hive> load data local inpath '/opt/module/datas/student.txt' into table student;
(8)Hive查询结果
hive> select * from student;
OK
1001 zhangshan
1002 lishi
1003 zhaoliu
Time taken: 0.266 seconds, Fetched: 3 row(s)
3.遇到的问题
再打开一个客户端窗口启动hive,会产生java.sql.SQLException异常。
Exception in thread "main" java.lang.RuntimeException: java.lang.RuntimeException:
Unable to instantiate
org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:522)
at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:677)
at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:621)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.hadoop.util.RunJar.run(RunJar.java:221)
at org.apache.hadoop.util.RunJar.main(RunJar.java:136)
Caused by: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
at org.apache.hadoop.hive.metastore.MetaStoreUtils.newInstance(MetaStoreUtils.java:1523)
at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.(RetryingMetaStoreClient.java:86)
at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.getProxy(RetryingMetaStoreClient.java:132)
at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.getProxy(RetryingMetaStoreClient.java:104)
at org.apache.hadoop.hive.ql.metadata.Hive.createMetaStoreClient(Hive.java:3005)
at org.apache.hadoop.hive.ql.metadata.Hive.getMSC(Hive.java:3024)
at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:503)
... 8 more
javax.jdo.option.ConnectionURLjdbc:mysql://hadoop102:3306/metastore?createDatabaseIfNotExist=trueJDBC connect string for a JDBC metastorejavax.jdo.option.ConnectionDriverNamecom.mysql.jdbc.DriverDriver class name for a JDBC metastorejavax.jdo.option.ConnectionUserNamerootusername to use against metastore databasejavax.jdo.option.ConnectionPassword000000password to use against metastore database
3.配置完毕后,如果启动hive异常,可以重新启动虚拟机。(重启后,别忘了启动hadoop集群)
2.5.3 多窗口启动Hive测试
1.先启动MySQL
[newbies@hadoop102 mysql-libs]$ mysql -uroot -p000000
查看有几个数据库
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| test |
+--------------------+
2.再次打开多个窗口,分别启动hive
[newbies@hadoop102 hive]$ bin/hive
3.启动hive后,回到MySQL窗口查看数据库,显示增加了metastore数据库
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| metastore |
| mysql |
| performance_schema |
| test |
+--------------------+
2.6 HiveJDBC访问
2.6.1 启动hiveserver2服务
[newbies@hadoop102 hive]$ bin/hiveserver2
2.6.2 启动beeline
[newbies@hadoop102 hive]$ bin/beeline
Beeline version 1.2.1 by Apache Hive
beeline>
2.6.3 连接hiveserver2
beeline> !connect jdbc:hive2://hadoop102:10000(回车)
Connecting to jdbc:hive2://hadoop102:10000
Enter username for jdbc:hive2://hadoop102:10000: newbies(回车)
Enter password for jdbc:hive2://hadoop102:10000: (直接回车)
Connected to: Apache Hive (version 1.2.1)
Driver: Hive JDBC (version 1.2.1)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://hadoop102:10000> show databases;
+----------------+--+
| database_name |
+----------------+--+
| default |
| hive_db2 |
+----------------+--+
2.7 Hive常用交互命令
[newbies@hadoop102 hive]$ bin/hive -help
usage: hive
-d,--define Variable subsitution to apply to hive
commands. e.g. -d A=B or --define A=B
--database Specify the database to use
-e SQL from command line
-f SQL from files
-H,--help Print help information
--hiveconf Use value for given property
--hivevar Variable subsitution to apply to hive
commands. e.g. --hivevar A=B
-i Initialization SQL file
-S,--silent Silent mode in interactive shell
-v,--verbose Verbose mode (echo executed SQL to the console)
1.“-e”不进入hive的交互窗口执行sql语句
[newbies@hadoop102 hive]$ bin/hive -e "select id from student;"
type string)
row format delimited fields terminated by "\t";
load data local inpath “/opt/module/datas/person_info.txt” into table person_info;
6.按需求查询数据
select
t1.base,
concat_ws('|', collect_set(t1.name)) name
from
(select
name,
concat(constellation, ",", blood_type) base
from
person_info) t1
group by
t1.base;
# Set HADOOP_HOME to point to a specific hadoop install directory
export HADOOP_HOME=/opt/module/hadoop-2.7.2
# Hive Configuration Directory can be controlled by:
export HIVE_CONF_DIR=/opt/module/hive/conf
# Folder containing extra libraries required for hive compilation/execution can be controlled by:
export TEZ_HOME=/opt/module/tez-0.9.1 #是你的tez的解压目录
export TEZ_JARS=""
for jar in `ls $TEZ_HOME |grep jar`; do
export TEZ_JARS=$TEZ_JARS:$TEZ_HOME/$jar
done
for jar in `ls $TEZ_HOME/lib`; do
export TEZ_JARS=$TEZ_JARS:$TEZ_HOME/lib/$jar
done
export HIVE_AUX_JARS_PATH=/opt/module/hadoop-2.7.2/share/hadoop/common/hadoop-lzo-0.4.20.jar$TEZ_JARS
2.2.3 配置Tez
在Hive 的/opt/module/hive/conf下面创建一个tez-site.xml文件
[newbies@hadoop102 conf]$ pwd
/opt/module/hive/conf
[newbies@hadoop102 conf]$ vim tez-site.xml
hive (default)> create table student(
id int,
name string);
3)向表中插入数据。
hive (default)> insert into student values(1,"zhangsan");
4)如果没有报错就表示成功了
hive (default)> select * from student;
1 zhangsan
2.2.6 小结
1)运行Tez时检查到用过多内存而被NodeManager杀死进程问题:
Caused by: org.apache.tez.dag.api.SessionNotRunning: TezSession has already shutdown. Application application_1546781144082_0005 failed 2 times due to AM Container for appattempt_1546781144082_0005_000002 exited with exitCode: -103
For more detailed output, check application tracking page:http://hadoop103:8088/cluster/app/application_1546781144082_0005Then, click on links to logs of each attempt.
Diagnostics: Container [pid=11116,containerID=container_1546781144082_0005_02_000001] is running beyond virtual memory limits. Current usage: 216.3 MB of 1 GB physical memory used; 2.6 GB of 2.1 GB virtual memory used. Killing container.
[摘录] The NodeManager is killing your container. It sounds like you are trying to
use hadoop streaming which is running as a child process of the map-reduce task. The
NodeManager monitors the entire process tree of the task and if it eats up more
memory than the maximum set in mapreduce.map.memory.mb or mapreduce.reduce.memory.mb
respectively, we would expect the Nodemanager to kill the task, otherwise your task
is stealing memory belonging to other containers, which you don't want.
hive (gmall)> add jar /opt/module/hive/hivefunction-1.0-SNAPSHOT.jar;
5)创建临时函数与开发好的java class关联
hive (gmall)>
create temporary function base_analizer as 'com.newbies.udf.BaseFieldUDF';
create temporary function flat_analizer as 'com.newbies.udtf.EventJsonUDTF';
3.3.4 解析启动日志基础明细表
1)解析启动日志基础明细表
hive (gmall)>
use gmall;
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table dwd_base_start_log
PARTITION (dt)
select
mid_id,
user_id,
version_code,
version_name,
lang,
source ,
os ,
area ,
model ,
brand ,
sdk_version ,
gmail ,
height_width ,
app_time ,
network ,
lng ,
lat ,
event_name ,
event_json ,
server_time ,
dt
from
(
select
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[0] as mid_id,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[1] as user_id,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[2] as version_code,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[3] as version_name,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[4] as lang,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[5] as source,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[6] as os,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[7] as area,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[8] as model,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[9] as brand,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[10] as sdk_version,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[11] as gmail,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[12] as height_width,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[13] as app_time,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[14] as network,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[15] as lng,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[16] as lat,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[17] as ops,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[18] as server_time,
dt
from ods_start_log where dt='2019-02-10' and base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la')<>''
) sdk_log lateral view flat_analizer(ops) tmp_k as event_name, event_json;
2)测试
hive (gmall)> select * from dwd_base_start_log limit 2;
3.3.5 解析事件日志基础明细表
1)解析事件日志基础明细表
hive (gmall)>
use gmall;
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table dwd_base_event_log
PARTITION (dt)
select
mid_id,
user_id,
version_code,
version_name,
lang,
source ,
os ,
area ,
model ,
brand ,
sdk_version ,
gmail ,
height_width ,
app_time ,
network ,
lng ,
lat ,
event_name ,
event_json ,
server_time ,
dt
from
(
select
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[0] as mid_id,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[1] as user_id,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[2] as version_code,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[3] as version_name,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[4] as lang,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[5] as source,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[6] as os,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[7] as area,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[8] as model,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[9] as brand,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[10] as sdk_version,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[11] as gmail,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[12] as height_width,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[13] as app_time,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[14] as network,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[15] as lng,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[16] as lat,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[17] as ops,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[18] as server_time,
dt
from ods_event_log where dt='2019-02-10' and base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la')<>''
) sdk_log lateral view flat_analizer(ops) tmp_k as event_name, event_json;
2)测试
hive (gmall)> select * from dwd_base_event_log limit 2;
3.3.6 DWD层数据解析脚本
1)在hadoop102的/home/newbies/bin目录下创建脚本
[newbies@hadoop102 bin]$ vim dwd_base.sh
在脚本中编写如下内容
#!/bin/bash
# 定义变量方便修改
APP=gmall
hive=/opt/module/hive/bin/hive
# 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
if [ -n $1 ] ;then
log_date=$1
else
log_date=`date -d "-1 day" +%F`
fi
sql="
add jar /opt/module/hive/hivefunction-1.0-SNAPSHOT.jar;
create temporary function base_analizer as 'com.newbies.udf.BaseFieldUDF';
create temporary function flat_analizer as 'com.newbies.udtf.EventJsonUDTF';
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table "$APP".dwd_base_start_log
PARTITION (dt)
select
mid_id,
user_id,
version_code,
version_name,
lang,
source ,
os ,
area ,
model ,
brand ,
sdk_version ,
gmail ,
height_width ,
network ,
lng ,
lat ,
app_time ,
event_name ,
event_json ,
server_time ,
dt
from
(
select
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[0] as mid_id,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[1] as user_id,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[2] as version_code,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[3] as version_name,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[4] as lang,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[5] as source,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[6] as os,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[7] as area,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[8] as model,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[9] as brand,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[10] as sdk_version,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[11] as gmail,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[12] as height_width,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[13] as app_time,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[14] as network,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[15] as lng,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[16] as lat,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[17] as ops,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[18] as server_time,
dt
from "$APP".ods_start_log where dt='$log_date' and base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la')<>''
) sdk_log lateral view flat_analizer(ops) tmp_k as event_name, event_json;
insert overwrite table "$APP".dwd_base_event_log
PARTITION (dt)
select
mid_id,
user_id,
version_code,
version_name,
lang,
source ,
os ,
area ,
model ,
brand ,
sdk_version ,
gmail ,
height_width ,
network ,
lng ,
lat ,
app_time ,
event_name ,
event_json ,
server_time ,
dt
from
(
select
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[0] as mid_id,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[1] as user_id,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[2] as version_code,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[3] as version_name,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[4] as lang,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[5] as source,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[6] as os,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[7] as area,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[8] as model,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[9] as brand,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[10] as sdk_version,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[11] as gmail,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[12] as height_width,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[13] as app_time,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[14] as network,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[15] as lng,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[16] as lat,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[17] as ops,
split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[18] as server_time,
dt
from "$APP".ods_event_log where dt='$log_date' and base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la')<>''
) sdk_log lateral view flat_analizer(ops) tmp_k as event_name, event_json;
"
$hive -e "$sql"
hive (gmall)>
drop table if exists stud;
create table stud (name string, area string, course string, score int);
2)向原数据表中插入数据
hive (gmall)>
insert into table stud values('zhang3','bj','math',88);
insert into table stud values('li4','bj','math',99);
insert into table stud values('wang5','sh','chinese',92);
insert into table stud values('zhao6','sh','chinese',54);
insert into table stud values('tian7','bj','chinese',91);
3)查询表中数据
hive (gmall)> select * from stud;
stud.name stud.area stud.course stud.score
zhang3 bj math 88
li4 bj math 99
wang5 sh chinese 92
zhao6 sh chinese 54
tian7 bj chinese 91
4)把同一分组的不同行的数据聚合成一个集合
hive (gmall)> select course, collect_set(area), avg(score) from stud group by course;
chinese ["sh","bj"] 79.0
math ["bj"] 93.5
5) 用下标可以取某一个
hive (gmall)> select course, collect_set(area)[0], avg(score) from stud group by course;
chinese sh 79.0
math bj 93.5
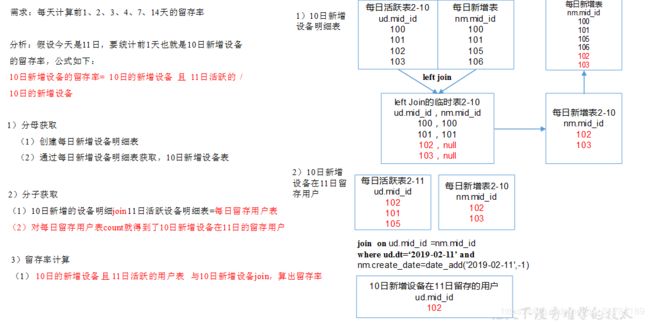
用每日活跃用户表 left join 每日新增设备表,关联的条件是mid_id相等。如果是每日新增的设备,则在每日新增设备表中为null。
hive (gmall)>
insert into table dws_new_mid_day
select
ud.mid_id,
ud.user_id ,
ud.version_code ,
ud.version_name ,
ud.lang ,
ud.source,
ud.os,
ud.area,
ud.model,
ud.brand,
ud.sdk_version,
ud.gmail,
ud.height_width,
ud.app_time,
ud.network,
ud.lng,
ud.lat,
'2019-02-10'
from dws_uv_detail_day ud left join dws_new_mid_day nm on ud.mid_id=nm.mid_id
where ud.dt='2019-02-10' and nm.mid_id is null;
3)查询导入数据
hive (gmall)> select count(*) from dws_new_mid_day ;
6.2 ADS层(每日新增设备表)
1)建表语句
hive (gmall)>
drop table if exists `ads_new_mid_count`;
create table `ads_new_mid_count`
(
`create_date` string comment '创建时间' ,
`new_mid_count` BIGINT comment '新增设备数量'
) COMMENT '每日新增设备信息数量'
row format delimited fields terminated by '\t'
location '/warehouse/gmall/ads/ads_new_mid_count/';
2)导入数据
hive (gmall)>
insert into table ads_new_mid_count
select create_date , count(*) from dws_new_mid_day
where create_date='2019-02-10'
group by create_date ;
hive (gmall)>
insert overwrite table dws_user_retention_day partition(dt="2019-02-11")
select
nm.mid_id,
nm.user_id ,
nm.version_code ,
nm.version_name ,
nm.lang ,
nm.source,
nm.os,
nm.area,
nm.model,
nm.brand,
nm.sdk_version,
nm.gmail,
nm.height_width,
nm.app_time,
nm.network,
nm.lng,
nm.lat,
nm.create_date,
1 retention_day
from dws_uv_detail_day ud join dws_new_mid_day nm on ud.mid_id =nm.mid_id
where ud.dt='2019-02-11' and nm.create_date=date_add('2019-02-11',-1);
3)查询导入数据(每天计算前1天的新用户访问留存明细)
hive (gmall)> select count(*) from dws_user_retention_day;
7.3.2 DWS层(1,2,3,n天留存用户明细表)
1)导入数据(每天计算前1,2,3,n天的新用户访问留存明细)
hive (gmall)>
insert overwrite table dws_user_retention_day partition(dt="2019-02-11")
select
nm.mid_id,
nm.user_id ,
nm.version_code ,
nm.version_name ,
nm.lang ,
nm.source,
nm.os,
nm.area,
nm.model,
nm.brand,
nm.sdk_version,
nm.gmail,
nm.height_width,
nm.app_time,
nm.network,
nm.lng,
nm.lat,
nm.create_date,
1 retention_day
from dws_uv_detail_day ud join dws_new_mid_day nm on ud.mid_id =nm.mid_id
where ud.dt='2019-02-11' and nm.create_date=date_add('2019-02-11',-1)
union all
select
nm.mid_id,
nm.user_id ,
nm.version_code ,
nm.version_name ,
nm.lang ,
nm.source,
nm.os,
nm.area,
nm.model,
nm.brand,
nm.sdk_version,
nm.gmail,
nm.height_width,
nm.app_time,
nm.network,
nm.lng,
nm.lat,
nm.create_date,
2 retention_day
from dws_uv_detail_day ud join dws_new_mid_day nm on ud.mid_id =nm.mid_id
where ud.dt='2019-02-11' and nm.create_date=date_add('2019-02-11',-2)
union all
select
nm.mid_id,
nm.user_id ,
nm.version_code ,
nm.version_name ,
nm.lang ,
nm.source,
nm.os,
nm.area,
nm.model,
nm.brand,
nm.sdk_version,
nm.gmail,
nm.height_width,
nm.app_time,
nm.network,
nm.lng,
nm.lat,
nm.create_date,
3 retention_day
from dws_uv_detail_day ud join dws_new_mid_day nm on ud.mid_id =nm.mid_id
where ud.dt='2019-02-11' and nm.create_date=date_add('2019-02-11',-3);
2)查询导入数据(每天计算前1,2,3天的新用户访问留存明细)
hive (gmall)> select retention_day , count(*) from dws_user_retention_day;
7.3 ADS层
7.3.1留存用户数
1)建表语句
hive (gmall)>
drop table if exists `ads_user_retention_day_count`;
create table `ads_user_retention_day_count`
(
`create_date` string comment '设备新增日期',
`retention_day` int comment '截止当前日期留存天数',
retention_count bigint comment '留存数量'
) COMMENT '每日用户留存情况'
stored as parquet
location '/warehouse/gmall/ads/ads_user_retention_day_count/';
2)导入数据
hive (gmall)>
insert into table ads_user_retention_day_count
select
create_date,
retention_day,
count(*) retention_count
from dws_user_retention_day
where dt='2019-02-11'
group by create_date,retention_day;
3)查询导入数据
hive (gmall)> select * from ads_user_retention_day_count;
hive (gmall)>
insert into table ads_user_retention_day_rate
select
'2019-02-11' ,
ur.create_date,
ur.retention_day,
ur.retention_count ,
nc.new_mid_count,
ur.retention_count/nc.new_mid_count*100
from
(
select
create_date,
retention_day,
count(*) retention_count
from `dws_user_retention_day`
where dt='2019-02-11'
group by create_date,retention_day
) ur join ads_new_mid_count nc on nc.create_date=ur.create_date;
3)查询导入数据
hive (gmall)>select * from ads_user_retention_day_rate;
spring JMS对于异步消息处理基本上只需配置下就能进行高效的处理。其核心就是消息侦听器容器,常用的类就是DefaultMessageListenerContainer。该容器可配置侦听器的并发数量,以及配合MessageListenerAdapter使用消息驱动POJO进行消息处理。且消息驱动POJO是放入TaskExecutor中进行处理,进一步提高性能,减少侦听器的阻塞。具体配置如下:
ZIP文件的解压缩实质上就是从输入流中读取数据。Java.util.zip包提供了类ZipInputStream来读取ZIP文件,下面的代码段创建了一个输入流来读取ZIP格式的文件;
ZipInputStream in = new ZipInputStream(new FileInputStream(zipFileName));
&n
Spring可以通过注解@Transactional来为业务逻辑层的方法(调用DAO完成持久化动作)添加事务能力,如下是@Transactional注解的定义:
/*
* Copyright 2002-2010 the original author or authors.
*
* Licensed under the Apache License, Version
使用nginx lua已经两三个月了,项目接开发完毕了,这几天准备上线并且跟高德地图对接。回顾下来lua在项目中占得必中还是比较大的,跟PHP的占比差不多持平了,因此在开发中遇到一些问题备忘一下 1:content_by_lua中代码容量有限制,一般不要写太多代码,正常编写代码一般在100行左右(具体容量没有细心测哈哈,在4kb左右),如果超出了则重启nginx的时候会报 too long pa
import java.util.Stack;
public class ReverseStackRecursive {
/**
* Q 66.颠倒栈。
* 题目:用递归颠倒一个栈。例如输入栈{1,2,3,4,5},1在栈顶。
* 颠倒之后的栈为{5,4,3,2,1},5处在栈顶。
*1. Pop the top element
*2. Revers
仅作笔记使用
public class VectorQueue {
private final Vector<VectorItem> queue;
private class VectorItem {
private final Object item;
private final int quantity;
public VectorI

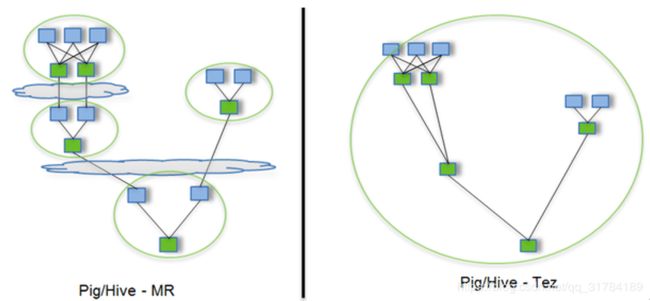
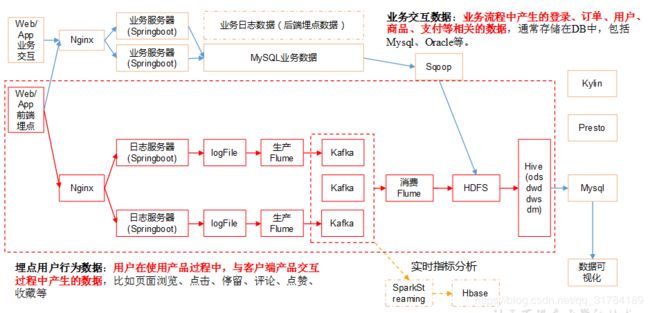 Hive仓库
Hive仓库

 ODS层创建事件日志表分析
ODS层创建事件日志表分析
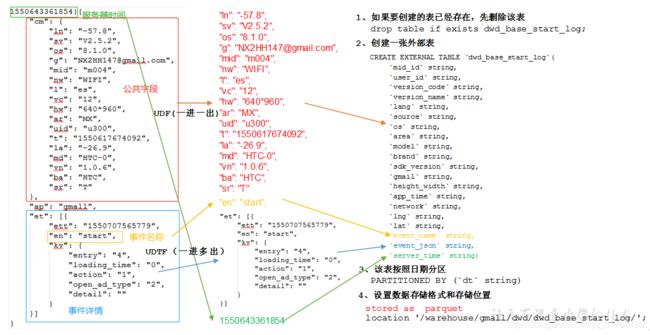 DWD层创建基础明细表分析
DWD层创建基础明细表分析
 UDF函数解析公共字段
UDF函数解析公共字段
 UDTF函数解析具体事件
UDTF函数解析具体事件

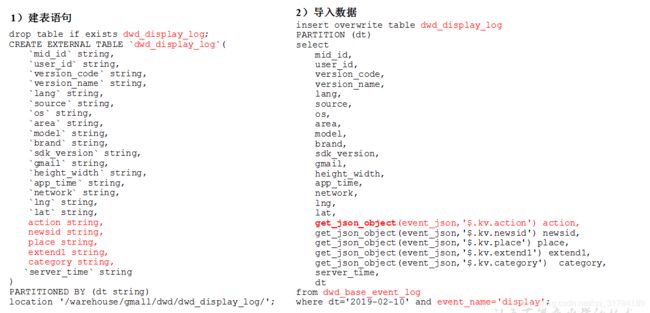 商品点击表解析
商品点击表解析
 每日设备活跃分析
每日设备活跃分析
 每周活跃设备明细
每周活跃设备明细

 活跃设备分析
活跃设备分析
 每日新增设备分析
每日新增设备分析
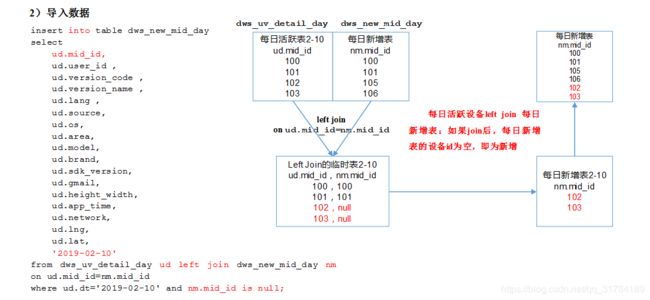 每日新增设备分析
每日新增设备分析