葵花宝典--SparkStreaming
一、概述
1、定义
- Spark Streaming用于处理流式数据。支持多种数据源,常用kafka,数据输入后可以使用spark的算子进行操作,运行的结果可以保存在很多地方。
- 处理数据为小批次处理,使用时间间隔来将数据分开,批处理的间隔影响了作业的提交效率和数据处理延迟,也影响了数据处理的吞吐量和性能。
- 使用了一个高级抽象-离散化流DStream,将每个时间段的数据封装为一个RDD,这些RDD的序列构成了DStream,因此称为DStream。它可以由数据源创建,也可以在其他的DStream通过高阶操作来得到。
2、特点
- 优点:易用、容错、易整合到spark体系中
- 缺点:相对于一次处理一条的架构,会有一些延迟
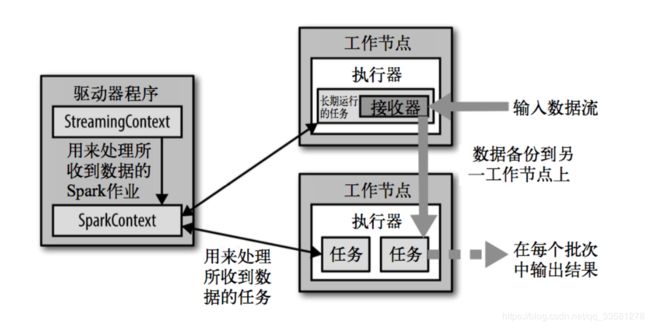
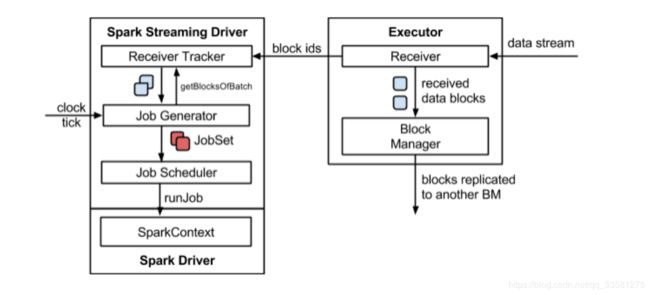
3、架构
背压机制:1.5版本之前,用户限制接收策略只能通过设置静态配制参数“spark.streaming.receiver.maxRate”的值来实现,此举虽然可以通过限制接收速率,来适配当前的处理能力,防止内存溢出,但也会引入其它问题,造成资源利用率不高;1.5之后可以动态控制数据接收速率来适配集群数据处理能力,背压机制(即Spark Streaming Backpressure): 根据JobScheduler反馈作业的执行信息来动态调整Receiver数据接收率。通过属性“spark.streaming.backpressure.enabled”来控制是否启用backpressure机制,默认值false,即不启用。
二、DStream入门
val conf: SparkConf = new SparkConf().setAppName("SPD").setMaster("local[*]")
val ssc = new StreamingContext(conf,Seconds(2))
val rids: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop101",9999)
val words: DStream[String] = rids.flatMap(_.split(" "))
val wordCount: DStream[(String, Int)] = words.map((_,1)).reduceByKey(_+_)
wordCount.print
ssc.start()
ssc.awaitTermination()三、DStream创建
1、RDD队列创建
val conf: SparkConf = new SparkConf().setAppName("spd").setMaster("local[*]")
val ssc = new StreamingContext(conf,Seconds(3))
val queueRDD = new mutable.Queue[RDD[String]]()
val rddDS: InputDStream[String] = ssc.queueStream(queueRDD)
val res: DStream[(String, Int)] = rddDS.map((_,1)).reduceByKey(_+_)
res.print
ssc.start()
for (i <- 1 to 7){
queueRDD.enqueue(ssc.sparkContext.makeRDD(List("3","2","2","1")))
}
ssc.awaitTermination()2、自定义数据源
class MyDSource(host: String, port: Int) extends Receiver[String](StorageLevel.MEMORY_ONLY) {
private var socket: Socket = _
override def onStart(): Unit = {
new Thread("Socket Receiver") {
setDaemon(true)
override def run() {
receive()
}
}.start()
}
override def onStop(): Unit = {
synchronized {
if (socket != null) {
socket.close()
socket = null
}
}
}
def receive() {
try {
socket = new Socket(host, port)
val reader = new BufferedReader(new InputStreamReader(socket.getInputStream,StandardCharsets.UTF_8))
var input:String = null
while ((input = reader.readLine()) != null){
store(input)
}
} finally {
onStop()
}
}
}3、kafka数据源
版本选型
- Receiver API:需要一个专门的Exector对kafka数据进行收集,收集好后再由Exector进行处理。当Exector处理速度跟不上收集速度时,可能会内存溢出
- Direct API:由Exector去消费kafka对应分区的数据,计算速度由自身控制,尤其在1.5之后增加背压机制,可以很好的控制消费的速度
0-8 Receiver模式
由一个exector负责收集kafka的数据,偏移量存储在zk中;当处理线程停止后重启,停止期间的kafka数据会延迟消费
val con: SparkConf = new SparkConf().setMaster("local[*]").setAppName("spd")
val ssc = new StreamingContext(con,Seconds(2))
val receiverInput: ReceiverInputDStream[(String, String)] = KafkaUtils.createStream(ssc,
"hadoop101:2181,hadoop102:2181,hadoop103:2181/kafka",
"consumerDS",
Map[String, Int]("DsTopic"-> 2)
)
val res: DStream[(String, Int)] = receiverInput.map(_._2).flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
res.print()
ssc.start()
ssc.awaitTermination()0-8 Direct模式
- 方式一:自动维护offset,可能丢失数据
- 方式二:使用检查点维护offset,会产生小文件,并且会出现收集不到的时间段(DStream停止期间)
- 方式三:自己维护offset,借助mysql
object SpaekStreaming_DirectDemo_1_2_3 {
def main(args: Array[String]): Unit = {
//方式一:
//val conf: SparkConf = new SparkConf().setAppName("spd").setMaster("local[*]")
//val ssc = new StreamingContext(conf,Seconds(2))
//
//val kafkaParams: Map[String, String] = Map[String, String](
// ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "hadoop101:9092,hadoop102:9092,hadoop103:9092",
// ConsumerConfig.GROUP_ID_CONFIG -> "consumerDS"
//)
//
//val inDS: InputDStream[(String, String)] = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc,
// kafkaParams,
// Set("DsTopic")
//)
//val res: DStream[(String, Int)] = inDS.map(_._2).flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
//res.print()
//方式二
//val checkPoint = "D:\\ideaWorkspace\\scala0105\\sparkd-stream\\cp"
//val ssc: StreamingContext = StreamingContext.getActiveOrCreate(checkPoint,getSSC)
//方式三
val conf: SparkConf = new SparkConf().setAppName("spd").setMaster("local[*]")
val ssc = new StreamingContext(conf,Seconds(2))
val kafkaParams: Map[String, String] = Map[String, String](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "hadoop101:9092,hadoop102:9092,hadoop103:9092",
ConsumerConfig.GROUP_ID_CONFIG -> "consumerDS"
)
val fromOffsets: Map[TopicAndPartition, Long] = Map[TopicAndPartition, Long](
TopicAndPartition("DsTopic", 0) -> 0L,
TopicAndPartition("DsTopic", 1) -> 0L
)
val scc: InputDStream[String] = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder, String](ssc,
kafkaParams,
//fromOffsets,
getTopAndPartition,
(m:MessageAndMetadata[String,String]) => m.message()
)
var offsetRanges = Array.empty[OffsetRange]
scc.transform(
rdd => {
offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
rdd
}
).foreachRDD(
rdd => {
for (elem <- offsetRanges) {
val partition: Int = elem.partition
val topic: String = elem.topic
val from: Long = elem.fromOffset
val to: Long = elem.untilOffset
setTopicAndPartition(topic,partition,from,to)
//println("partition:" + partition + " topic:" + topic + " from:" + from + " to:" + to)
}
}
)
ssc.start()
ssc.awaitTermination()
}
def getTopAndPartition(): Map[TopicAndPartition,Long] ={
val conf = new SparkConf().setAppName("sparkSQL").setMaster("local[*]")
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
val frame: DataFrame = spark.read.format("jdbc")
.option("url", "jdbc:mysql://hadoop101:3306/test")
.option("driver", "com.mysql.jdbc.Driver")
.option("user", "root")
.option("password", "000000")
.option("dbtable", "topicAndPartition").load()
var map: Map[TopicAndPartition, Long] = Map[TopicAndPartition,Long]()
val rows: Array[Row] = frame.collect()
for (elem <- rows) {
map = map + (TopicAndPartition(elem.getString(0),elem.getString(1).toInt) -> elem.getLong(3))
}
if (map.isEmpty){
map = Map[TopicAndPartition, Long](
TopicAndPartition("DsTopic", 0) -> 0L,
TopicAndPartition("DsTopic", 1) -> 0L
)
}
map
}
def setTopicAndPartition(topic: String,partition: Int,from: Long,to: Long): Unit ={
val conf = new SparkConf().setAppName("sparkSQL").setMaster("local[*]")
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
import spark.implicits._
val rdd: RDD[topicAndPartition] = spark.sparkContext.makeRDD(List(topicAndPartition(topic,partition,from,to)))
rdd.toDS().write.format("jdbc")
.option("url","jdbc:mysql://hadoop101:3306/test")
.option("driver","com.mysql.jdbc.Driver")
.option("user","root")
.option("password","000000")
.option("dbtable","topicAndPartition").mode(SaveMode.Overwrite).save()
}
def getSSC(): StreamingContext ={
val conf: SparkConf = new SparkConf().setAppName("spd").setMaster("local[*]")
val ssc = new StreamingContext(conf,Seconds(2))
ssc.checkpoint("D:\\ideaWorkspace\\scala0105\\sparkd-stream\\cp")
val kafkaParams: Map[String, String] = Map[String, String](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "hadoop101:9092,hadoop102:9092,hadoop103:9092",
ConsumerConfig.GROUP_ID_CONFIG -> "consumerDS"
)
val inDS: InputDStream[(String, String)] = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc,
kafkaParams,
Set("DsTopic")
)
val res: DStream[(String, Int)] = inDS.map(_._2).flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
res.print()
ssc
}
}
case class topicAndPartition(topic:String,partition:Int,from:Long,to:Long)0-10 Direct模式
val conf: SparkConf = new SparkConf().setAppName("apd").setMaster("local[*]")
val ssc = new StreamingContext(conf,Seconds(3))
val kafkaParams: Map[String, Object] = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "hadoop101:9092,hadoop102:9092,hadoop103:9092",
ConsumerConfig.GROUP_ID_CONFIG -> "spark010",
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer",
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"
)
val inputStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String,String](Set("DsTopic"), kafkaParams)
)
val res: DStream[(String, Int)] = inputStream.map(_.value()).flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
res.print()
ssc.start()
ssc.awaitTermination()四、DStream转换
在DStream运行的时候,每个时间间隔内也是DStream,内部可以看作是RDD对数据进行计算。有状态可以看作是内部两个DStream之间数据可见,无状态则是每个DStream间数据不可见。
无状态转换:
trannsform:将DStream内的数据转换成RDD,可以进行更方便的操作RDD算子
//transform 算子
val res0: DStream[(String, Int)] = inputDS.transform(
rdd => {
rdd.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).sortByKey()
}
)
res0.print()有状态转换:
UpdateStateByKey:在已经的数据上进行累加,需要增加检查点、只适用于k-v类型的数据
//updateStateByKey 算子
ssc.checkpoint("D:\\ideaWorkspace\\scala0105\\sparkkafka010\\cp")
val res1: DStream[(String, Int)] = res0.updateStateByKey(
(seq: Seq[Int], state: Option[Int]) => {
val res: Int = seq.sum + state.getOrElse(0)
Option(res)
}
)
res1.print()window函数:窗口操作,规定计算的时间间隔和滑动的步长
val windowDS: DStream[String] = inputDS.window(Seconds(6),Seconds(2))
val res2: DStream[(String, Int)] = windowDS.transform(
rdd => {
rdd.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
}
)
res2.print()
ssc.checkpoint("D:\\ideaWorkspace\\scala0105\\sparkkafka010\\cp")
val res3: DStream[Long] = inputDS.countByWindow(Seconds(6),Seconds(2))
res3.print()
val ds1: DStream[(String, Int)] = inputDS.map((_,1))
ssc.checkpoint("D:\\ideaWorkspace\\scala0105\\sparkkafka010\\cp")
val res4: DStream[((String, Int), Long)] = ds1.countByValueAndWindow(Seconds(6),Seconds(2))
res4.print()
val ds2: DStream[(String, Int)] = inputDS.map((_,1))
ssc.checkpoint("D:\\ideaWorkspace\\scala0105\\sparkkafka010\\cp")
val res5: DStream[(String, Int)] = ds2.reduceByKeyAndWindow(
(i1:Int,i2:Int) =>{
i1+i2
},
Seconds(6),
Seconds(2))
res5.print()
val ds3: DStream[(String, Int)] = inputDS.map((_,1))
ssc.checkpoint("D:\\ideaWorkspace\\scala0105\\sparkkafka010\\cp")
val res6: DStream[(String, Int)] = ds3.reduceByKeyAndWindow(
(i1: Int, i2: Int) => {
i1 + i2
},
(i1: Int, i2: Int) => {
i1 - i2
},
Seconds(6),
Seconds(2)
)
res6.print()
五、DStream输出
- print():用于测试,格式化输出
- saveAsTextFile(prefix,[suffix])、saveAsObjectFiles(prefix, [suffix])、saveAsHadoopFiles(prefix, [suffix]):为保存的文件规定前缀和后缀
- foreachRDD():自定义函数处理DStream中的数据
object SparkStreaming_foreachRDD_MYSQL {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("pwd")
val ssc = new StreamingContext(conf, Seconds(2))
val inpurDstream: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop101", 9990)
val mapDS: DStream[(String, Int)] = inpurDstream.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
mapDS.foreachRDD(
rdd => {
rdd.foreachPartition(
datas => {
//获取mysql连接
val connection: Connection = getMySqlConnection
datas.foreach {
case (word, sum) => {
val sql = "insert into wc values('" + word + "','" + sum + "')"
val statement: PreparedStatement = connection.prepareStatement(sql)
statement.executeUpdate()
}
}
connection.close()
}
)
}
)
ssc.start()
ssc.awaitTermination()
}
def getMySqlConnection: Connection = {
val connection = "jdbc:mysql://hadoop101:3306/test"
val driver = "com.mysql.jdbc.Driver"
val user = "root"
val password = "000000"
var conn: Connection = null
try {
Class.forName(driver)
conn = DriverManager.getConnection(connection, user, password)
} catch {
case _: Exception => 0
}
conn
}
}六、DStream编程进阶
- 累加器和广播变量:和RDD中使用一致
- Caching和Presistence:和RDD中使用一致
- DataFrame和SQL Operations:在DStream中使用spark sql
//缓存
inputDS.cache()
inputDS.persist(StorageLevel.MEMORY_ONLY)
//累加器
ssc.sparkContext.longAccumulator("acc")
//广播变量
ssc.sparkContext.broadcast(2)
//使用spark sql
inputDS.foreachRDD(
rdd => {
val spark: SparkSession = SparkSession.builder().getOrCreate()
import spark.implicits._
val frame: DataFrame = rdd.toDF("word")
frame.createOrReplaceTempView("temp")
spark.sql("select * from temp").show()
}
)