pytorch基于cifar10实现NIN网络(带注释)
pytorch基于cifar10实现NIN网络
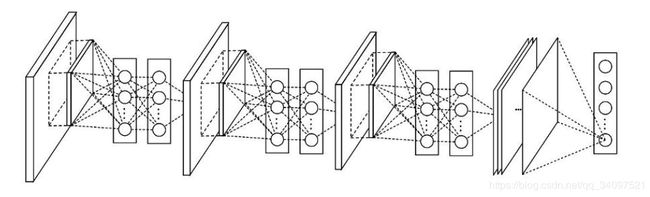
模型Network in network
train.py
#导出需要的库
import torch
import torchvision
import torch.optim as optim
import torchvision.transforms as transforms
import torch.nn as nn
import torch.nn.functional as F
import data
import cPickle as pickle
import numpy
from torch.autograd import Variable
#给定数据集路径,加载数据
trainset = data.dataset(root='./data', train=True)
#该接口会将dataset根据batchsize大小,是否shuffle等封装成一个batchsize大小的tensor
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True, num_workers=2)
#测试数据读取
testset = data.dataset(root='./data', train=False)
testloader = torch.utils.data.DataLoader(testset, batch_size=100,
shuffle=False, num_workers=2)
#数据集总类别数
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
#定义模型
class Net(nn.Module):#继承父类nn.Module
def __init__(self):
super(Net, self).__init__()#super可以指代父类而不需要显式的声明,这对更改基类(此处为__init__())的时候是有帮助的,使得代码更容易维护
self.classifier = nn.Sequential(
nn.Conv2d(3, 192, kernel_size=5, stride=1, padding=2),
nn.ReLU(inplace=True),
nn.Conv2d(192, 160, kernel_size=1, stride=1, padding=0),
nn.ReLU(inplace=True),
nn.Conv2d(160, 96, kernel_size=1, stride=1, padding=0),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
nn.Dropout(0.5),
nn.Conv2d(96, 192, kernel_size=5, stride=1, padding=2),
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=1, stride=1, padding=0),
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=1, stride=1, padding=0),
nn.ReLU(inplace=True),
nn.AvgPool2d(kernel_size=3, stride=2, padding=1),
nn.Dropout(0.5),
nn.Conv2d(192, 192, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=1, stride=1, padding=0),
nn.ReLU(inplace=True),
nn.Conv2d(192, 10, kernel_size=1, stride=1, padding=0),
nn.ReLU(inplace=True),
nn.AvgPool2d(kernel_size=8, stride=1, padding=0),
)
def forward(self, x):
x = self.classifier(x)
#将得到的数据平展
x = x.view(x.size(0), 10)
return x
#实例化模型
model = Net()
#打印
print(model)
#如果想在CUDA上进行计算,需要将操作对象放在GPU内存中。
model.cuda()
#是否预训练
pretrained=False
if pretrained:
#如果使用预训练参数,则加载参数
params = pickle.load(open('data/params', 'r'))
index = -1
#取出权重与偏执值
for m in model.modules():
if isinstance(m, nn.Conv2d):
index = index + 1
weight = torch.from_numpy(params[index])
m.weight.data.copy_(weight)
index = index + 1
bias = torch.from_numpy(params[index])
m.bias.data.copy_(bias)
else:
#初始化参数
for m in model.modules():
if isinstance(m, nn.Conv2d):#使用isinstance来判断m属于什么类型
m.weight.data.normal_(0, 0.05)
m.bias.data.normal_(0, 0.0)
#损失函数
criterion = nn.CrossEntropyLoss()
#参数列表
param_dict = dict(model.named_parameters())
params = []
#基础学习率
base_lr = 0.1
#设置不同层次的学习速率和权重的损失问题
for key, value in param_dict.items():
if key == 'classifier.20.weight':
params += [{'params':[value], 'lr':0.1 * base_lr,
'momentum':0.95, 'weight_decay':0.0001}]
elif key == 'classifier.20.bias':
params += [{'params':[value], 'lr':0.1 * base_lr,
'momentum':0.95, 'weight_decay':0.0000}]
elif 'weight' in key:
params += [{'params':[value], 'lr':1.0 * base_lr,
'momentum':0.95, 'weight_decay':0.0001}]
else:
params += [{'params':[value], 'lr':2.0 * base_lr,
'momentum':0.95, 'weight_decay':0.0000}]
#选择优化器
optimizer = optim.SGD(params, lr=0.1, momentum=0.9)
#训练模型
def train(epoch):
#实例化的model指定train(必做)
model.train()
#批量训练数据
for batch_idx, (data_, target) in enumerate(trainloader):
#数据存入GPU
data, target = Variable(data_.cuda()), Variable(target.cuda())
#将梯度初始化为零(因为一个batch的loss关于weight的导数是所有sample的loss关于weight的导数的累加和),所以每个批次梯度置零
optimizer.zero_grad()
#送入数据得到结果
output = model(data_)
#计算损失值
loss = criterion(output, target)
#反向传播
loss.backward()
#只有用了optimizer.step(),模型才会更新
optimizer.step()
#打印结果
if batch_idx % 100 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}\tLR: {}'.format(
epoch, batch_idx * len(data), len(trainloader.dataset),
100. * batch_idx / len(trainloader), loss.data[0],
optimizer.param_groups[1]['lr']))
#测试模型
def test():
#实例化的model指定eval
model.eval()
#设置初始值
test_loss = 0
correct = 0
#取出测试数据
for data_, target in testloader:
data_, target = Variable(data_.cuda()), Variable(target.cuda())
output = model(data_)
test_loss += criterion(output, target).data[0]
pred = output.data.max(1, keepdim=True)[1]
correct += pred.eq(target.data.view_as(pred)).cpu().sum()
test_loss /= len(testloader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.2f}%)\n'.format(
test_loss * 128., correct, len(testloader.dataset),
100. * correct / len(testloader.dataset)))
#epoch到一定数时调整学习率
def adjust_learning_rate(optimizer, epoch):
if epoch%80==0:
for param_group in optimizer.param_groups:
param_group['lr'] = param_group['lr'] * 0.1
#打印方差值
def print_std():
for m in model.modules():
if isinstance(m, nn.Conv2d):
print(torch.std(m.weight.data))
#循环训练更新
for epoch in range(1, 320):
adjust_learning_rate(optimizer, epoch)
train(epoch)
test()
data.py
#导入需要的库
import os
import torch
import cPickle as pickle
import numpy
import torchvision.transforms as transforms
#定义数据集类
class dataset():
def __init__(self, root=None, train=True):
self.root = root
self.train = train
#将array转为tensor
self.transform = transforms.ToTensor()
#如果train为True,则给定训练数据
if self.train:
#训练数据路径
train_data_path = os.path.join(root, 'train_data')
#训练数据对应标签路径
train_labels_path = os.path.join(root, 'train_labels')
#加载npy数据
self.train_data = numpy.load(open(train_data_path, 'r'))
#numpy中的ndarray转化成pytorch中的tensor
self.train_data = torch.from_numpy(self.train_data.astype('float32'))
self.train_labels = numpy.load(open(train_labels_path, 'r')).astype('int')
else:
#加载测试数据与标签
test_data_path = os.path.join(root, 'test_data')
test_labels_path = os.path.join(root, 'test_labels')
self.test_data = numpy.load(open(test_data_path, 'r'))
self.test_data = torch.from_numpy(self.test_data.astype('float32'))
self.test_labels = numpy.load(open(test_labels_path, 'r')).astype('int')
def __len__(self):
if self.train:
return len(self.train_data)
else:
return len(self.test_data)
def __getitem__(self, index):
if self.train:
img, target = self.train_data[index], self.train_labels[index]
else:
img, target = self.test_data[index], self.test_labels[index]
return img, target