numpy手写mlp
直接提供代码
一共分四个文件
trainer.py用于接受参数开始训练
layer.py用于定义每个层的属性和功能
net.py用于构建整个神经网络
mlp用于读取mnist数据集并进行训练
记得把trainer,layer,net这三个文件拷到同一个文件夹下,方便mlp文件调用这三个文件的类
DogeTrainer.py
from dogelearning.DogeLayer import Layer
from dogelearning.DogeNet import Net
from tqdm.std import trange
import numpy as np
class Trainer:
def train(self,net,train_loader,batch_size,optimizer='sgd',epoch_num=50):
list = []
for i in trange(0, epoch_num):
for batch_idx, (data, target) in enumerate(train_loader):
if (data.shape[0] < batch_size):
break
data = np.squeeze(data.numpy()).reshape(batch_size, 784) # 把张量中维度为1的维度去掉,并且改变维度为(64,784)
target = target.numpy() # x矩阵 (64,10)
y_hat = net.forward(data)
net.backward( np.eye(10)[target] )
list.append(Accuracy(target, y_hat))
if (batch_idx == 50):
print("准确率为" + str(Accuracy(target, y_hat)))
return list
def Accuracy(target, y_hat):
# y_hat.argmax(axis=1)==target 用于比较y_hat与target的每个元素,返回一个布尔数组
acc = y_hat.argmax(axis=1) == target
acc = acc + 0 # 将布尔数组转为0,1数组
return acc.mean() # 通过求均值算出准确率
DogeNet.py
from dogelearning.DogeLayer import *
class Net:
layers=[]
batch_size=0
input_num=0
def __init__(self,batch_size,input_num):
self.batch_size=batch_size
self.input_num=input_num
pass
def add(self,layer_type,node_num,activation=""):
if (len(self.layers)==0):
last_node_num=self.input_num
else:
last_node_num=self.layers[-1].node_num #获取上一层的节点个数
if (layer_type=='Softmax'):
self.layers.append(Softmax((node_num)))
else:
self.layers.append(Layer(last_node_num,node_num,self.batch_size,activation))
def forward(self,data):
for layer in self.layers:
data=layer.forward(data)
return data #返回最后输出的data用于反向传播
def backward(self,y_hat):
dydx=y_hat
for layer in reversed(self.layers):
dydx=layer.backward(dydx)
def print(self):
print("网络名 节点个数 激活函数")
for layer in self.layers:
print(layer,layer.node_num,layer.activation)
DogeLayer.py
# import minpy.numpy as mnp
import numpy as np
class Layer:
lamda = 3 # 正则化惩罚系数
w=0
b=0
last_node_num=0
node_num=0
batch_size=0
activation=''
learning_rate=0.1
x=0
activation_data =0
def __init__(self,last_node_num,node_num,batch_size,activation):
self.last_node_num=last_node_num
self.node_num=node_num
self.w = np.random.normal(scale=0.01, size=(last_node_num,node_num)) # 生成随机正太分布的w矩阵
self.b = np.zeros((batch_size, node_num))
self.activation=activation
self.batch_size=batch_size
def forward(self,data):
self.x=data
data=np.dot(data, self.w) + self.b
if self.activation=="Sigmoid":
data=1 / (1 + np.exp(-data))
# print(data.mean())
if self.activation=="Tahn":
data = (np.exp(data)- np.exp(-data)) / (np.exp(data)+ np.exp(-data))
if self.activation == "Relu":
data= (np.abs(data)+data)/2.0
self.activation_data = data
return data
def backward(self,y):
if self.activation == "Sigmoid":
y = self.activation_data * (1 - self.activation_data) * y
if self.activation == "Tahn":
y = (1 - self.activation_data**2) * y
if self.activation=="Relu":
self.activation_data[self.activation_data <= 0] = 0
self.activation_data[self.activation_data > 0] = 1
y = self.activation_data *y
w_gradient=np.dot(self.x.T, y)
b_gradient=y
y=np.dot(y,self.w.T)
self.w = self.w - (w_gradient+(self.lamda*self.w)) / self.batch_size * self.learning_rate
self.b = self.b - b_gradient / self.batch_size * self.learning_rate
return y
class Softmax (Layer):
y_hat=[]
def __init__(self,node_num):
self.node_num=node_num
pass
def forward(self,data):
data = np.exp(data.T) # 先把每个元素都进行exp运算
# print(label)
sum = data.sum(axis=0) # 对于每一行进行求和操作
# print((label/sum).T.sum(axis=1))
self.y_hat=(data / sum).T
return self.y_hat # 通过广播机制,使每行分别除以各种的和
def backward(self,y):
return self.y_hat-y
MLP.py
from torchvision import datasets, transforms
import torch.utils.data as Data
# import minpy.numpy as mnp
# import numpy as np
from dogelearning.DogeNet import Net
from dogelearning.DogeLayer import Layer
from dogelearning.DogeTrainer import Trainer
batch_size = 256
learning_rate=0.001
def load_data():
# 加载torchvision包内内置的MNIST数据集 这里涉及到transform:将图片转化成torchtensor
train_dataset = datasets.MNIST(root='./data/', train=True, transform=transforms.ToTensor(), download=True)
# 加载小批次数据,即将MNIST数据集中的data分成每组batch_size的小块,shuffle指定是否随机读取
train_loader = Data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
return train_loader
if __name__ == '__main__':
train_loader=load_data() #加载数据(这里使用pytorch加载数据,后面用numpy手写)
net = Net(batch_size,784)
print(net.batch_size)
# net.add("",256,activation="Sigmoid")
# net.add("", 64, activation="Sigmoid")
# net.add("", 10, activation="Sigmoid")
# net.add("Softmax", 10)
# net.add("", 256, activation="Tahn")
# net.add("", 64, activation="Tahn")
# net.add("", 10, activation="Tahn")
# net.add("Softmax", 10)
net.add("", 256, activation="Relu")
net.add("", 64, activation="Relu")
net.add("", 10, activation="Relu")
net.add("Softmax", 10)
net.print()
list=Trainer.train(train_loader,net,train_loader,batch_size,epoch_num=100)
import matplotlib.pyplot as plt
plt.plot(list)
plt.show()
最终效果如下
网络名 节点个数 激活函数
256 Relu
64 Relu
10 Relu
10
准确率为0.3046875
1%| | 1/100 [00:07<13:08, 7.97s/it]准确率为0.24609375
2%|▏ | 2/100 [00:16<13:14, 8.11s/it]准确率为0.4140625
3%|▎ | 3/100 [00:28<14:59, 9.27s/it]准确率为0.68359375
4%|▍ | 4/100 [00:38<15:13, 9.51s/it]准确率为0.81640625
5%|▌ | 5/100 [00:50<16:12, 10.23s/it]准确率为0.87109375
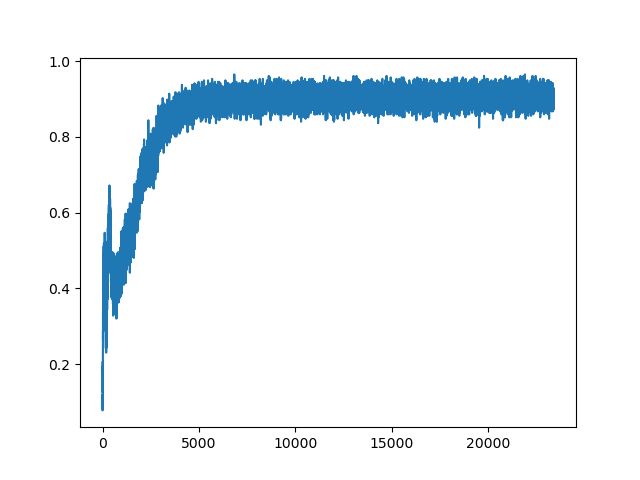
tahn的优化图像
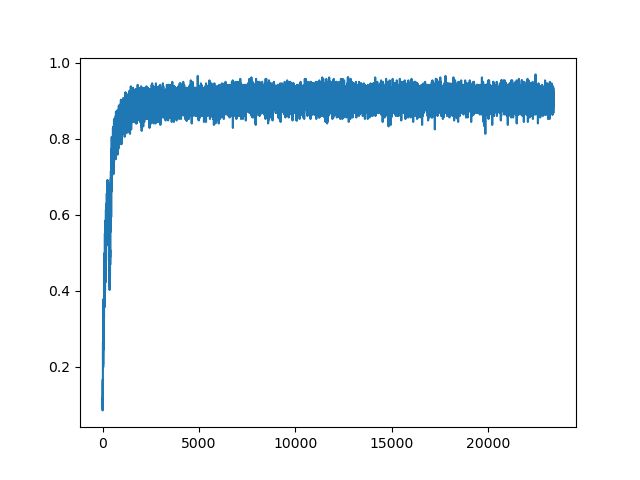
relu的优化图像