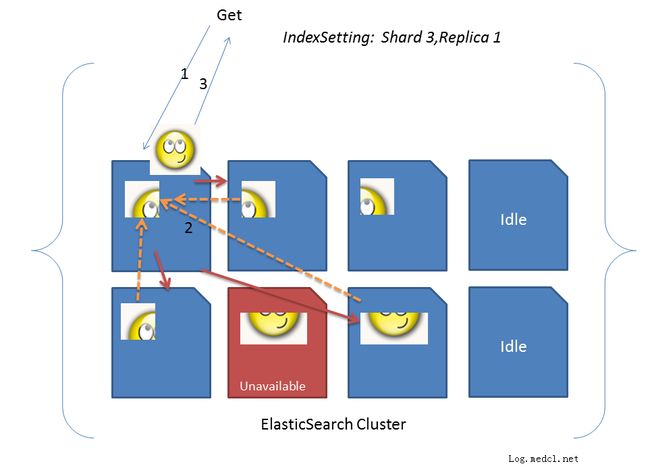
当请求发现集群中的任何一个节点,该节点必须负责将数据进行整理汇聚,再返回给客户端,也就是一个简单的节点上进行Map计算,在一个固定的节点上进行Reduces得到最终Map集合向客户端返回。
当进行桶中桶计算时,Elasticsearch将该过程只进行了简单拆分,分别计算出两个聚合的桶的结果集,再进行两个结果集的Join。
也就是Hadoop进行Join计算时的Redece端进行Join计算,这时所汇聚的数据量以及Join计算时K(k1-k2)所产生的新的键值急速膨胀,最终导致汇聚节点的OOM。

Elasticsearch当前始终坚持采用简单的查询发起节点负责数据汇聚,跟Elasticsearch及搜索引擎技术的特点有关,即保证TopN的检索效率,每个计算节点只返回各自的TopN,再由汇聚节点整合计算出TopN,这样节点向汇聚节点所传输的数据始终较小;这样设计带来的问题是,无法进行复杂的计算,如桶中桶,Any Join等这些其他类型的数据仓库所具备的功能。
当前解决这个问题的办法,首先能想到的就是与分布式计算引擎来结合,复杂的计算交给分布式计算引擎来完成,所以自然出现了Elasticsearch-Hadoop的连接组件。但尝试使用过Elasticsearch-Hadoop的人最终都放弃了,原因是当前Hadoop与Elasticsearch结合时,仅仅把Elasticsearch当前类似Txt类型的存储,进行计算时Hadoop的Map任务通过Elasticsearch-Hadoop提供InputFormat,只是简单通过Elasticsearch的Scroll对数据进行全量的读取。
这里我们测试过一般硬件配置配置(32核,128G内存,3*4TB硬盘,千兆网卡)组成的4节点集群,最大的Scroll性能只能到20W-30W条/s(1k每条记录);简单计算下,当需要分析10亿级别的数据时,光数据从Elasticsearch集群加载到Hadoop集群所需要的时间是多少。
所以只是将Elasticsearch当作普通存储来进行两个集群的结合显然不合适,如何发挥两个集群各种的计算特点来适应各种不同的计算需求,下面来看看我们的研究方向:
修改Elasticsearch的底层计算逻辑,在进行复杂计算时,不是采用简单的计算任务拆分,下发计算,再汇聚这样粗暴的方式,而是类似Hadoop上的优化,在进行第一层节点计算后,中间在穿插一层shuffle过程,将需要进行Join计算的Maps,进行相应的排序,迁移评估,再执行迁移,保证数据在节点间最小迁移的情况下,再在迁移后的节点上进行Join,再进行Reduce,是不是已经晕了。所以暂时我们也没有计算对这部分进行如此彻底的修改。
如何将Elastcicearch如何与Hadoop的有机结合,但不是如何提高scroll速度或Map任务直接对Lucese文件进行直接的IO等,将数据全量读取到Hadoop集群,而接下来的任何分析都与Elasticsearch没有任何关系的做法。
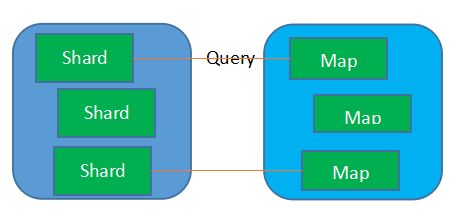
根据Elasticsearch数据shard的分布,设置Hadoop的Map任务,保持Map采用Local方式访问一个或多个分片,将Map操作的数据流控制在Local上。
publicList getSplits(JobContext job)throwsIOException {
// getshards splits
List originalSplits =ElasticserchCatShards(job);
// Get active servers
String[] servers = getActiveServersList(job);
if(servers ==null)
returnnull;
// reassign splits to active servers
List splits =newArrayList(originalSplits.size());
intnumSplits = originalSplits.size();
intcurrentServer = 0;
for(inti = 0; i < numSplits; i++, currentServer = i>getNextServer(currentServer, servers.length)){
String server = servers[currentServer]; // Current server
booleanreplaced =false;
// For every remaining split
for(InputSplitsplit : originalSplits){
FileSplit fs = (FileSplit)split;
// For every split location
for(String l : fs.getLocations()){
// If this split is local to the server
if(l.equals(server)){
// Fix split location
splits.add(newFileSplit(fs.getPath(), fs.getStart(),
fs.getLength(),newString[] {server}));
originalSplits.remove(split);
replaced =true;
break;
}
}
if(replaced)
break;
}
// If no local splits are found for this server
if(!replaced){
// Assign first available split to it
FileSplit fs = (FileSplit)splits.get(0);
splits.add(newFileSplit(fs.getPath(), fs.getStart(), fs.getLength(),
newString[] {server}));
originalSplits.remove(0);
}
}
returnsplits;
}
对计算任务进行拆分,在进行底层数据Input时,采用的scroll+query方式,指定分片进行查询。
publicbooleannext(Kkey, Vvalue)throwsIOException {
if(scrollQuery==null) {
if(beat!=null) {
beat.start();
}
#set querey shards and host:127.0.0.1
scrollQuery=queryBuilder.build(client, scrollReader,shards,host);
size=scrollQuery.getSize();
if(log.isTraceEnabled()) {
log.trace(String.format("Received scroll [%s], size [%d] for query [%s]", scrollQuery, size, queryBuilder));
}
}
booleanhasNext=scrollQuery.hasNext();
if(!hasNext) {
returnfalse;
}
Object[] next=scrollQuery.next();
// NB: the left assignment is not needed since method override
// the writable content however for consistency, they are below
currentKey=setCurrentKey(key, next[0]);
currentValue=setCurrentValue(value, next[1]);
// keep on counting
read++;
returntrue;
}
当然这样的做法,还是无法彻底解决单个shards数据量过大的情况下,单个Map任务加载速度过慢情况的出现。通过Demo测试,性能要较原生的Elasticsearch-Hadoop控件有50倍左右提升。
研究的另一个方向是对doc_values数据文件的分析,doc_values文件的设计是解决fielddata占用内存过大,通过分析doc_value和fielddata,一个字段的数据进行排序存储在内存和磁盘,其不就是天生的列式存储么!采用将Map任务直接对Doc_value文件的读取加载,理论上是可以绕过Elasticsearch的计算节点的,需要我们小伙伴们加快研究步伐,解决Elastticsearch无法进行复杂计算的痛病,至少实现桶中桶,在进行soc分析经常被提及的需求。
->