数据库笔记(一)
一、数据库基本概念
数据:数据是人们用各种物理符号,把信息按一定格式记载下来的有意义的符号组合。数据不仅仅是数字,还可以是文字、图象、声音等各种表现形式。数据经数字化后可以存入计算机中,是数据库中存储的基本对象。数据和它的语义是不可分割的。
数据库(DB):以一定的方式保存在计算机存储设备上的相互关联、可共享的数据的集合。
数据库管理系统 (DBMS):执行数据库管理任务所需的软件。
数据库管理员:数据库的建立、使用和维护只靠DBMS是不够的,还需要有专门的人员来完成,这些人员称为数据库管理员。
空值(NULL):表示某个属性取值为未知。由于查询语句中使用IS NULL会影响效率,设计数据库时应尽量避免使用NULL值。
二、数据模型
数据模型 是现实世界数据特征的抽象。
数据模型通常由数据结构、数据操作和完整性约束三部分组成。
在用户观点下,关系模型中数据的逻辑结构是一张二维表,它由行和列组成。
(1) 关系: 一个关系对应于一张二维表。
(2) 关系名: 如“Student” 。
(3) 元组: 表中的一行,对应于存储文件中的一个记录。
(4) 属性: 表中的一列。
(5) 属性名: 给每个属性起一个名字。对应于存储文件中的字段。
(6)候选码:如果在一个关系中,存在属性(或属性组合)能唯一地决定关系中其他所有属性的值,而其任何真子集无此性质,则这个属性(或属性组合)都称为该关系的候选码(或候选关键字)。
StuID |
StuName |
StuAge |
DepID |
12001 |
mary |
21 |
1 |
12002 |
tom |
20 |
2 |
12003 |
jack |
19 |
3 |
12004 |
nancy |
22 |
1 |
如果:姓名没有重名现象,则学号和姓名都是候选码。
(7)主码(主键):在若干个候选码中指定作为码的属性(或属性组合)称为该关系的主码(或主关键字 即 主键)。(可以有多个属性)
注:主键不允许存放空值,一张表只允许存在一个主键。
(8)全码: 如果一个关系模型的所有属性一起构成该关系的码(主键),则称为全码。Books(StuID,BookID,BorrowTime)
(9)主属性: 包含在候选码中的属性。如学号。(候选码,能唯一决定其他属性的值)
(10)非主属性: 不包含在任何候选码中的属性称为非码属性或非主属性。如性别和年龄。
(11)域:属性的取值范围。
如,性别域: (男、女),年龄域: 大于0的整数。
(12)分量:元组中的一个属性值。如“李明”。
(13)关系模式:对关系的描述。一般表示为:
关系名(属性1,属性2,…,属性n)
例如, “Student”表表示为:
Student(StuID,StuName,StuAge,DepID)
三、关系的完整性约束
1.实体完整性
2.引用完整性
3.域完整性
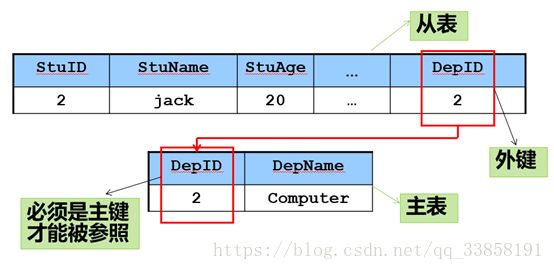
四、关系运算
每个关系运算将一到两个关系做为输入,并产生一个新关系做为输出。
关系运算主要有:
(1)并运算(Union):关系R和S具有相同的属性及域,它们的并运算将产生一个新关系,新关系具有和R,S相同的数据及域,新关系中包含R,S中所有元组(不重复)。记作:R ∪S
(2)交运算(Intersect): 关系R和S具有相同的属性及域,它们的交运算将产生一个新关系,新关系具有和R,S相同的数据及域,新关系包含同时出现在R,S中的元组。记作:
R ∩ S
(3)差运算(Difference):关系R和S具有相同的属性及域,它们的差运算将产生一个新关系,新关系具有和R,S相同的数据及域,新关系包含所有属于R但不属于S的元组。记作:R-S
(4)笛卡尔积(Product):设关系R为n列,k1行,关系S为m列,k2行,则关系R和S的笛卡尔积,是R中每个元组和S中每个元组连接产生的新关系。记作:R×S
注:新关系中属性的个数为n+m,元组的个数为k1×k2.
(5)除运算(Divide):
R ÷ S步骤:
1. 判断除法运算后关系的属性结构:
为R的关系属性与S的关系属性做差运算。
2. 针对步骤1获取的属性,找出属性在关系R中的取值情况:
R中所有取值情况
3.计算每种取值在关系R上的象集:
R上的象集:象集属性由关系R和关系S的交集组成
4. 计算关系R和S的属性交集在关系S上的取值情况:
属性交集在关系S上的取值情况
注:(当提出查询“全部”、“所有”、“至少”这样的关键字时可以考虑使用除法)
5. 判断哪个象集包含了步骤4的结果,则该取值满足结果:
即R上的象集属性值包含了步骤4的结果,就是R ÷ S(属性为步骤一)
注:当提出查询“全部”,“所有”,“至少”这样的关键字时可以考虑使用除法解决。
(6)选择运算
选择操作符是根据某个条件从给定的关系中抽取指定的元组或行。
σDepName= 'IS' AND StuAge < 20(Student)
(相当于where子句)
(7) 投影运算
投影操作符是给定关系中抽取指定的属性和列。删去某些元组(避免重复行)
πStuName,DepName(Student)
(相当于select子句)
(8)连接运算
连接运算符从两个指定的关系构建一个关系。此关系包括两个关系中满足指定条件的元组的所有可能组合。
自然连接还需要取消重复列
![]()
注:(能匹配的则匹配,匹配不上的不出现在结果集;连接运算最耗费代价,应以尽量少的数据参与连接运算)
五、E-R模型
E-R图称为实体-联系图,是一种用来描述实体与实体之间联系的数据模型。E-R模型是一种概念模型。
每一个实体可以用一个关系表来表示。
一个遵循E-R图的数据库在关系系统里可以表示为一组表。
弱实体:
这种实体不能存在,总是依附于某个实体,因此称之为弱实体。
(1)一对一关系的转换
规则:每个实体对应一张表,选中其中一个实体为其添加外键,该外键来自于另一实体的主键。
Student(StuID,StuName,StuAddress,ProjID)
Project(ProjID,ProjName)
(2)一对多关系的转换
规则:每个实体对应一张表,其中“多”对应的实体转换的表添加一个外键,这个外键来自于“一”对应实体的主键。
Department(DepID,DepName)
Student(StuID,StuName,StuAddress,DepID)
(3)多对多关系的转换
规则:每个实体对应一张表,其中“关系”也对应一张表,“关系”对应的表中选择两个实体的主键组合作为“关系”表中的主键。
Student(StuID,StuName,StuAddress)
Course(CourseID,CourseName,Credit)
SC(StuID,CourseID,Grade)
(4)弱实体的转换
规则:每个实体对应一张表,其中常规实体的主键成为弱实体的外键,同时这个外键也是弱实体的主键或主键的一部分。
Employee(EmpID,EmpName)
Child(EmpID,ChildName,ChildAge)
(5)超类与子类(超类与子类间用“十”字相连。)
规则:每个实体对应一张表,每个子实体引入父实体的主键为自己的外键,同时这个外键又是子实体的主键。
Employee(EmpID,EmpName,EmpAddr)
HourlyEmployee(EmpID,Wages,Hours)
SalariedEmployee(EmpID,Salary,Bonus)
六、数据冗余
1.冗余是数据的重复出现。
2.数据的冗余会导致一些问题:
更新异常:当插入、删除、修改数据时会导致数据的不一致性。
不一致性:当有冗余数据时会导致错误。
不必要的占用多余的空间 。
注意:在数据库设计中,应尽量避免数据冗余,但并不代表没有冗余的设计一定是一个好的设计,有时需要引入冗余提高效率。
好的关系模式:
不会发生插入异常、删除异常、更新异常,
数据冗余应尽可能少。
七、关系模式的范式化
范式化:
范式化是一种科学方法,通过使用某些规则把复杂的表格结构分解为简单的表格结构。
可以降低表中的冗余和消除不一致和磁盘空间利用的问题。
范式用来保证各种类型的不规范和不一致性不会引入到数据库。
函数依赖:
定义1:属性Y函数依赖于X,当且仅当对每一个X,恰有一个Y的值与之对应。属性X被称为决定因子。
x,y满足函数关系y=f(x),记作:x ——>y。含义是x函数确定y,或y函数依赖于x。
定义2:在关系模式中,如果X——>Y,并且对于X的任何一个真子集X’,都有X’ —\—>Y, 则称Y完全函数依赖于X,记作:X—f—>Y。
定义3:若X——>Y,但Y不完全函数依赖于X,则称Y部分函数依赖于X,记作X—P—>Y。
第一范式:
如果表中的每个单元格都是单值的,即表不包含表,则称该表满足第一范式。
第二范式:
每一个非主属性都完全依赖于码,而不是部分依赖于码。
第三范式:
每一非主属性都不传递依赖于关系的候选键,则关系模式为第三范式。
非范式化:
在一个表格中有意义地引入冗余以改进性能被称为非范式化。
Orders(OrderID,ProductId,Qty)
Products(ProductId,Desc,Cost)
八、如何判断关系的候选键
1.首先对于给定的关系模式R(U)和函数依赖集F,可以将它的属性划分为4类:
L类,仅出现在F的函数依赖左部的属性。
R类,仅出现在F的函数依赖右部的属性。
N类,在F的函数依赖左部和右部均未出现的属性。
LR类,在F的函数依赖左部和右部两部均出现的属性。
2.对于给定的关系模式R及其函数依赖集F,根据以下定理和推论来求解候选码。
定理1:若X(X∈R)是L类属性,则X必为R的任一候选码的成员。
定理2:若X(X∈R)是R类属性,则X不在任何候选码中。
定理3:如果X是R的N类属性,则X必包含在R的任一候选码中。
定理4:如果X是R的LR类属性,则需要进一步判断是否是候选码的成员。
3.选中确定的候选码,判断是否能决定其他全部属性,如果是,则确定,否则加入LR类属性继续判断。
4.写出所有非主属性对主键的函数依赖关系。