【论文阅读】残差注意力网络Residual Attention Network
论文原文 - Residual Attention Network for Image Classification
注意力
注意力一般分为两种:一种是自上而下(top-down)的有意识的注意力,称为聚焦式(focus)注意力。聚焦式注意力是指有预定目的、依赖任务的、主动有意识地聚焦于某一对象的注意力;另一种是自下而上(bottom-up)的无意识的注意力,称为基于显著性(saliency-based)的注意力。基于显著性的注意力是由外界刺激驱动的注意,不需要主动干预,也和任务无关。如果一个对象的刺激信息不同于其周围信息,一种无意识的“赢者通吃”(winner-take-all)或者门控(gating)机制就可以把注意力转向这个对象。不管这些注意力是有意还是无意,大部分的人脑活动都需要依赖注意力,比如记忆信息,阅读或思考等。
一个和注意力有关的例子是鸡尾酒会效应。当一个人在吵闹的鸡尾酒会上和朋友聊天时,尽管周围噪音干扰很多,他还是可以听到朋友的谈话内容,而忽略其他人的声音(聚焦式注意力)。同时,如果未注意到的背景声中有重要的词(比如他的名字),他会马上注意到(显著性注意力)。
残差注意力网络
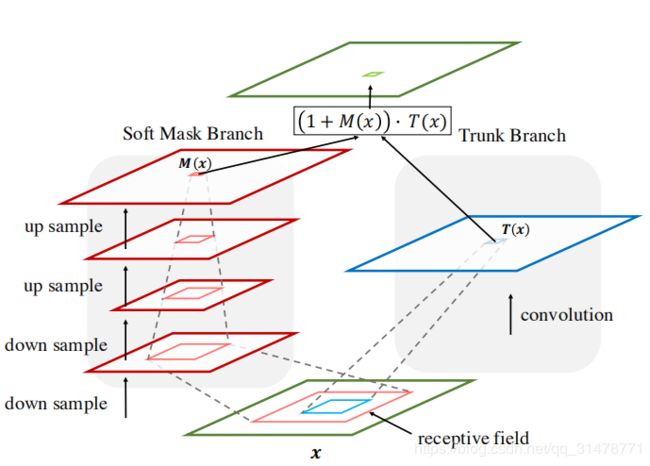
残差注意力网络由多层注意力模块堆叠而成。每个注意力模块分为两部分:掩膜分支(mask branch)和主干分支(trunk branch)。主干分支进行特征处理,它可以使用任何一种网络模型,作者使用的是预激活的残差单元、ResNeXt和Inception作为残差注意力网络基本单元。
假如输入为 x x x,主干分支输出特征图为 T i , c ( x ) T_{i,c}(x) Ti,c(x);掩膜分支使用bottom-up和top-down注意力相结合的方式,学习得到一个与主干输出大小相同的的掩膜 M i , c ( x ) M_{i,c}(x) Mi,c(x)。 M i , c ( x ) M_{i,c}(x) Mi,c(x)相当于 T i , c ( x ) T_{i,c}(x) Ti,c(x)的权重,那么最终该注意力模块的输出特征图为:
H i , c ( x ) = M i , c ( x ) ∗ T i , c ( x ) H_{i,c}(x) = M_{i,c}(x)*T_{i,c}(x) Hi,c(x)=Mi,c(x)∗Ti,c(x)
注意力模块中,注意力掩膜在forward时作为特征选择器,在反向传播时则作为梯度更新的滤波器。
∂ M ( x , θ ) T ( x , ϕ ) ∂ ϕ = M ( x , θ ) ∂ T ( x , ϕ ) ∂ ϕ \frac{\partial M(x, \theta) T(x, \phi)}{\partial \phi}=M(x, \theta) \frac{\partial T(x, \phi)}{\partial \phi} ∂ϕ∂M(x,θ)T(x,ϕ)=M(x,θ)∂ϕ∂T(x,ϕ)
其中 θ \theta θ是掩膜分支的参数, ϕ \phi ϕ是主干分支的参数。这使得注意力模块对噪声的鲁棒性很强,能有效减少噪声对梯度更新的影响。
训练图像中存在的背景遮挡、复杂场景、外观变化等需要多种注意力,如果不使用堆叠注意力模块的方法,则需要更多的channel来涵盖不同因素的组合注意力。而且一个注意力模块只能修改一次特征,这样容错率很小。
注意力残差学习
作者在文中指出,虽然注意力模块对于目标分类有较大的作用,但是单纯叠加注意力模块会导致模型性能的下降,原因有两点:
- 掩膜分支为了输出权重归一的特征图,后面需要跟Sigmoid作为激活函数,但是将输出归一化到0到1之间再与主干分支进行点乘,会使得特征图的输出响应变弱,多层叠加该种结构会使得最终输出的特征图每一个点上的值变得很小;
- 掩膜分支输出的特征图有可能会破坏主干分支的优点,比如说将残差连接中的shortcut机制替换为掩膜分支,那么将会使得深层网络的梯度不能很好的回传。
为了解决上述问题,作者使用了类似于残差学习的方式,将得到的注意力特征图与主干特征图进行element-wised add,因此输出表示为:
H i , c ( x ) = ( 1 + M i , c ( x ) ) ∗ F i , c ( x ) H_{i,c}(x) = (1 + M_{i,c}(x)) * F_{i,c}(x) Hi,c(x)=(1+Mi,c(x))∗Fi,c(x)
M i , c ( x ) M_{i,c}(x) Mi,c(x)的取值在[0, 1]区间内,与1相加之后可以很好的解决一中提出来的会降低特征值的问题。
这与残差网络的区别在于,残差网络的公式 H i , c ( x ) = x + F i , c ( x ) H_{i,c}(x) = x + F_{i,c}(x) Hi,c(x)=x+Fi,c(x), F i , c ( x ) F_{i,c}(x) Fi,c(x)学习的是输出和输入之间的残差结果,而在这个方法中, F i , c ( x ) F_{i,c}(x) Fi,c(x)是一个深层的卷积神经网络输出的特征。 M i , c ( x ) M_{i,c}(x) Mi,c(x)可以作为 F i , c ( x ) F_{i,c}(x) Fi,c(x)的选择器,使输出特征图中有效的特征增强,而噪声被抑制。最终,不断地叠加注意力模块可以使得逐渐的提升网络的表达能力。

软掩膜分支
掩膜分支包括了快速前馈扫描(fast feed-forward sweep)和自上而下的反馈(top-down feedback)步骤。前者快速收集整个图像的全局信息,后者将全局信息与原始特征图相结合。在卷积神经网络中,这两个步骤展开为bottom-up top-down的全卷积结构。
作者主要采用简单的类似于FCN的网络实现掩膜分支。从输入开始,先执行几次max pooling以实现在经过少量Residual Units之后快速增加感受野。达到最低分辨率后,通过一个对称的网络结构将特征放大回去,即在Residual Units后使用线性插值。使用的线性插值数量与最大池化数量一致,保证输入与输出大小相同。然后,接2个连续的1×1卷积层,最后接一个Sigmoid层将输出归一化到[0,1]。在bottom-up和top-down之间添加了skip connections,以捕获不同比例的信息。
空间注意力和通道注意力
作者在注意力模块使用了三种注意力方法Mixed Attention、Channel Attention和Spatial Attention。Mix Attention对每个通道和每个空间位置使用Sigmoid;
f 1 ( x i , c ) = 1 1 + exp ( − x i , c ) f_{1}\left(x_{i, c}\right)=\frac{1}{1+\exp \left(-x_{i, c}\right)} f1(xi,c)=1+exp(−xi,c)1
Channel Attention,类似于SENet使用L2正则化约束每一个通道上的所有特征值,最后输出长度与通道数相同的一维向量作为特征加权;
f 2 ( x i , c ) = x i , c ∥ x i ∥ f_{2}\left(x_{i, c}\right)=\frac{x_{i, c}}{\left\|x_{i}\right\|} f2(xi,c)=∥xi∥xi,c
Spatial Attention使用L2正则化约束每个位置上的所有通道,推测最终输出一个空间维度一致的Attention Map;
f 3 ( x i , c ) = 1 1 + exp ( − ( x i , c − mean c ) / std c ) . f_{3}\left(x_{i, c}\right)=\frac{1}{1+\exp \left(-\left(x_{i, c}-\operatorname{mean}_{c}\right) / \operatorname{std}_{c}\right)}. f3(xi,c)=1+exp(−(xi,c−meanc)/stdc)1.
网络结构图
模型的整体结构图如下:

上面的网络结构中包含了三个阶段的注意力分支,阶段不同,输出特征图大小不同。

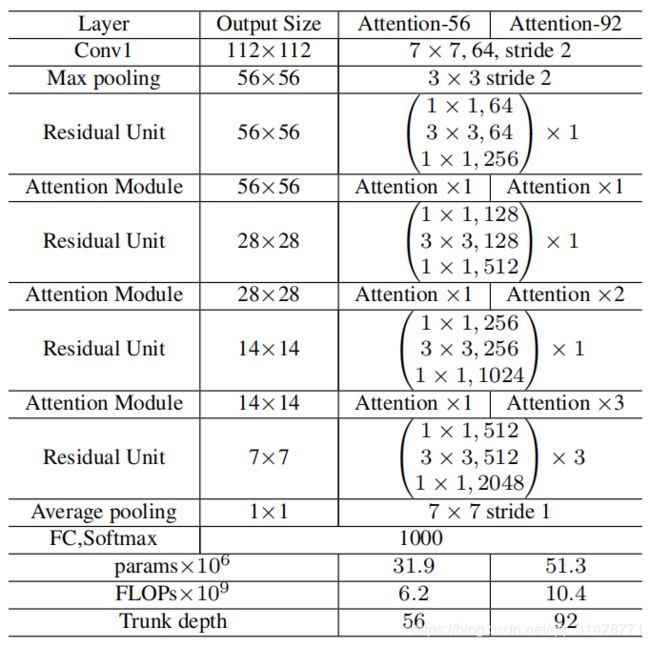
下图是一个使用在ResNet-50上的例子,可以看出来和原始的ResNet的区别就是在每个阶段的残差单元之间增加了Attention模块。可以看到最小的输出特征图的宽高大小为7×7,作者使得降采样的最小特征图尺寸与整个网络中的最小特征图大小一致。首先7×7的特征图对于Attention来说不至于那么粗糙,作者不希望在浅层的Attention丢失的信息太多,其次也保证了它们具有相同大小的感受野。
实验测试
在CIAFR上测试
注意力残差学习这样测试
在这个实验中,评估了注意力残差学习机制的有效性。对含注意力残差学习模块(ARL)和不含注意力残差学习模块(NAL)分别进行实验。具体而言,NAL使用注意力模块,其中特征是通过soft mask直接点积,而没有注意力残差学习。设置不同数量的注意力模块,得到网络Attention-56、Attention-92、Attention-128和Attention-164。
结果如下表所示,带注意力残差学习模块的网络效果更好,且在使用注意力残差学习时,性能随着Attention Module的数量而增加。相比之下,NAL情况相反。

为了深入解析注意力残差学习,作者计算了每个阶段输出层的平均绝对响应值。使用Attention-164进行实验,结果如下图所示。不带学习模块,在第2个阶段时,响应值已经降为0了,此时的模型性能肯定是不行的。
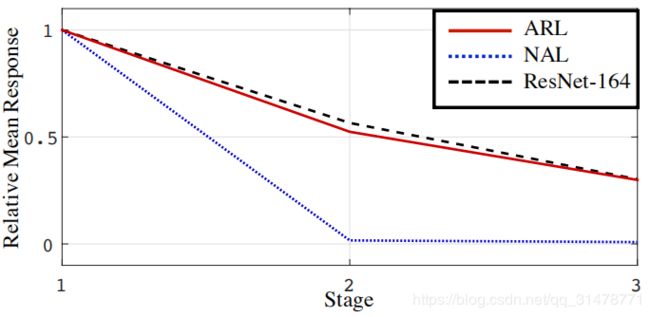
作者说明了原因,注意力模块通过在特征和软掩膜进行点积来抑制噪声,增强有效信息。但是重复的点积不仅会抑制噪声的梯度,同时会抑制有用信息的梯度。所以,通过注意力残差学习方法,可以使用恒等映射单元来减轻信号衰减。因此,它在没有造成显著信息丢失的情况下从降噪中获益,这使得优化变得更加容易。
对比不同的掩膜结构
作者进行了掩膜的对比,对比结果发现采用encoder and decoder的Mixed Attention效果会好一些,如下表:

噪声标签鲁棒性
实验发现,在CIFAR-10数据集上,残差注意力网络在论文《Training convolutional networks with noisy labels》的设置下具有抗噪性。实验中的混淆矩阵Q设置如下:
Q = ( r 1 − r 9 ⋯ 1 − r 9 1 − r 9 r ⋯ 1 − r 9 ⋮ ⋮ ⋱ ⋮ 1 − r 9 1 − r 9 ⋯ r ) 10 × 10 Q=\left( \begin{array}{cccc}{r} & {\frac{1-r}{9}} & {\cdots} & {\frac{1-r}{9}} \\ {\frac{1-r}{9}} & {r} & {\cdots} & {\frac{1-r}{9}} \\ {\vdots} & {\vdots} & {\ddots} & {\vdots} \\ {\frac{1-r}{9}} & {\frac{1-r}{9}} & {\cdots} & {r}\end{array}\right)_{10 \times 10} Q=⎝⎜⎜⎜⎛r91−r⋮91−r91−rr⋮91−r⋯⋯⋱⋯91−r91−r⋮r⎠⎟⎟⎟⎞10×10
其中r表示整个数据集的正确标签比率。
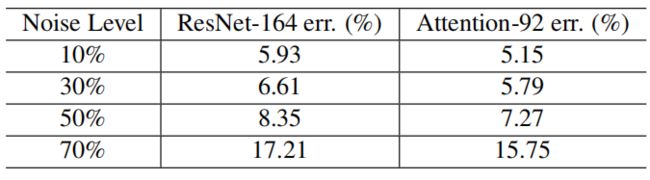
将ResNet-164网络与Attention-92网络在不同的噪声水平下进行比较,结果如下表。相同噪声水平下,Attention-92网络的测试误差明显低于ResNet-164网络。此外,当提高噪声比时,与ResNet-164网络相比,Attenion-92的测试误差缓慢下降。这些结果表明,残差注意力网络可以很好地使用高比率的噪声数据进行训练。当标签有噪声时,相应的掩膜可以防止由标签错误引起的梯度更新主干分支参数。
与state-of-the-art方法对比
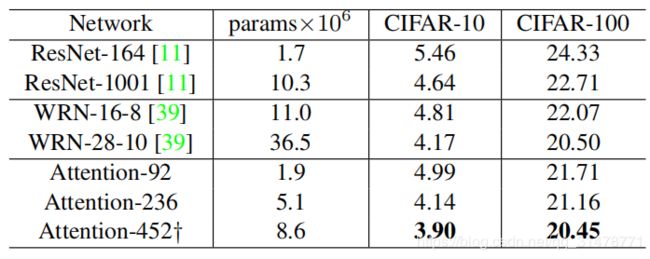
将残差注意力网络与state-of-the-art方法进行比较,包括CIFAR-10和CIFAR-100数据集上的ResNet和Wide ResNet,结果如下。Attention-452优于CIFAR-10和CIFAR-100数据集上的所有baseline方法。在相同参数下,Attention-92在CIFAR-10上的测试误差为4.99%,在CIFAR-100上的测试误差为21.71%,而ResNet-164在CIFAR-10和CIFAR-100上的测试误差分别为5.46%和24.33%。此外,Attention-236仅使用一半参数就优于ResNet-1001。结果表明,注意力模块和注意力残差学习方案可以有效地减少网络中的参数量,同时提高分类性能。
在ImageNet上测试
掩膜的作用
在ImageNet上比较Attention-56和ResNet-152,结果如下表。Attention-56网络大幅优于ResNet-152,top-1 error减少了0.4%,top-5 error减少了0.26%。更重要的是,与ResNet-152相比,Attention-56网络仅仅52%的参数和56%的FLOPs就达到了更好的性能,这表明所提出的注意机制可以显着提高网络性能,同时降低模型复杂性。

使用不同的基本单元
作者使用三个流行的基本单元:Residual Unit,ResNeXt和Inception来构建残差注意力网络。为了使其与参数和FLOPs的数量保持相同,简化了Inception,结果如下表所示。
当基本单元为ResNeXt时,AttentionNeXt-56的性能与ResNeXt-101相同,而参数和FLOPs明显少于ResNeXt-101。对于Inception,AttentionIncepiton-56的优势超过了Inception-ResNet-v1,top-1 error减少了0.94%,top-5 error减少了0.21%。结果表明,该方法适用于不同的网络结构。

与state-of-the-art方法对比
作者在ILSVRC 2012验证集上使用single crop评估的Attention-92与state-of-the-art算法进行比较,结果如下表所示。Attention-92在很大程度上优于ResNet-200。top-1 error减少0.6%。注意,ResNet-200包含的参数比Attention-92多32%。结果显示的Attention-92的计算复杂度表明,与ResNet-200相比,通过增加注意机制和减少主干深度,我们的网络减少了近一半的训练时间。以上结果表明,我们的模型具有较高的效率和良好的性能。
