34页PPT全解嵌入式AI框架Tengine的架构、算子定制和引擎推理【附实操视频+PPT下载】

出品| 智东西公开课
讲师 |王海涛OPEN AI LAB联合创始人兼Tengine首席架构师
提醒 | 点击上方蓝字关注我们,并回复关键词 “AI框架” ,即可获取课件。
导读:
4月8日晚,智东西公开课推出嵌入式AI框架OPEN AI LAB专场,由OPEN AI LAB联合创始人兼Tengine首席架构师王海涛主讲,主题为《Tengine-嵌入式AI框架的挑战与实践》。
本次专场讲解中,王海涛老师从嵌入式AI面临的挑战和Tengine的解决方案两个角度进行分析,全面解析Tengine架构及推理API的组成。最后,王老师会手把手教你如何通过Tengine定制个性化算子及在CPU/GPU/NPU/DLA上的推理。
本文为此次专场主讲环节的图文整理。
大家好,我是王海涛,今天为大家分享的主题为《Tengine-嵌入式AI框架的挑战与实践》,主要分为以下几个部分:
1、嵌入式AI面临的挑战和Tengine的解决方案
2、Tengine架构解析
3、Tengine API简介
4、实践1:Tengine扩展,定制和添加算子
5、实践2:Tengine在CPU/GPU/NPU/DLA上的推理
Tengine是一个嵌入式AI计算框架,是我们公司的一个核心产品,它首先在算力层面做了许多工作,通过与国内众多芯片厂商建立深度合作关系,采用各种技术方案去充分发挥硬件的计算性能,所以我们在全力打造一个AI的算力生态平台,希望通过Tengine,能够很方便的调用到底层芯片的算力。第二它会提供一系列的产品和工具包,方便算法训练出来后,面对端侧落地时需要解决的各种问题,能够有一套标准且快速的方法去解决这些问题,加速整个AI产业的落地。这是我们的一个目标,所以未来的Tengine会演化为一个AIoT的开发和部署平台,而不仅仅是一个推理框架。
嵌入式AI面临的挑战和Tengine的解决方案
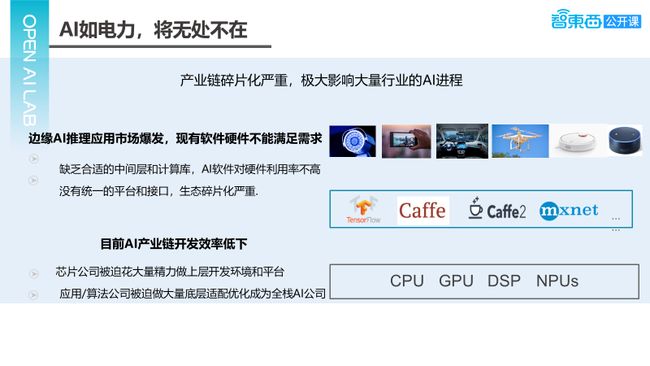
目前,嵌入式AI存在哪些问题呢?首先,可以看到AI对日常生活的渗透变得越来越强烈,可以说AI如电力将无处不在,这个趋势的形成主要有两方面的原因,第一是端侧计算算力的提升,即CPU的演进和各种各样NPU的出现;第二是算法本身的进步,可以看到从最早的VGG到Inception v1、v2、v3再到EfficientNet,算法本身也在不断的轻量化,导致以前只能跑在服务器上的AI应用,现在可以在端侧运行。另一个问题是大家对于数据安全和隐私越来越关注,这也导致越来越多人希望AI计算能够在本地上运行,就尽量不在云端上运行。对于端侧AI,16年是元年,到现在为止还处于一个快速的爆发期。
上面主要介绍前端的应用需求,那具体的产业链是什么情况呢?产业的情况目前是非常不友好的,第一体现在硬件的多样性,AIoT市场硬件的多样性是天然存在的,现在各种各样AI加速的IP出现导致多样化更严重。而且随着AI的进一步应用,以前认为不太可能跑AI的硬件,如MCU等,现在也可以跑一些AI的算法,所以整个硬件平台多样性越来越严重。
第二体现在软件的多样性,现在有很多种训练框架,那训练框架训练出来的模型送入嵌入式平台,目前也是处于百花齐放的状态,各种各样的框架也很多,训练框架有的是原生的,也有第三方开发的。所以对于应用开发人员来说,怎样把一个算法落地到平台上,这中间的过程还是非常长的。
以上是针对应用开发人员,那对算法开发人员,这也是一个很严重的问题。训练好的模型,要把它落地到一个算力有限的嵌入式平台,可能需要对模型做调整,把它的规模减小,还需要做量化及很多工作之后,才能实现落地。如果还想用嵌入式平台上的加速芯片,还需针对芯片做一些调整,可能有些算子不支持,需要做替换,或者定义上有差别。所以,整个的生态是非常不友好的。
在这种多样性环境下,可以看到整个AI产业链工作效率非常低下。对于芯片公司,它擅长做算力的提升,但发现如果只做芯片,做简单的驱动,很多的AI的开发者是没办法用起来的,所以它需要投入大量的资源去做上层的开发平台和开发环境,例如国内的华为公司,从芯片到ID环境到部署环境,整个一条产业链都做了。
算法和应用公司也发现如果不去完成底层硬件的适配,训练好的一个模型可能在训练时效果会非常好,真正落地到平台上时,要么性能特别慢,要么精度特别差。所以,它需要亲自把模型适配并优化好,这样算法才能真正的应用与落地。我们觉得整个产业链分工非常不明确,效率低下,这也是我们去试图改进和解决的问题。

Tengine是怎样赋能产业链呢?第一,把算法和芯片连接起来,不管模型是用哪个框架训练的,通过Tengine都能把它接纳进来,然后调用底层的计算平台,而且能保证在底层的计算平台能跑的非常好。第二,提供一些工具包和标准流程,帮助把模型很好的迁移到SOC平台上。对于Tengine想做这件事情,主要从三个方向去思考:
1)开放,开放主要从两点去关注。第一是开源,因为希望有更多的人用Tengine,所以做一个开源的措施。第二是模块化,因为AI的整个软件和硬件都还在快速的发展,我们需要提供很好的方式去支持新出现的算法、模型以及硬件,所以以模块化的方式去构建整个软件。
2)高效,因为在SOC平台算力永远是一个瓶颈,所以想让算法在平台上跑得快、跑得好,对它做优化是不可少的。而我们主要从两个层面做优化,第一是在图的层面做优化,第二个是实现高性能的计算库,这个计算库是完全自主知识产权的。
3)连接,首先是连接算法和芯片,不论算法或者芯片变化,都希望尽可能减少中间对接的成本。接着是我们还需要考虑支持多个计算设备的情况,能把多个设备之间的调度和使用连接起来。这是Tengine作为一个推理框架赋能产业时,做的三件事情。
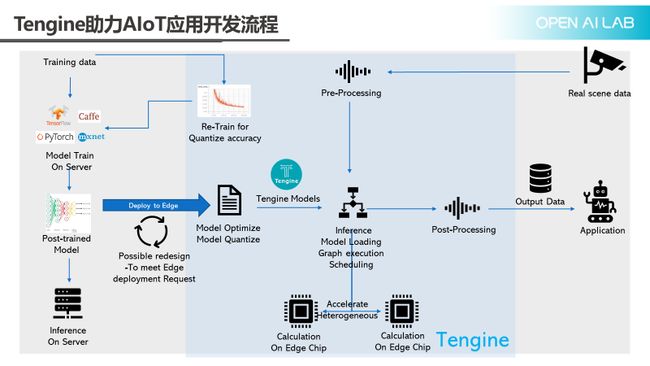
Tengine怎么样助力AIoT的应用开发呢?上图展示的是一个标准算法落地的过程。最左边是算法训练,然后再通过Inference server对外提供server里的标准工作流程。当需要在SoC上去做时,第一件事是对模型做优化,然后对模型做量化,这时有可能会出现精度和速度的下降情况,还需要把原始的模型去做一些修改,这个过程可能会反复很多次,改完之后,可以把它放到某一个inference engine上,然后在芯片上跑起来。
上面介绍的只是算法模型部分,真正的一个AI应用包含数据的记录和结果的输出。上面还可看到一个前处理、后处理的环节,不管是摄像头来的数据,还是传感器来的数据,都需要经过一定的前处理,再把数据送入推理引擎,推理引擎的结果也需做一定的后处理,才能够交给应用程序做进一步的分析和处理。在量化的过程中,有可能会造成一定的精度的损失,对一些精度要求比较高的场景,比如人脸或是支付场景,这种损失还需要尽量避免,所以还需要针对量化去做重训练。
Tengine为了加速AIoT的落地过程,如上图蓝色框的内容,都是Tengine做一些工作的地方。针对常见的主流的训练框架,提供了一个量化重训练的工具包,对于前处理和后处理也提供了专门的算法库来加速它。
Tengine架构解析
下面重点针对Tengine的推进引擎部分做简单介绍。主要分为以下几部分,首先是对整体架构的简单介绍,然后会介绍对训练框架的支持情况,因为这部分对于落地来说是最关键的,最后是计算图的执行,以及高性能计算库和配套工具

- Tengine产品架构
Tengine产品架构如上图所示,最上面是API接口,对于API接口,我们进行了仔细的研究,因为我们认为要去构建一个Tengine的AI应用生态,API的稳定性是第一位的,这样才能够保证整个生态能够持续发展。
下面是模型的转换层,可以把各种各样主流的训练框架模型转换成Tengine的模型,然后再端上运行,接着我们会提供一些配套的工具,包括图的编译、压缩、调优,以及进行仿真的一些工具,我们还提供了一些常用的算法库,包括前处理、后处理,以及面向一些特定领域的算法库。
接着下面是真正的执行层,包括图的执行、NNIR,NNIR是Tengine的图的一个表示,包括内存优化、调度和加密都在这里实现。再下面是对操作系统的适配,Tengine 目前已经支持RTOS和Bare-Metal的场景,这些都是为了支持特别低端CPU去做的。在异构计算层,我们已经能够去支持CPU、GPU、MCU、NPU等,今天也会给大家介绍在GPU和DLA上的用法。
- 训练框架与OS适配
对于训练框架,现在已经支持TensorFlow、PyTorch、MXNet等;对于主流操作系统,基本上Linux一系列都可以支持,还有RTOS也支持,后续还会把 IOS和Windows加上。
- 模型转换方案
模型转换方案本质上是把其他框架模型转换成Tengine的模型。我们有两个办法做模型转换,第一个是可以用Tengine提供的转换工具,自动转化。第二个需要用户自己去写一些代码,相当于可以用Python脚本把原模型的所有的参数和数据提出来,然后在通过Tengine接口去构建一个Tengine NNIR的图,最后再保存为Tengine的模型。所以,我们的模型转换方案,与其他方案不太一样。第一步是先把所有的模型解析成Tengine的NNIR格式,第二步再保存成Tengine模型。理论上,Tengine NNIR可以直接去执行,也是没有问题的。所以,利用这个方法还可以做更多的事情。比如可以把Tengine NNIR保存为一个Caffe的模型,这样就把Tengine作为一个模型之间转换的工具。做一个好的模型转换工具很不容易,我们定义Tengine NNIR时,其实也踩过很多框架之间兼容性的坑,虽然市面上可以看到有各种各样的转化工具,其实都会有多多少少的坑在里面。
- Tengine模型可视化工具
Tengine模型转化完之后,需要关心下模型转化结果对不对?是不是符合预期?我们和开源社区的模型可视化工具软件Netron进行了合作,实现Netron对Tengine模型支持,如果下载最新版本的Netron,已经对Tengine有很好的支持。

如上图所示的一个例子中,是SqueezeNet的最初的几层,第一个Convolution的属性,如上图右边所示,它的输入是一个data,然后它有一个filter和一个bias。可以看到,因为Tengine实际上是对着图做一些优化,所以属性会多一个activation。activation为0表示是一个ReLU的activation,实际上是把Convolution和ReLU合并在一起。这个工具能很好的展示Tengine模型结束后模型转化的结果,也是个非常好用的工具。
- 计算图执行
对于计算图的执行,刚才提到所有模型加载过来,不管是其他框架模型还是Tengine模型,都会把它转换成Tengine NNIR,这需要去屏蔽各种框架的差异,把兼容性做得非常好。得到Tengine NNIR后,要决定这些节点在哪个设备上执行,如果系统只有一个设备,问题比较容易解决。但当系统存在多个计算设备时,会遇到一些困难,第一个是两个计算设备可能特点会不一样,比如其中一个性能比较高,但有些算子不支持,另一个设备性能比较低,但算子支持程度会比较好。那采取什么策略去做,是切成多个,还是集中在一个上去算?这属于静态情况,若是动态情况就更复杂。
假定设备A当前看起来很闲,但当我准备把这个任务发给它时,它可能会变得很繁忙。所以目前为止,一直没有特别好的解决方案。这里更接近于OpenVX的方案,OpenVX的方案实际上是所有计算设备需要按你的需求定一个优先级,得到一个计算图之后,计算图会按照优先级去询问底下设备,能不能支持这个节点。如果有一个设备响应了,这个节点就不会再分配给其他的设备。我们的方案与它类似,不同点在于我们会让计算图在所有的计算设备都看一遍,并不只是终结到某一个为止。
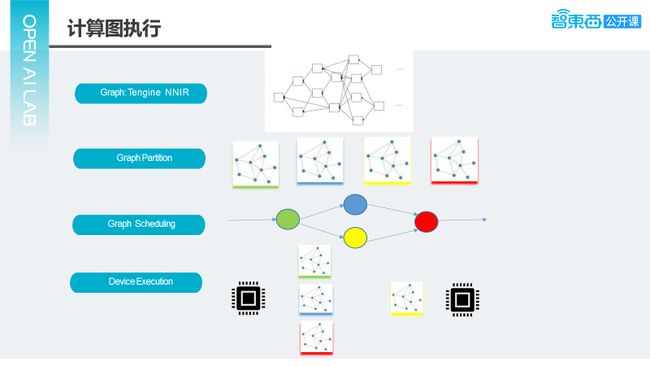
通过这种方式,可以确定这个图的哪个节点在哪个设备上去算,确定完之后,根据设备分配的情况,把图切成多个不同的部分。上面的示意图是举的一个例子,实际上是切成4个部分,这4个部分图之间会有一定的依赖关系,有些图可以并行执行,有些图不能并行执行。假定黄色和蓝色是可以并行执行的,让他们构成一个执行图,接下来把这个图调度到各个设备上去执行,可以看到黄色和蓝色的计算图,可以同时在两个设备上去跑,这是大概整个计算的一个过程。
- 发挥硬件极致性能的计算
真正在设备上跑时,还需要把算力尽可能发挥出来。我们对计算库做了大量的优化,花精力最多的是整个神经网络里面最耗时的一部分算子包括卷积,全连接层和池化。卷积根据参数的不同,也实现了各种不同的计算模式,比如基于GEMM、Direct和Winograd的,一般情况下,我们库的双向加速比可以达到175%,四线程可以达到300%,对于有些网络还会更好,四线程将近接近400%。
对于优化,实际上是针对CPU的微架构做优化。在一个完整的网络运行的情况下,可以看到Convolution MAC利用率可达到70%,基本上是把硬件的性能给用尽了,我们对Arm的全系列产品都做了很好的适配。
计算库不仅对FP32有很好的支持,对INT8也做了很好的优化,这样才能够充分发掘出硬件的算力,可以看到INT8比FP32基本上能提速50~90%。同时也注意到INT8还是会带来一些精度损失,计算库还支持混合精度计算的模式,对于精度损失大的层,可以采用FP32计算,其他可以采用INT8计算,这是一个能够同时兼顾精度和速度的方案。对于开源版本的FP32的性能,整个的效果是非常不错的,Squeezenet都不到60毫秒。
- 量化重训练工具
刚才提到INT8对于端侧推理,现在基本上是一个必选项。但INT8的精度的问题一直困扰大家,我们再看下现在主流的训练框架,除了TensorFlow有个TensorFlow.Net之外,其他的框架目前都没有非常完整的一个量化重训练方案。针对这个问题,我们做了一个量化重训练的工具,还针对NPU做了一些改进,因为NPU的芯片厂商对于训练并不是特别熟悉,所以我们希望能够去帮他去改进在NPU上跑的量化精度,让更多的应用在NPU上去把它跑起来。

如上图右边所示为量化重训练的结果,可以看到整个效果是非常不错的。特别是对于MxNet_MobileNet,重训练后的精度可以提高两个百分点。
除了Tengine整个配套工具及量化重训练之外,对于前处理、后处理,也做了不少的工作,实际上有个HCL.Vision的模块,是针对CV的应用做的一个计算库。这个计算库与其他CV计算库不同点在于若硬件平台上有一些图像处理的加速,会去调用底层硬件平台接口来处理,若没有,我们会用做一个优化的CPU的实现,对外会提供一个统一的接口,这对于开发应用程序就非常方便了。在接口不变的情况下,在一个有硬件加速的平台上就能够获得硬件的加速。
Tengine API简介
下面进入Tengine API的部分,首先介绍下对API设计的想法,后面再介绍下目前API的一些应用。
- 概述
在刚开始做Tengine时,我们把API放在一个很重要的位置,同时也学习和参考业界一些优秀的软件方案以及框架。实际上主要参考了Android NN、OpenVX、TensorRT、TensorFlow、MXNet的接口设计原则和思路,最后更偏向于OpenVX。
我们有两个原则,第一个是接口的定义和实现完全无关,这主要基于现在AI的软件和硬件还处于一个快速发展的情况下来考虑的。如果接口定义会绑定某些实现,会对代码重构或支持一些新的特性时,带来很大负担,所以把接口定义和实现完全抛开。
第二个是要注重接口的稳定性和灵活性,稳定性对于所有的API都非常重要。为什么还特别强调灵活性?与上面类似,未来会怎么样我们不是很清楚,所以要尽可能预留一些接口,去支持未来要出现的功能以及给应用程序对底层有更多的操控权,这样会更有利于Tengine应用生态的稳定性和长期发展性。
对于硬件这块,一直考虑怎么样能够对Tengine支持的更好。在端侧跑一些训练的模型,是一个可以看得见的趋势,所以接口也要去支持模型训练。从本质上来说,Tengine是连接算法和芯片,通过一个标准的接口把芯片的算力提供给应用。这对于我们去实行和训练的方案,也是很有价值的。最后我们看下结果,我们采用C的接口作为核心的API,然后基于C去封装一些更好用的API,比如C++ API或者Python API,这两个API目前已经实现了,规划中还有JS API和Java API,他们都会基于C API去做,这是整个API体系的一个想法。

- 多芯片和软件后端支持
在进入AIoT市场时,我们知道未来一定是有多种AI加速芯片和AI IP的出现,怎样让应用程序在不同的芯片或不同的AI加速IP之间迁移时,工作量能更少。可以看下我们的方案,我们的方案是应用程序通过一次性的接口,就能够调到各种不同的算力。如上图最左边可以看到,在一个RK3288或树莓派Linux上去实现推理的一个用法,他调用Tengine模型,右边第一行是一个MCU的平台,他可能需要换一种新的模型就好,换为tiny模型,不再是Tengine的一个模型。如果是NPU,只需要把中间模型的格式给换一下,其他部分基本上都不需要去改动,这样不管是应用程序的维护,还是学习成本都会很低。
基于我们的API会发现,对于现在的开发商降低很多复杂度。比如一个应用,希望既能在安卓上跑,又能在Linux上跑时,可以调Tengine接口,都能很好的调用到底层硬件的算力。在安卓下会更复杂,因为Google提出Android NN API的一个接口,在之前并没有这个接口,假定有一个应用程序,既想调用这个接口,那它没在Android NN的平台上,怎么办呢?
实际上我们可以用中间的方案,仍然调用Android NN API,但是通过重新实现Android NN Runtime让Tengine调底下的一个算力,这样可以保证你的用程序,不必担心在不同平台上需要去切换接口的问题。由上面的场景可以看到对底下的芯片公司价值最大,而芯片公司,只需对Tengine做试配之后,对于各种场景都能够很好的为应用程序提供一个算力的功能。
- C++ API和Python API
下面介绍下C++ API和Python API,这两个主要是为了快速简单去使用,所以会把C API里面很多的功能去掉。看一个典型的用法,分为4步,第一步是加载模型,第二步是设置输入数据,第三步是run,第4步是取一个接口,整个是非常强的接口,很好去懂,几乎是没有学习成本的。
Python API与C++ API类似,只不过变成Python结构下也能调这些东西,不再详细赘述。

C API相对来说,它的核心API会比较复杂,它可以分为几大类,第一大类是Tengine的初始化,销毁,接下来是跟Tengine整个NNIR对应,Tengine里面有Graph的概念,有Node的概念,有Tensor的概念。这部分概念跟TensorFlow会更像些。对于Graph,包含Graph创建,Node的创建,所以通过Tengine接口,是可以去创建一个图的,这也是为了支持模型转换及训练等功能区做的考虑。接下来还是图执行的接口,包括Prerun和Postrun,剩下都是一些杂项接口,比如我们设置日志的重新项,可以去graph和节点绑定一个执行设备,更多的细节的话大家可以看一下我们下面链接,然后应该每个API都有注释还是比较清楚的。
下面介绍下用C API去做推理的典型过程,与刚才差不多,可能稍微麻烦一点就是需要主动调一个prerun的接口,prerun接口完成把计算图绑定一个设备的问题,以及在设备上分配给计算图做计算所需要资源的过程。接下来是去设Tensor的buffer,然后再去run。
- C API创建图和节点
首先是创建一个空的图,空的图代表什么都没有,它不来自于任何的框架;接下来需要创建一个input节点,input节点需要创建两个东西,第一个是Node,第二个是Tensor,将Tensor设置为节点的output的Tensor,这一点的思路是和TensorFlow完全一致,所以会与TensorFlow会长得比较像一点;再接下来是创建一个Convolution节点,与上面的input节点类似,首先需要创建一个节点,并指定这个节点的op是一个Convolution;之后要创建这个节点输出的Tensor;再下面把输入的Tensor设好,比如说0、1、2,分别设定input_tensor、w_tensor和b_tensor,这三个就构成了这个节点;Convolution还有很多参数,比如kernel size,stride,padding怎么去设?我们提供了一个接口,可以直接设置节点的属性,可以通过程序直接设置。
实践1:Tengine扩展,定制和添加算子
前面已基本上介绍完接口,下面再结合具体的代码给看下我们怎么样去扩展和定制算子。
- Tengine算子kernel定制
首先是算子kernel的定制,若Tengine里已经实现一个算子,但和目前实现的框架有差别时,希望想要一个更好的实现,或你的平台上有一个硬件可以对算子做加速,你不希望用我们已经做好的,有两种办法去解决,第一种是通过C API的custom kernel的接口做替换,但替换时需要指定哪个节点来做,这类接口学习成本可能会低些,因为不需要了解Tengine添加一个新算子的过程,只需要做计算。
第二种情况是可以用Plugin的实现,通过一个外挂模块来把算子重新实现,只不过在注册时把实现的优先级提高。这样做完之后,所有关于这个类型算子的实现,都会用我们自己的算子来做。
下面我们会先介绍下用Tengine C API去做替换的方式,然后Plugin的方式会在后面一个例子中怎么去添加一个新算子去讲解。

Tengine C API里有一个的custom kernel的接口,这个接口最关键的数据是custom_kernel_ops,它的定义了custom kernel需要实现内容,它的数据结构如上图所示,第一个是op,op是表明要去做一个convolution,还是要去做一个pooling,在接下来是两个parameter,一个kernel_param,一个kernel_param_size,是给我们算子自己去用的。然后三个最关键函数:prerun、run、postrun,传进去首先是ops,就是ops自身,接下来是input_tensor和output_tensor。其他的参数,需要在parameter里找出来。
这个设置完之后,我们可以去调set_custom_kernel去替换设备上的实现。现在我们可以去看下代码。
- Tingine新算子的添加
新算子的添加,对于推理框架也很重要,特别是针对Tensorflow的情况,由于Tensorflow算子既多又复杂,当遇到不支持算子时,我们推荐先用plugin的模式在Tingine Repo外实现。待测试稳定之后,再提交PR合入到Repo里。
下面以Tensorflow新算子Ceil为例,一共有以下几件事情:第一是在Tengine NNIR中注册一个新的算子定义;第二是在Tengine Tensorflow Serializer中注册算子的模型加载;最后需要在Tengine Executor里面真正实现算子,可以看下它的代码。
实践2:Tengine在CPU/GPU/NPU/DLA上的推理
下面看下怎样做推理,我们选了一个MobilenetSSD来做,一共有三个例子,第一个是单独用一个是 CPU跑,第二个是CPU+GPU配合跑,第三是多设备跑的情况,以MSSD的为例。前面是在CPU、GPU下运行的情况,假定是一个NPU或一个DLA时,我们怎样能把它用起来?我们先看一个演示。
由上面可以看出,调用NPU 是一件非常容易的事情,对于学习成本和应用开发速度都有很大的提升。
课件获取
在本公众号【智东西】后台回复“AI框架”获取本次完整讲解PPT。
END
直播预告
6月12日晚7点,爱数智慧专场正式开讲!爱数智慧首席数据科学家贾艳明将讲解数据角度看AI模型训练的挑战。
扫描下方海报中的二维码快速报名

你的每一个“在看”,我都当成了喜欢
▼