18行代码搞定python爬虫:爬取58同城二手车信息并保存为Excel文件,python小白必看!
hello大家好,
我是你们的可爱丸,
今天我要和大家分享案例是
一个只有18行代码的python爬虫。 麻雀虽小五脏俱全,
麻雀虽小五脏俱全,
大家别看这个案例的代码数量少,
但它却可以同时实现数据爬取和保存功能,
现在你是不是迫不及待的想要学习了呢?
那么接下来我就带着大家一起来详细学习吧!
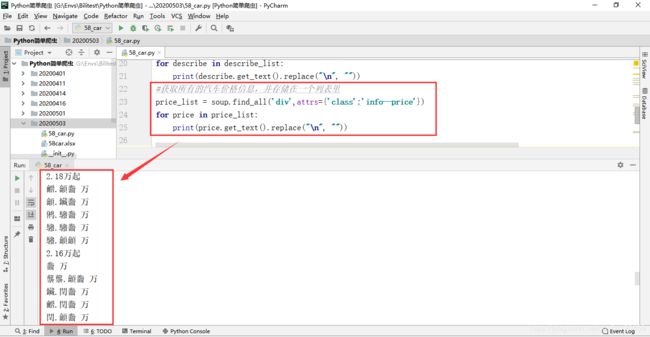
代码运行效果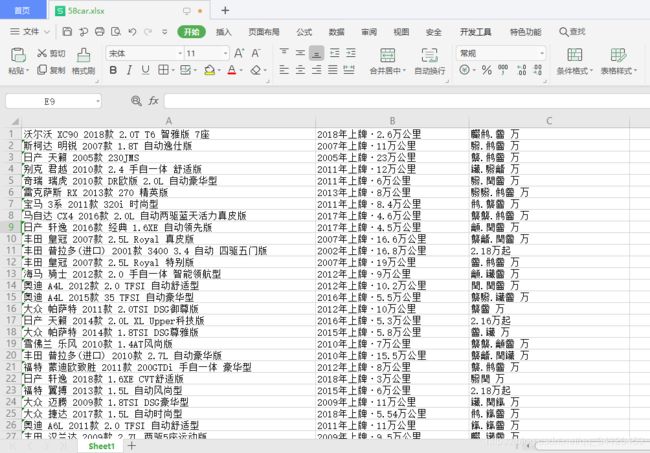
详细教程
1、目标网页及网页数据查看方法
我们今天要爬的网页是58同城的二手车信息页面,地址为:https://nn.58.com/ershouche/?PGTID=0d100000-0034-d9f8-fe87-cbe415320007&utm_source=market&spm=u-2d2yxv86y3v43nkddh1.BDPCPZ_BT&ClickID=56
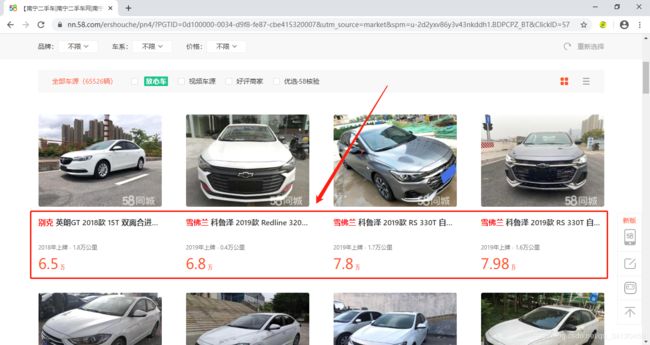
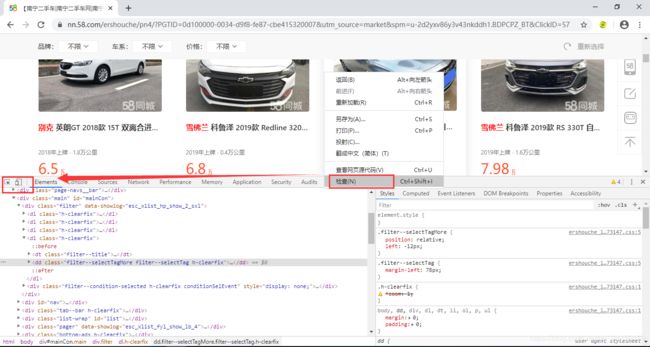
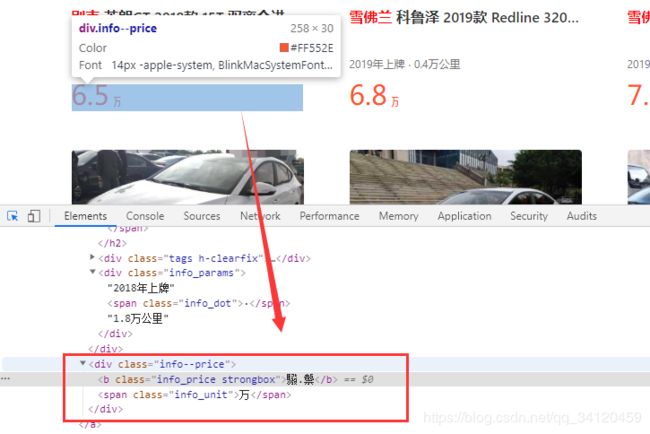
我们需要把目标网页中的二手车名称、描述信息以及价格等信息爬取下来并保存,那么如何查看这些信息呢?查看的方法为:鼠标右键选择检查,然后再点击底部窗口上左上角的小箭头,再把小箭头移到对应信息的位置就可以看到它的对应代码啦,如下图所示:
2、导入需要用到的模块并做数据解析前准备工作
#导入本代码需要用到的模块
import requests
from bs4 import BeautifulSoup
import xlsxwriter
#设置请求头,模仿浏览器访问
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'}
#设置想要爬取的网页链接
url = 'https://nn.58.com/ershouche/?utm_source=market&spm=u-2d2yxv86y3v43nkddh1.
BDPCPZ_BT&PGTID=0d100000-0034-d9f8-fe87-cbe415320007&ClickID=4'
#做数据解析前的准备
response = requests.get(url, headers=headers)
content = response.content
soup = BeautifulSoup(content, 'lxml')
3、获取对应数据
通过BeautifulSoup寻找所有class属性为“info_link”的span标签,并通过get_text()方法获得标签中的所有文本信息
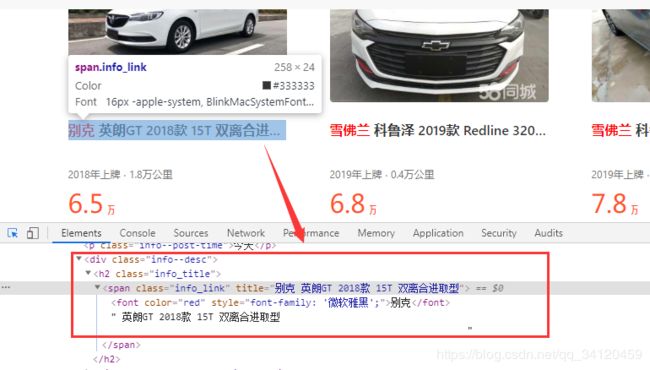
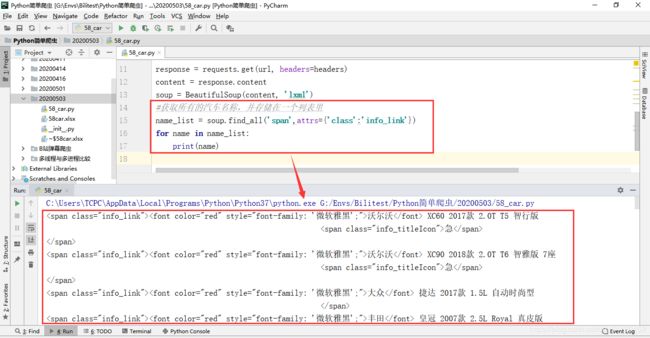
因为文本信息中包含有换行符,为了保证文本的可读性及美观,通过repalce()方法将文本数据中的换行替换为空格。
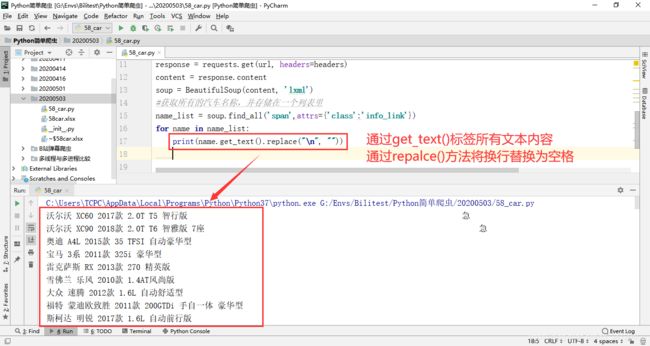
使用同样的方法获得汽车描述信息数据
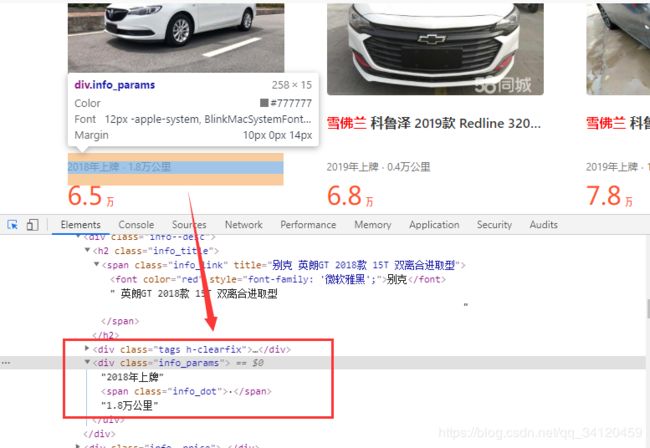
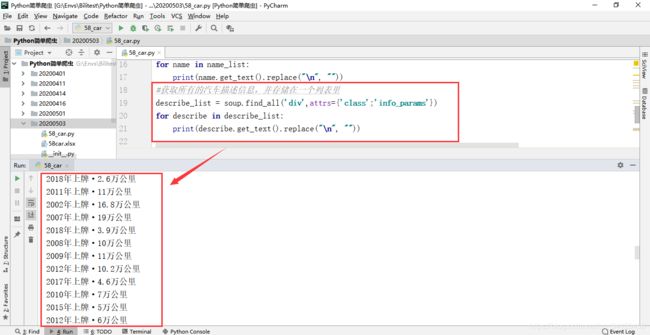
使用同样的方法获得汽车价格信息数据
 4、将数据写入excel并保存
4、将数据写入excel并保存
通过len()方法可以获取到所有汽车信息的数量,再对这些信息进行遍历,逐个写入
excel文件中并保存。
#创建名为58car.xlsx的excel文件
workbook = xlsxwriter.Workbook('58car.xlsx')
#在excel文件中添加一个sheet工作表
worksheet = workbook.add_worksheet()
#获取所有的汽车名称,并存储在一个列表里
name_list = soup.find_all('span',attrs={'class':'info_link'})
#获取所有的汽车描述信息,并存储在一个列表里
describe_list = soup.find_all('div',attrs={'class':'info_params'})
#获取所有的汽车价格信息,并存储在一个列表里
price_list = soup.find_all('div',attrs={'class':'info--price'})
#通过len()方法得到汽车信息个数并进行遍历
for i in range(len(name_list)):
#在第i行第1列写入第i辆汽车的名称
worksheet.write(i, 0, name_list[i].get_text().replace("\n", ""))
# 在第i行第2列写入第i辆汽车的描述信息
worksheet.write(i, 1, describe_list[i].get_text())
# 在第i行第3列写入第i辆汽车的价格信息
worksheet.write(i, 2, price_list[i].get_text().replace("\n", ""))
#数据写入完毕后将表格关闭
workbook.close()
代码运行结束后,会在爬虫文件同级目录下自动创建保存数据的excel表格
5、完整代码
# 微信公众号:chimuyhs 【可爱丸学python】 关注并回复:源码 即可获取源代码
# QQ学习交流群:983460742
#导入本代码需要用到的模块
import requests
from bs4 import BeautifulSoup
import xlsxwriter
#设置请求头,模仿浏览器访问
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'}
#设置想要爬取的网页链接
url = 'https://nn.58.com/ershouche/?utm_source=market&spm=u-2d2yxv86y3v43nkddh1.
BDPCPZ_BT&PGTID=0d100000-0034-d9f8-fe87-cbe415320007&ClickID=4'
response = requests.get(url, headers=headers)
content = response.content
soup = BeautifulSoup(content, 'lxml')
#创建名为58car.xlsx的excel文件
workbook = xlsxwriter.Workbook('58car.xlsx')
#在excel文件中添加一个sheet工作表
worksheet = workbook.add_worksheet()
#获取所有的汽车名称,并存储在一个列表里
name_list = soup.find_all('span',attrs={'class':'info_link'})
#获取所有的汽车描述信息,并存储在一个列表里
describe_list = soup.find_all('div',attrs={'class':'info_params'})
#获取所有的汽车价格信息,并存储在一个列表里
price_list = soup.find_all('div',attrs={'class':'info--price'})
#通过len()方法得到汽车信息个数并进行遍历
for i in range(len(name_list)):
#在第i行第1列写入第i辆汽车的名称
worksheet.write(i, 0, name_list[i].get_text().replace("\n", ""))
# 在第i行第2列写入第i辆汽车的描述信息
worksheet.write(i, 1, describe_list[i].get_text())
# 在第i行第3列写入第i辆汽车的价格信息
worksheet.write(i, 2, price_list[i].get_text().replace("\n", ""))
#数据写入完毕后将表格关闭
workbook.close()
今天的教程就到这里啦,感谢大家的阅读,本教程的初衷是想给python初学者一个练手的机会,因此对于二手车价格乱码以及爬虫分页方面不做处理,如果想了解本案例的优化方法,那么记得关注我哦,我将定期和大家分享python相关知识~我们下次见_