python爬虫实战-抓取同花顺股票信息
前言:
在之前介绍requests的基础上,现在开始进行实战。
目标网站:http://q.10jqka.com.cn//index/index/board/all/field/zdf/order/desc/page/
一 涉及到的技术点:
(1)requests: 用于网页请求
(2)beautifulsoup:用于提取数据
(3)urllib.parse:用于拼接url
(4)cvs:用于保存结果
二 数据结构分析:
首先看下要抓取的数据的外观:
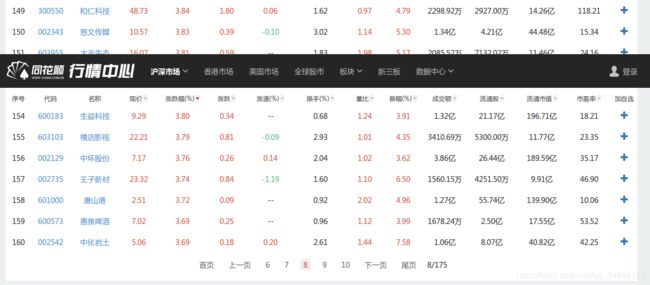
点击下一页发现在搜索框中的url并未发生变化,这个时候可以猜想,其数据加载的方式采用的ajax加载的方式,因此,右键—>“查看元素”,点击网络—>消息头,如下图: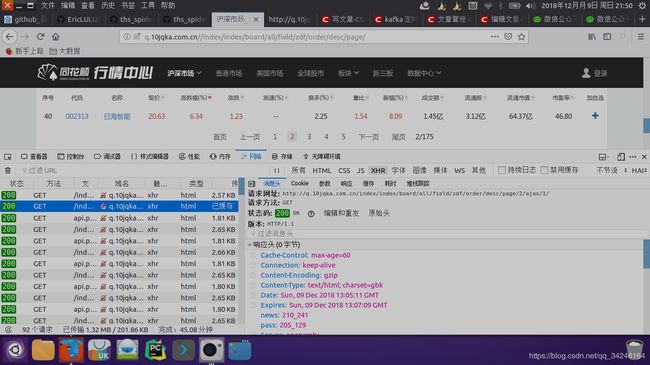
可以发现第二页的url为:http://q.10jqka.com.cn/index/index/board/all/field/zdf/order/desc/page/2/ajax/1/
点击下一页,可以发现第三页的url为:http://q.10jqka.com.cn/index/index/board/all/field/zdf/order/desc/page/3/ajax/1/
从上面可以看出,不同页面的url的区别在于page后面的数字,可以再多看几个页面来验证这个猜想。
通过上面的分析,可以得出数据是通过ajax的方式加载出来的。接下来查看通过ajax加载的数据格式是什么样的。
点击 网络下面的响应,可以看到响应载荷,如下图:
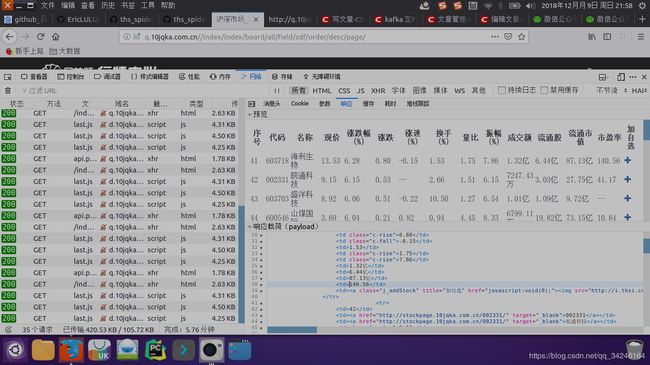
通过url获取到部分数据如下:
序号
代码
名称
现价
涨跌幅(%)
涨跌
涨速(%)
换手(%)
量比
振幅(%)
成交额
流通股
流通市值
市盈率
加自选
41
603718
海利生物
13.53
6.28
0.80
-0.15
1.53
1.75
7.86
1.32亿
6.44亿
87.13亿
140.56

42
002331
皖通科技
9.15
6.15
0.53
--
2.66
1.51
6.15
7247.43万
3.03亿
27.75亿
41.17
可以看到其数据都是包含在html的标签中。一个
标签包含一个股票信息。
至此,数据分析部分已经完成。
三 需求分析及模块划分
同花顺股票网站具有很好的反扒能力,因此,需要增加一部分功能来应对这部分问题。在简单怕爬虫的基础上需要增加,改变请求头和增加代理的功能,因此整个函数的模块划分如下:
(1)代理获取模块
(2)url构建模块
(3)失败无限尝试模块
(4)下载模块
(5)解析及存储模块
(6)配置模块
四 模块设计
4.1 代理获取模块
代码如下:
def proxy_get(self, num_retries=2):
"""
#代理获取模块
"""
try:
r_proxy = requests.get(self.PROXY_POOL_API, timeout = 5)
proxy = r_proxy.text #指定代理
print("代理是", proxy)
proxies = {
"http": 'http://' + proxy,
"https": 'https://' + proxy,
}
return proxies
except:
if num_retries > 0:
print("代理获取失败,重新获取")
self.proxy_get(num_retries-1)
为了防止网络状况不佳等其他原因导致获取代理失败,增加了超时等待和失败重试功能
4.2 url 构建模块
在前文分析的基础上,得到不同页面的url的区别是数字这的不同,因此这部分的代码如下:
def url_yield(self):
"""
:func 用于生成url
:yield items
"""
for i in range(1, self.MAX_PAGE + 1 ):
self.PAGE_TRACK = i #页面追踪
self.FLAG += 1 #每次加1
print('FLAG 是:', self.FLAG)
url = "{}{}{}".format(self.URL_START, i, self.PARAMS)
yield url
使用yield函数,每次只返回一个url
4.3 失败无限尝试模块
将抓取失败的url,再次进行抓取
def url_omi(self):
print("开始补漏")
length_pl = len(self.PAGE_LIST)
if length_pl != 0: #判断是否为空
for i in range(length_pl):
self.PAGE_TRACK = self.PAGE_LIST.pop(0) #构造一个动态列表, 弹出第一个元素
url = "{}{}{}".format(self.URL_START, self.PAGE_TRACK, self.PARAMS)
yield url
4.4 下载模块
包含更换请求头,失败重试功能和代理是否变更的功能。
def downloader(self, url, num_retries=3):
if self.proxy_con == 0:
proxies = self.proxy_get() #获取代理
else:
proxies = self.proxy_save #继续使用代理
self.proxy_save = proxies #更换代理值
headers_list = [{
'Accept': 'text/html, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Connection': 'keep-alive',
'Cookie':'log=; Hm_lvt_78c58f01938e4d85eaf619eae71b4ed1=1533992361,1533998469,1533998895,1533998953; Hm_lpvt_78c58f01938e4d85eaf619eae71b4ed1=1533998953; user=MDrAz9H9akQ6Ok5vbmU6NTAwOjQ2OTU0MjIzNDo3LDExMTExMTExMTExLDQwOzQ0LDExLDQwOzYsMSw0MDs1LDEsNDA7MSwxLDQwOzIsMSw0MDszLDEsNDA7NSwxLDQwOzgsMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDEsNDA6Ojo6NDU5NTQyMjM0OjE1MzM5OTkwNzU6OjoxNTMzOTk5MDYwOjg2NDAwOjA6MTZmOGFjOTgwMGNhMjFjZjRkMWZlMjk0NDQ4M2FhNDFkOmRlZmF1bHRfMjox; userid=459542234; u_name=%C0%CF%D1%FDjD; escapename=%25u8001%25u5996jD; ticket=7c92fb758f81dfa4399d0983f7ee5e53; v=Ajz6VIblS6HlDX_9PqmhBV0QDdH4NeBfYtn0Ixa9SCcK4daNPkWw77LpxLZl',
'hexin-v': 'AiDRI3i0b1qEZNNemO_FOZlE8SXqKQQBpg9Y4Jox7pbOH8oZQjnUg_YdKIHp',
'Host': 'q.10jqka.com.cn',
'Referer': 'http://q.10jqka.com.cn/',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36',
},{'Accept': 'text/html, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Connection': 'keep-alive',
'Cookie': 'user=MDq62tH9NUU6Ok5vbmU6NTAwOjQ2OTU0MjA4MDo3LDExMTExMTExMTExLDQwOzQ0LDExLDQwOzYsMSw0MDs1LDEsNDA7MSwxLDQwOzIsMSw0MDszLDEsNDA7NSwxLDQwOzgsMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDEsNDA6Ojo6NDU5NTQyMDgwOjE1MzM5OTg4OTc6OjoxNTMzOTk4ODgwOjg2NDAwOjA6MTEwOTNhMzBkNTAxMWFlOTg0OWM1MzVjODA2NjQyMThmOmRlZmF1bHRfMjox; userid=459542080; u_name=%BA%DA%D1%FD5E; escapename=%25u9ed1%25u59965E; ticket=658289e5730da881ef99b521b65da6af; log=; Hm_lvt_78c58f01938e4d85eaf619eae71b4ed1=1533992361,1533998469,1533998895,1533998953; Hm_lpvt_78c58f01938e4d85eaf619eae71b4ed1=1533998953; v=AibgksC3Qd-feBV7t0kbK7PCd5e-B2rBPEueJRDPEskkk8xLeJe60Qzb7jDj', 'hexin-v': 'AiDRI3i0b1qEZNNemO_FOZlE8SXqKQQBpg9Y4Jox7pbOH8oZQjnUg_YdKIHp',
'Host': 'q.10jqka.com.cn',
'Referer': 'http://q.10jqka.com.cn/',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36',
},
{'Accept': 'text/html, */*; q=0.01', 'Accept-Encoding': 'gzip, deflate, sdch', 'Accept-Language': 'zh-CN,zh;q=0.8', 'Connection': 'keep-alive', 'Cookie': 'user=MDq62sm9wM%2FR%2FVk6Ok5vbmU6NTAwOjQ2OTU0MTY4MTo3LDExMTExMTExMTExLDQwOzQ0LDExLDQwOzYsMSw0MDs1LDEsNDA7MSwxLDQwOzIsMSw0MDszLDEsNDA7NSwxLDQwOzgsMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDEsNDA6Ojo6NDU5NTQxNjgxOjE1MzM5OTg0NjI6OjoxNTMzOTk4NDYwOjg2NDAwOjA6MTAwNjE5YWExNjc2NDQ2MGE3ZGYxYjgxNDZlNzY3ODIwOmRlZmF1bHRfMjox; userid=459541681; u_name=%BA%DA%C9%BD%C0%CF%D1%FDY; escapename=%25u9ed1%25u5c71%25u8001%25u5996Y; ticket=4def626a5a60cc1d998231d7730d2947; log=; Hm_lvt_78c58f01938e4d85eaf619eae71b4ed1=1533992361,1533998469; Hm_lpvt_78c58f01938e4d85eaf619eae71b4ed1=1533998496; v=AvYwAjBHsS9PCEXLZexL20PSRyfuFzpQjFtutWDf4ll0o5zbyKeKYVzrvsAz', 'hexin-v': 'AiDRI3i0b1qEZNNemO_FOZlE8SXqKQQBpg9Y4Jox7pbOH8oZQjnUg_YdKIHp', 'Host': 'q.10jqka.com.cn', 'Referer': 'http://q.10jqka.com.cn/', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36', 'X-Requested-With': 'XMLHttpRequest'},
{'Accept': 'text/html, */*; q=0.01', 'Accept-Encoding': 'gzip, deflate, sdch', 'Accept-Language': 'zh-CN,zh;q=0.8', 'Connection': 'keep-alive', 'Cookie': 'Hm_lvt_78c58f01938e4d85eaf619eae71b4ed1=1533992361; Hm_lpvt_78c58f01938e4d85eaf619eae71b4ed1=1533992361; user=MDq62sm9SnpsOjpOb25lOjUwMDo0Njk1NDE0MTM6NywxMTExMTExMTExMSw0MDs0NCwxMSw0MDs2LDEsNDA7NSwxLDQwOzEsMSw0MDsyLDEsNDA7MywxLDQwOzUsMSw0MDs4LDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAxLDQwOjo6OjQ1OTU0MTQxMzoxNTMzOTk4MjA5Ojo6MTUzMzk5ODE2MDo4NjQwMDowOjFlYTE2YTBjYTU4MGNmYmJlZWJmZWExODQ3ODRjOTAxNDpkZWZhdWx0XzI6MQ%3D%3D; userid=459541413; u_name=%BA%DA%C9%BDJzl; escapename=%25u9ed1%25u5c71Jzl; ticket=b909a4542156f3781a86b8aaefce3007; v=ApheKMKxdxX9FluRdtjNUdGcac08gfwLXuXQj9KJ5FOGbTKxepHMm671oBoh', 'hexin-v': 'AiDRI3i0b1qEZNNemO_FOZlE8SXqKQQBpg9Y4Jox7pbOH8oZQjnUg_YdKIHp', 'Host': 'q.10jqka.com.cn', 'Referer': 'http://q.10jqka.com.cn/', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36', 'X-Requested-With': 'XMLHttpRequest'},
]
try:
time.sleep(random.random()*5) #设置延时
headers = random.choice(headers_list)
r = requests.get(url, headers = headers, proxies=proxies, timeout=4)
except:
if num_retries > 0:
print("重新下载")
self.proxy_con = 0 #更换代理
self.downloader(url,num_retries-1)
else:
if not self.PAGE_TRACK in self.PAGE_LIST: #首先应该判断 该页是否存在列表中,如果不存在, 则将其加入其中
self.PAGE_LIST.append(self.PAGE_TRACK) #将获取失败的url保存起来,后面再次循环利用,将元素添加在末尾,
else:
return r.text
4.5 解析及存储模块
这部分用来进行解析并将结果存储到csv中
def items_return(self):
sys.setrecursionlimit(5000)
count = 0
while True:
if self.FLAG < self.MAX_PAGE:
url_list = self.url_yield() #获取url
else:
url_list = self.url_omi()
if len(PAGE_LIST) ==0:
break
print("执行到了获取模块")
for url in url_list:
html = self.downloader(url)
#打印提示信息
print('URL is:', url)
items = {} #建立一个空字典,用于信息存储
try:
soup = BeautifulSoup(html, 'lxml')
for tr in soup.find('tbody').find_all('tr'):
td_list = tr.find_all('td')
items['代码'] = td_list[1].string
items['名称'] = td_list[2].string
items['现价'] = td_list[3].string
items['涨跌幅'] = td_list[4].string
self.writer.writerow(items)
print(items)
print("保存成功")
#如果保存成功,则继续使用代理
self.proxy_con = 1
#print("解析成功")
#yield items #将结果返回
except:
print("解析失败")
#解析失败,则将代理换掉
self.proxy_con = 0
#print(html)
if not self.PAGE_TRACK in self.PAGE_LIST:
self.PAGE_LIST.append(self.PAGE_TRACK)
else:
count += 1
if count == 2:
break
4.5 配置模块
为了方便项目的管理,可以将部分参数的配置放到一个setting.py文件中
#必要参数设置
MAX_PAGE = 165 #最大页数
PAGE_TRACK = 1 #追踪到了第几页
MAX_GET = 1 #获取最大尝试次数
MAX_PARSE = 1 #解析尝试最大次数
MAX_CSV = 1 #文件保存最大次数
MAX_PROXY =1 #获取代理的最大次数
MAX_START = 1 #MAX_*的初始值
MAX_TRY = 4 #最大尝试次数
FLAG = 0 #用于标识,是否使用 url_omi() 函数
#初始链接
URL_START = "http://q.10jqka.com.cn//index/index/board/all/field/zdf/order/desc/page/"
PARAMS = "/ajax/1/"
#第一次爬取的 html 缺失的页面 的url 列表
#先进先出的列表
PAGE_LIST = []
#代理池接口
PROXY_POOL_API = "http://127.0.0.1:5555/random"
headers = {
'Accept': 'text/html, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Connection': 'keep-alive',
'Cookie': 'spversion=20130314; __utma=156575163.1163133091.1530233537.1530289428.1530369413.3; __utmz=156575163.1530369413.3.3.utmcsr=stockpage.10jqka.com.cn|utmccn=(referral)|utmcmd=referral|utmcct=/; Hm_lvt_78c58f01938e4d85eaf619eae71b4ed1=1530444468,1530505958,1530506333,1530516152; Hm_lpvt_78c58f01938e4d85eaf619eae71b4ed1=1530516152; historystock=300033%7C*%7C1A0001; v=AiDRI3i0b1qEZNNemO_FOZlE8SXqKQQBpg9Y4Jox7pbOH8oZQjnUg_YdKIHp',
'hexin-v': 'AiDRI3i0b1qEZNNemO_FOZlE8SXqKQQBpg9Y4Jox7pbOH8oZQjnUg_YdKIHp',
'Host': 'q.10jqka.com.cn',
'Referer': 'http://q.10jqka.com.cn/',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'}
至此,整个项目已经完成。
后记:
源码获取可以关注公众号,发送“ths”即可获取下载链接。另外公众号还会介绍大数据的相关知识,如hadoop, flink, spark
等,欢迎关注。

你可能感兴趣的:(python,爬虫,爬虫系列教程)