Python3.6实现scrapy框架爬取数据并将数据插入MySQL与存入文档中
Python进阶(博主前面写过一篇基础的scrapy,刚学的同学可以去看看)
用scrapy框架爬取游戏信息,并将这些游戏信息插入MySQL中。
话不多说直接撸代码
scrapy框架搭建过程
1、同样是先建立工程
scrapy startproject gamerank
2、写spider文件,建立文件gamerank.py,代码如下:
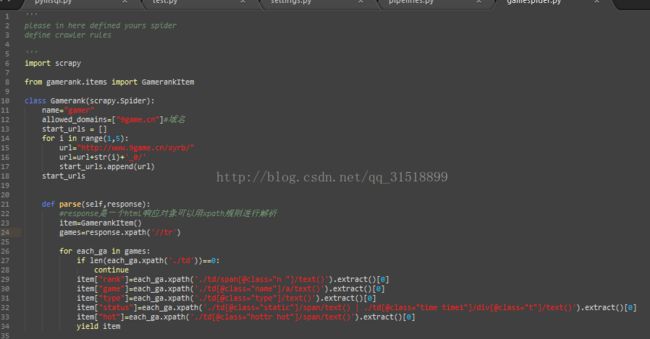
上面的第32行代码是博主后面做了一点小的更改
把
item["status"]=each_ga.xpath('./td[@class="static"]/span/text()
改为了
item["status"]=each_ga.xpath('./td[@class="static"]/span/text() | ./td[@class="time time1"]/div[@class="t"]/text()').extract()[0]
本来爬得好好地但是被网站的后台或者是维护人员摆了一道,我不得不做下更改,具体情况请看:
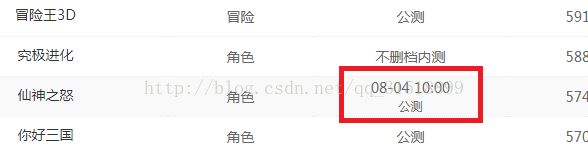
惊不惊喜,意不意外,对,该后台人员可能是为了防止爬虫在游戏状态这加了一个 08-04 10:00我惊了

所以以后写爬虫一定要注意也许今天能爬取数据,明天就不能了,先不要怀疑人生,直接怀疑网站搞怪。
3、编写item文件
import scrapyclass GamerankItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field()
#游戏的排名 rank=scrapy.Field()
#游戏的名字 game=scrapy.Field()
#游戏的类型 type=scrapy.Field()
#游戏的状态 status=scrapy.Field()
#游戏的热度 hot=scrapy.Field()
4、编写pipelines文件
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymysql
####注意一定要导入配置,因为数据库的一些连接信息写在settings文件里的
#此类是把信息写入文档,写入时末尾都加了一个逗号,是为了数据的观看与直观性
#也方便以后用mysql语言直接导入数据
from scrapy.conf import settings
# class GamerankPipeline(object):
# def process_item(self, item, spider):
# with open('games_list.txt','a',encoding='utf-8') as f:
# f.write(item['rank']+',')
# f.write(item['game']+',')
# f.write(item['type']+',')
# f.write(item['status']+',')
# f.write(item['hot'])
# f.write('\n')
#下面是将爬取到的信息插入到MySQL数据库中
class Gamerank_Pipeline(object):
def process_item(self, item, spider):
host = settings['MYSQL_HOSTS']
user = settings['MYSQL_USER']
psd = settings['MYSQL_PASSWORD']
db = settings['MYSQL_DB']
c=settings['CHARSET']
port=settings['MYSQL_PORT']
#数据库连接
con=pymysql.connect(host=host,user=user,passwd=psd,db=db,charset=c,port=port)
#数据库游标
cue=con.cursor()
print("mysql connect succes")#测试语句,这在程序执行时非常有效的理解程序是否执行到这一步
#sql="insert into gamerank (rank,g_name,g_type,g_status,g_hot) values(%s,%s,%s,%s,%s)" % (item['rank'],item['game'],item['type'],item['status'],item['hot'])
try:
cue.execute("insert into gamerank (rank,g_name,g_type,g_status,g_hot) values(%s,%s,%s,%s,%s)",[ item['rank'],item['game'],item['type'],item['status'],item['hot'] ])
print("insert success")#测试语句
except Exception as e:
print('Insert error:',e)
con.rollback()
else:
con.commit()
con.close()
return item
5、写settings文件
在settings文件下面加入如下信息
#这些都是你的数据库登录的一些数据
MYSQL_HOST='127.0.0.1'
MYSQL_USER='root'
#你自己数据库的密码
MYSQL_PASSWORD='******'
MYSQL_PORT =3306
#你自己数据库的名称
MYSQL_DB='******'
CHARSET='utf8'
ITEM_PIPELINES = {'gamerank.pipelines.GamerankPipeline': 100,
'gamerank.pipelines.Gamerank_Pipeline': 100
}
6、开始运行爬虫
scrapy crawl gamer
运行结果:

我们在查看MySQL中,(记住此MySQL表格是先前建立好的表格,当然你在pipelines中建立也可以,这里不多做解释),结果如下;
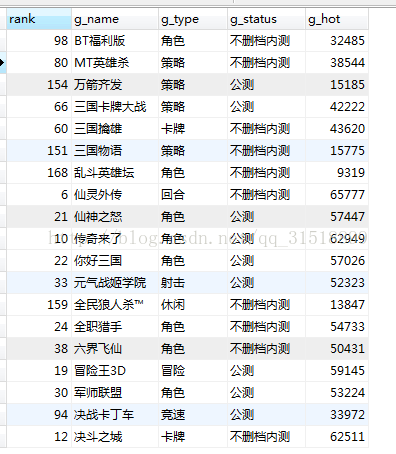
成功将数据写入了数据库
数据分析与异常分析
用SQL语句进行数据的简单分析
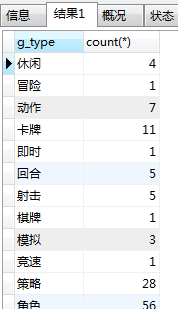
例如:下面统计一下游戏的类型数量
select g_type,count(*) from gamerank GROUP BY g_type;
结果如下:
你以为到此就完了吗??

错误与异常处理
当然没完,因为你的爬虫运行出来的为403
403错误,表示资源不可用。服务器理解客户的请求,但拒绝处理它,通常由于服务器上文件或目录的权限设置导致的WEB访问错误。这是为什么呢?这是因为此网站有反爬虫机制
你用http://www.9game.cn/robots.txt,可以查看![]()
那么我们就需要修改代理
找到Python的:安装目录下的default_settings.py文件,比如我的F:\Software\Python36\Lib\site-packages\scrapy\settings\default_settings.py,把下面的
USER_AGENT = 'Scrapy/%s (+http://scrapy.org)' % import_module('scrapy').__version__
修改为:USER_AGENT = 'Mozilla/5.0 (Windows NT 5.1; rv:5.0) Gecko/20100101 Firefox/5.0'
当然不止这一种方法,更多方法请查看下面链接:
http://blog.csdn.net/u011781521/article/details/70211474
这下应该是没得了。
溜了溜了。。。