Spark常见报错与问题解决方法
1. org.apache.spark.SparkException: Kryo serialization failed: Buffer overflow
原因:kryo序列化缓存空间不足。
解决方法:增加参数,--conf spark.kryoserializer.buffer.max=2047m。
2. org.elasticsearch.hadoop.rest.EsHadoopNoNodesLeftException: Connection error
原因:此时es.port可能为9300,因为ElasticSearch客户端程序除了Java使用TCP方式连接ES集群以外,其他语言基本上都是使用的Http方式,ES客户端默认TCP端口为9300,而HTTP默认端口为9200。elasticsearch-hadoop使用的就是HTTP方式连接的ES集群。
解决方法:可以将es.port设置为 9200。
3. Error in query: nondeterministic expressions are only allowed in Project, Filter, Aggregate or Window, found
解决方法:如果是SparkSQL脚本,则rand()等函数不能出现在join...on的后面。
4. driver端日志中频繁出现:Application report for application_xxx_xxx (stage: ACCEPTED)
解决方法:通过yarn UI左侧的“Scheduler”界面,搜索自己任务提交的yarn队列,查看资源是否用完,与同队列同事协调资源的合理使用,优化资源使用量不合理的任务,如下所示:
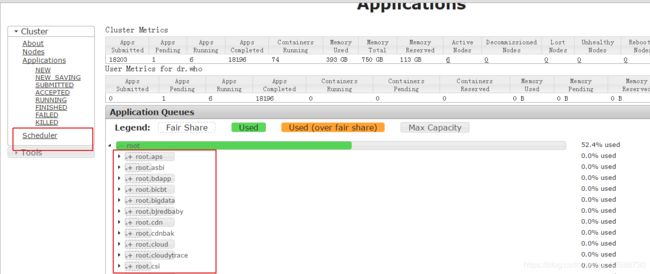
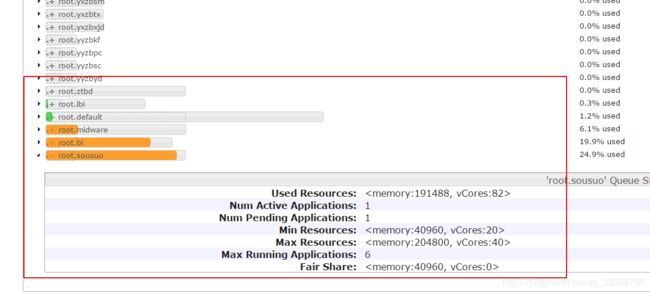
5. Spark任务数据量过大(如上百亿条记录)跑不过去
原因:数据量过大导致executor内存扛不住那么多数据。
解决方法:增加参数,--conf spark.shuffle.spill.numElementsForceSpillThreshold=2000000,将过量数据写入到磁盘中。
6. user clas threw exeception:ml.dmlc.xgboost4j.java.XGBoostError:XGBoostModel trained failed, caused by Values to assemble cannot be null
原因:机器学习训练数据中有为null的地方。
解决方法:把数据中有null的地方去掉,或对null值先进行预处理再训练。
7. Caused by: org.apache.spark.sql.catalyst.parser.ParseException: Datatype void is not supported
原因:Spark不支持Hive表中的void字段类型,代码中临时create的Hive表中,如果from的源表中某字段为全空值,则create table时该临时表的这个字段类型就会变成void。
解决方法:如果是上面这种情况,可以用Hive跑任务或者修改该Hive表的字段类型不为void,或将null转换为string等。
8. ERROR SparkUI: Failed to bind SparkUI java.net.BindException: Address already in use: Service failed after 16 retries
原因:Spark UI端口绑定尝试连续16个端口都已被占用。
解决方法:可以把spark.port.maxRetries参数调的更大如128。
9. Error in Query: Cannot create a table having a column whose name contains commas in Hive metastore
解决方法:查看SparkSQL脚本中是否存在类似于“round(t1.sim_score , 5)”这种以函数结果作为字段值的语句,后面如果没加“as”别名会导致该错误。
10. Fail to send RPC to ...
原因:数据量过大超出默认参数设置的内存分配阈值,container会被yarn杀掉,其他节点再从该节点拉数据时,会连不上。
解决方法:可以优化代码将过多的连续join语句(超过5个)拆分,每3个左右的连续join语句结果生成一个临时表,该临时表再和后面两三个连续join组合,再生成下一个临时表,并在临时表中提前过滤不必要的数据量,使多余数据不参与后续计算处理。只有在代码逻辑性能和参数合理的前提下,最后才能增加--executor-memory、--driver-memory等资源,不能本末倒置。
11. ERROR shuffle.RetryingBlockFetcher: Failed to fetch block shuffle_7_18444_7412, and will not retry
原因:Executor被kill,无法拉取该block。可能是开启AE特性时数据倾斜造成的,其他executor都已完成工作被回收,只有倾斜的executor还在工作,拉取被回收的executor上的数据时可能会拉不到。
解决方法:如果确实是发生了数据倾斜,可以根据该链接的方法进行处理:http://www.jasongj.com/spark/skew/,也可以根据业务逻辑对关键字段加上distribute by语句进行哈希分发来缓解;如果是Spark3以上,或者公司平台的spark2.x源码中定制合入了社区的AE特性,也可以加上这两个参数自动缓解:set spark.sql.adaptive.join.enabled=true和set spark.sql.adaptive.enabled=true。
12. org.apache.spark.memory.SparkOutOfMemoryError: Unable to acquire 65536 bytes of memory, got 0
原因:代码逻辑或任务参数配置不合理、数据倾斜等导致OOM。
解决方法:(1)查看代码中是否有coalesce()等函数,该函数相比repartition()不会进行shuffle,处理大分区易造成OOM,如果有则可换成repartition(),尽量减少coalesce()的使用;或者是否使用了把所有结果聚集到driver的collect()函数,尽量用load()代替。(2)代码中是否有超过5个连续join等不合理的代码逻辑,代码解析与相关对象序列化都是在driver端进行,过于冗余复杂不拆分的代码会造成driver OOM,可参考第10点优化。(3)查看任务提交参数中--executor-cores与--executor-memory的比例是否至少为1:4,一个executor上的所有core共用配置的executor内存,如果有类似2core4G等情况存在,在数据量较大的情况下易OOM,至少应是1core4G或者2core8G等。(4)个别executor的OOM也是数据倾斜会出现的现象之一,如果是这种情况可参考第11点解决。(5)在代码逻辑和参数合理的前提下,最后一步才是增加资源,例如--executor-memory=8g。
13. Caused by: Java.lang.ClassCastException:org.apache.hadoop.io.IntWritable cannot be cast to org.apache.hadoop.io.DoubleWritable
原因:下游Hive表在select from上游Hive表时,select的同名字段的类型不同。
解决方法:修改该下游Hive表的对应字段类型与上游表一致,alter table xxx change 原字段名 新字段名(可不变) 类型;
14. driver端频繁出现“Full GC”字样或“connection refused”等日志内容。
原因:与第12点OOM类似,driver端此时内存压力很大,无力处理与executor的网络心跳连接等其他工作。
解决方法:(1)查看是否有过于复杂不拆分不够优化的代码逻辑(如过多连续join),可参考第10点将不合理的代码拆分精简,在临时表中尽早过滤多余数据。(2)如果数据量确实十分巨大,并非代码不够合理的原因,可以减小SparkSQL的broadcast join小表阈值甚至禁用该功能,增加参数set spark.sql.autoBroadcastJoinThreshold=2048000或-1等(默认为10M,根据具体数据量调整)。(3)改过代码也合理调参过了,最后才是增加driver端内存,--driver-memory=4g等。
15. Caused by: org.apache.spark.SparkException: This RDD lacks a SparkContext. It could happen in the following cases:(1) RDD transformations and actions are NOT invoked by the driver, but inside of other transformations; for example, rdd1.map(x => rdd2.values.count() * x) is invalid because the values transformation and count action cannot be performed inside of the rdd1.map transformation. For more information, see SPARK-5063.(2) When a Spark Streaming job recovers from checkpoint, this exception will be hit if a reference to an RDD not defined by the streaming job is used in DStream operations. For more information, See SPARK-13758.
原因:根据上面英文提示的原因,对RDD进行嵌套处理可能会导致此报错。
解决方法:将RDD从复杂嵌套逻辑中拿出来用关联写法即可。
16. removing executor 38 because it has been idle for 60 seconds
原因:一般为数据倾斜导致,开启AE特性后空闲下来的executor会被回收。
解决方法:与第11与第12点的解决方法类似,第10、11、12、16、17点的日志现象可能会有某几种同时出现。
17. Container killed by YARN for exceeding memory limits. 12.4 GB of 11GB physical memory used.
原因:(1)数据倾斜,个别executor内存占用非常大超出限制。(2)任务小文件过多,且数据量较大,导致executor内存用光。(3)任务参数设置不合理,executor数量太少导致压力负载集中在较少的executor上。(4)代码不合理,有repartition(1)等代码逻辑。
解决方法:(1)数据倾斜情况可以参考第11、12点。(2)数据量很大可参考第10、14点。(3)查看是否任务参数设置不合理,例如executor-memory是设的大,但是--num-executors设置的很少才几十个,可以根据集群情况和业务量大小合理增大executor数。(4)查看代码中是否有如repartition(1)等明显不合理的逻辑。(5)在代码性能与逻辑合理,且参数合理的前提下再增加资源,可增加对外内存:--conf spark.yarn.executor.memoryOverhead=4096(单位为M,根据业务量情况具体设置)。
18. Found unrecoverable error returned Bad Request - failed to parse; Bailing out
原因:ES中有历史索引没删除。
解决方法:删除ES中的对应历史索引。
19. org.apache.spark.shuffle.FetchFailedException: Too large frame
原因:shuffle中executor拉取某分区时数据量超出了限制。
解决方法:(1)根据业务情况,判断是否多余数据量没有在临时表中提前被过滤掉,依然参与后续不必要的计算处理。(2)判断是否有数据倾斜情况,如果是则参考第11、12点,或者通过repartition()进行合理重分区,避免某个分区内数据量过大。(3)判断--num-executors即executor数量是否过少,可以合理增加并发度,使数据负载不集中于少量executor上,减轻压力。
20. 读写Hive表时报“table not found”,但实际上Hive表在元数据库与HDFS上都存在。
解决方法:排除不是集群连接地址配置等原因后,查看代码中SparkSession建立时是否有加enableHiveSupport(),没加可能会无法识别到Hive表。
21. java.io.FileNotFoundException
原因:(1)除文件确实在对应HDFS路径上不存在以外,可能代码中前面有create view但数据来源于最后要insert的目标表,后面insert overwrite 目标表时又from这个view,因为Spark有“谓词下推”等懒执行机制,实际开始执行create view的transformation操作时,因为前面insert overwrite目标表删了目标表上的文件,所以相当于自己查询自己并写入自己,会造成要读的文件不存在。(2)由于Spark的内存缓存机制,短时间内该目录下文件有变动但缓存中的元信息未及时同步,依然以为有该文件,Spark会优先读取缓存中的文件元信息,如果和实际该目录下的文件情况不一致也会报错。
解决方法:(1)如果是上述的代码逻辑,可以不用create view,而是创建临时表落到磁盘,insert目标表时from临时表就可以了。(2)可以在读写代码前面加上refresh table 库名.表名,这样就丢弃了该缓存信息,依然从磁盘实际文件情况来读。
22. org.apache.shuffle.FetchFailedException: Connect from xxx closed
原因:一般是数据倾斜导致,其他executor工作完成因闲置被回收,个别负载大的executor拉其他executor数据时拉不到。
解决方法:可参考第11点,加上参数,set spark.sql.adaptive.join.enabled=true和set spark.sql.adaptive.enabled=true,并根据业务数据量合理设置spark.sql.adaptiveBroadcastJoinThreshold即broadcast join的小表大小阈值。
23. caused by:org.apache.hadoop.hbase.client.RetriesExhaustedException: Can't get the locations
原因:如果地址配置等都正确,一般就是大数据平台对HBase组件的连接并发数有限制,导致大量SparkSQL任务连接HBase时有部分任务会连接超时。
解决方法:检查代码与任务中的HBase连接配置等属性是否正确,若正确则直接请教负责HBase组件的平台开发人员。
24. sparksql在某个stage长时间跑不动,但task很少,数据量也不大,且代码逻辑只是简单的join,如下现象所示:

原因:点进该stage的链接查看细节现象,发现stage中各task的shuffle read数据量不大,但shuffle spill数据量大得多,如下所示:
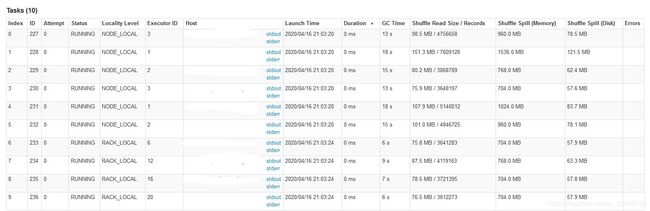
可以判定该join操作可能发生了笛卡尔积,join on中的两个字段各自都有很多重复值不唯一,会导致这种情况。
解决方法:加上参数,set spark.sql.adaptive.shuffle.targetPostShuffleInputSize=64000000能够缓解这种现象,根本上依然是根据业务逻辑进行字段值去重、避免重复字段值参与join等。
25. ERROR:Recoverable Zookeeper: Zookeeper exists failed after 4 attempts baseZNode=/hbase Unable to set watcher on znode (/hbase/...)
原因:Spark任务连接不上HBase,如果不是任务中连接参数和属性等配置的有问题,就是HBase组件限制了连接并发数。
解决方法:可参考第23点的解决方法。
26. Parquet record is malformed: empty fields are illegal, the field should be ommited completely instead
原因:数据中有Map或Array数组,其中有key为null的元素。
解决方法:增加处理key为null数据的逻辑(如将key转换为随机数或干脆丢弃该条数据),或使用ORC格式。
27. Java.io.IOException: Could not read footer for file
原因:该报错分为两种情况:(1)虽然建表时,该hive表元信息设置的是parquet格式,但是实际写入后,对应目录里面的文件并不是parquet格式的;(2)读到的这个文件是个空文件。
解决方法:(1)如果对应文件在HDFS上查看后发现不是parquet格式,可以重建对应格式的表并把文件移到新表对应目录下,或者正确修改代码配置重跑一次任务,从而删除文件覆盖写入;(2)如果是空文件,可以直接删掉该文件。
28. com.mysql.jdbc.exceptions.jdbc4.CommunicationsException:Communications link failure
原因:查看报该错误的executor日志上发现有Full GC,Full GC会导致所有其他线程暂停,包括维持MySQL连接的线程,而MySQL在一段时间连接无响应后会关闭连接,造成连接失败。
解决方法:可参考第14点方法解决。