python爬虫+网页版微信实时获取消息程序
项目需求:
目的是24小时爬取各种软件的讯息并且以一种统一的方式集中发送给自己。
实现方法:
利用python的requests库以及wxpy库,前者用来爬取网页,后者用来将爬到的内容发送给自己。
程序介绍:
需要的库:
import wxpy #用来登录网页版微信并发信息
import requests #用来爬取网页
import json #方便处理数据结构
import time #设定爬取时间
from bs4 import BeautifulSoup #分析静态网页
爬取网页的函数:
def get_url(url, kv):
try:
r = requests.get(url, headers=kv)#爬取网页并获取内容
r.raise_for_status()
return r
except:
return 0
爬取雪球:
通过打开需要爬取的个人主页,获取其实时更新的动态,先找到需要爬取的内容所在的地方。
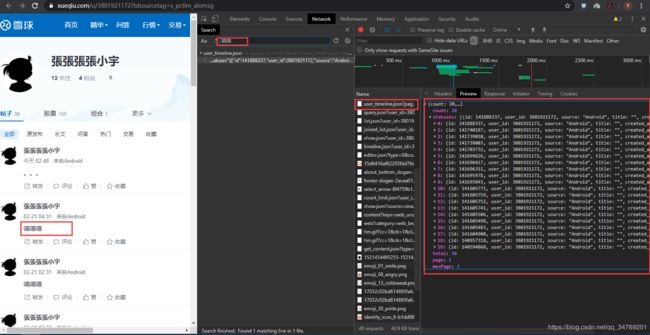
然后记录下url和header信息:
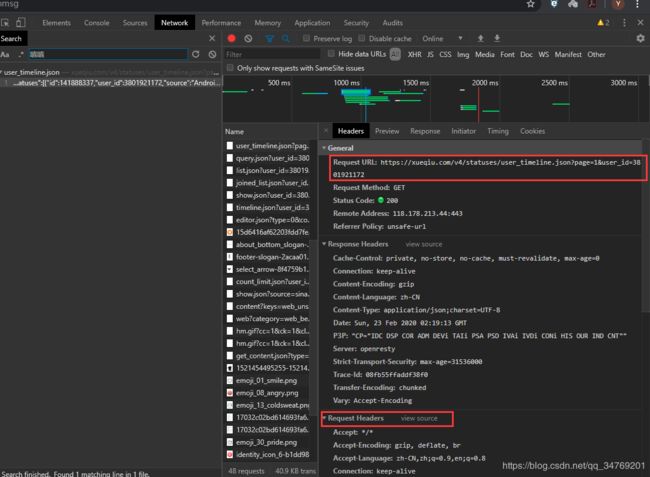
保存多名用户的信息。
url_xueqiu = []
headers_xueqiu = []
url_xueqiu.append("https://xueqiu.com/v4/statuses/user_timeline.json?page=1&user_id=3072042836")
url_xueqiu.append("https://xueqiu.com/v4/statuses/user_timeline.json?page=1&user_id=3801921172")
url_xueqiu.append("https://xueqiu.com/v4/statuses/user_timeline.json?page=1&user_id=1314783718")
headers_xueqiu.append({'Referer': 'https://xueqiu.com/u/3072042836',
'User-Agent': 'Mozilla/5.0',
'cookie': 'aliyungf_tc=AQAAAKd7yFTFjAoAtcKEdSDxLV5FCp46; acw_tc=2760821a15820984687844418edc2e869d8485911ed7c90640c4ba33632f81; s=dx11t858l7; xq_a_token=b2f87b997a1558e1023f18af36cab23af8d202ea; xq_r_token=823123c3118be244b35589176a5974c844687d5e; xq_id_token=eyJ0eXAiOiJKV1QiLCJhbGciOiJSUzI1NiJ9.eyJ1aWQiOi0xLCJpc3MiOiJ1YyIsImV4cCI6MTU4MzE0MzIwMCwiY3RtIjoxNTgyMDk4NDI5MjU0LCJjaWQiOiJkOWQwbjRBWnVwIn0.OuUax528Ug96Mv18JXYbgemPn4dZbo3coZmcmHu49DG3xX4Esf3xtJZzfyq9_S3Uame_Euq47p4XL-xuqG3nmS0zN5SOrRCf2g6WFMQAzIXAOyqQIHGvZn3EnZ-dkElXNi_5QUNG8Uvu_HL6_9KAdaQryU5Kn8Tkkzu3xd05sbxy9WT_qEZe6Fega2Sjh2GlwO-k7FsvkBJcbkFlKTmZnk6HaqrPVlIrMlV6C5X2QPZEYFXq5RiRkEpkVwh9SaG3_UwI8kbGI_ggKF7aPpc48aV-ZxCsZhbV8kLkJ96vZlm4ZP18AeYjZpEA5thAjOhjYjDOpjWIAE0iC-eEAgpO2g; u=181582098495409; cookiesu=181582098495409; Hm_lvt_1db88642e346389874251b5a1eded6e3=1582098497; device_id=f3bae24173cc39686f529ebf5b4ab06a; Hm_lpvt_1db88642e346389874251b5a1eded6e3=1582100987'}
)
headers_xueqiu.append({'Referer': 'https://xueqiu.com/u/3801921172',
'User-Agent': 'Mozilla/5.0',
'cookie': 'aliyungf_tc=AQAAAKd7yFTFjAoAtcKEdSDxLV5FCp46; acw_tc=2760821a15820984687844418edc2e869d8485911ed7c90640c4ba33632f81; s=dx11t858l7; xq_a_token=b2f87b997a1558e1023f18af36cab23af8d202ea; xq_r_token=823123c3118be244b35589176a5974c844687d5e; xq_id_token=eyJ0eXAiOiJKV1QiLCJhbGciOiJSUzI1NiJ9.eyJ1aWQiOi0xLCJpc3MiOiJ1YyIsImV4cCI6MTU4MzE0MzIwMCwiY3RtIjoxNTgyMDk4NDI5MjU0LCJjaWQiOiJkOWQwbjRBWnVwIn0.OuUax528Ug96Mv18JXYbgemPn4dZbo3coZmcmHu49DG3xX4Esf3xtJZzfyq9_S3Uame_Euq47p4XL-xuqG3nmS0zN5SOrRCf2g6WFMQAzIXAOyqQIHGvZn3EnZ-dkElXNi_5QUNG8Uvu_HL6_9KAdaQryU5Kn8Tkkzu3xd05sbxy9WT_qEZe6Fega2Sjh2GlwO-k7FsvkBJcbkFlKTmZnk6HaqrPVlIrMlV6C5X2QPZEYFXq5RiRkEpkVwh9SaG3_UwI8kbGI_ggKF7aPpc48aV-ZxCsZhbV8kLkJ96vZlm4ZP18AeYjZpEA5thAjOhjYjDOpjWIAE0iC-eEAgpO2g; u=181582098495409; cookiesu=181582098495409; Hm_lvt_1db88642e346389874251b5a1eded6e3=1582098497; device_id=f3bae24173cc39686f529ebf5b4ab06a; Hm_lpvt_1db88642e346389874251b5a1eded6e3=1582102587'}
)
headers_xueqiu.append({'Referer': 'https://xueqiu.com/u/1314783718',
'User-Agent': 'Mozilla/5.0',
'cookie': 'acw_tc=2760821a15820984687844418edc2e869d8485911ed7c90640c4ba33632f81; s=dx11t858l7; device_id=f3bae24173cc39686f529ebf5b4ab06a; aliyungf_tc=AQAAAFkbfHaZAQsAK8KEddBs2OH7Zmqv; xq_a_token=b2f87b997a1558e1023f18af36cab23af8d202ea; xqat=b2f87b997a1558e1023f18af36cab23af8d202ea; xq_r_token=823123c3118be244b35589176a5974c844687d5e; xq_id_token=eyJ0eXAiOiJKV1QiLCJhbGciOiJSUzI1NiJ9.eyJ1aWQiOi0xLCJpc3MiOiJ1YyIsImV4cCI6MTU4MzE0MzIwMCwiY3RtIjoxNTgyMzg1Mjg3MTgwLCJjaWQiOiJkOWQwbjRBWnVwIn0.Crta07q4xFTBXA1raWy-kFHZydPOytwS5Tz1CN14ABe5ruoojfHDVH_Y1shaGaqrpP_9b_l2Zg4Dx87WAC4-wWCNzSijCyKkwqtAQXS9QpfjH79-zmqAloo86dz5DY_H297QDuQZd0-Psi6-hQW2o70lc75DI2pTHWRHVeENRH1sIaWUylGaouXLugIM1ppXLdgyEqf85zGJQxPQUX-ryNOQINn6FBKPw4lfn--2k78U-aCZmPh-Mxx_BStyEOAZPkWwcYiBxcGpU_Wr9tlqedaj-NoTR71mJ5OZFToqYEzcvkk1BKUbPh1li4g1KZ7DhK-FVOivyi8o70c8TN3ygg; u=741582385322747; Hm_lvt_1db88642e346389874251b5a1eded6e3=1582098497,1582385350; cookiesu=381582390368314; Hm_lpvt_1db88642e346389874251b5a1eded6e3=1582390370'}
)
调用函数获取所需的博文内容,在’statuses’结构中:
def get_xueqiu(r):
r_text = r.text
r_json = json.loads(r_text)
need = r_json['statuses']
return need
微博也同理:
url_weibo = []
headers_weibo = []
url_weibo.append("https://m.weibo.cn/api/container/getIndex?type=uid&value=3191919325&containerid=1076033191919325")
headers_weibo.append({'Referer': 'https://m.weibo.cn/u/3191919325',
'User-Agent': 'Mozilla/5.0'})
url_weibo.append("https://m.weibo.cn/api/container/getIndex?type=uid&value=2301894077&containerid=1076032301894077")
headers_weibo.append({'Referer': 'https://m.weibo.cn/u/2301894077',
'User-Agent': 'Mozilla/5.0'})
但是微博的文字所在内容在’data’里面的’cardss’中
def get_weibo(r):
r_text = r.text
r_json = json.loads(r_text)
need = r_json['data']['cards']
return need
雪球7*27小时新闻:
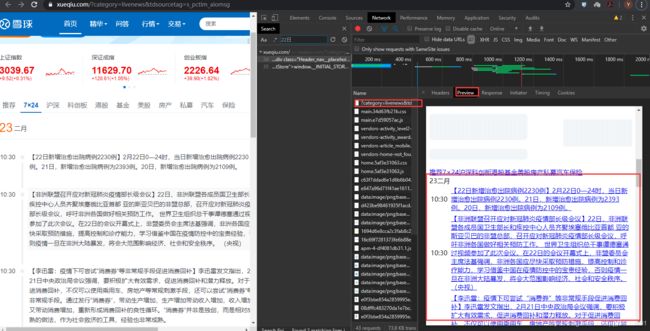
url_7 = 'https://xueqiu.com/?category=livenews&tdsourcetag=s_pctim_aiomsg'
headers_7 = {'Referer': 'https://xueqiu.com/u/1314783718',
'User-Agent': 'Mozilla/5.0',
'cookie': 'acw_tc=2760821a15820984687844418edc2e869d8485911ed7c90640c4ba33632f81; s=dx11t858l7; device_id=f3bae24173cc39686f529ebf5b4ab06a; aliyungf_tc=AQAAAFkbfHaZAQsAK8KEddBs2OH7Zmqv; xq_a_token=b2f87b997a1558e1023f18af36cab23af8d202ea; xqat=b2f87b997a1558e1023f18af36cab23af8d202ea; xq_r_token=823123c3118be244b35589176a5974c844687d5e; xq_id_token=eyJ0eXAiOiJKV1QiLCJhbGciOiJSUzI1NiJ9.eyJ1aWQiOi0xLCJpc3MiOiJ1YyIsImV4cCI6MTU4MzE0MzIwMCwiY3RtIjoxNTgyMzg1Mjg3MTgwLCJjaWQiOiJkOWQwbjRBWnVwIn0.Crta07q4xFTBXA1raWy-kFHZydPOytwS5Tz1CN14ABe5ruoojfHDVH_Y1shaGaqrpP_9b_l2Zg4Dx87WAC4-wWCNzSijCyKkwqtAQXS9QpfjH79-zmqAloo86dz5DY_H297QDuQZd0-Psi6-hQW2o70lc75DI2pTHWRHVeENRH1sIaWUylGaouXLugIM1ppXLdgyEqf85zGJQxPQUX-ryNOQINn6FBKPw4lfn--2k78U-aCZmPh-Mxx_BStyEOAZPkWwcYiBxcGpU_Wr9tlqedaj-NoTR71mJ5OZFToqYEzcvkk1BKUbPh1li4g1KZ7DhK-FVOivyi8o70c8TN3ygg; u=741582385322747; Hm_lvt_1db88642e346389874251b5a1eded6e3=1582098497,1582385350; cookiesu=901582391948014; Hm_lpvt_1db88642e346389874251b5a1eded6e3=1582391948'}
接下来开始第一次读取网页内容:
id_weibo = []#这几个id用来记录内容的标识,使其具有唯一性。
id_xueqiu = []
id_http = []
for i in zip(url_xueqiu, headers_xueqiu):
temp_r = get_url(i[0], i[1])
temp_need = get_xueqiu(temp_r)
for j in temp_need:
id_xueqiu.append([j['id'], j['user_id']])#记录当前页面的所有标识
for i in zip(url_weibo, headers_weibo):
temp_r = get_url(i[0], i[1])
temp_need = get_weibo(temp_r)
for j in temp_need:
id_weibo.append(j['mblog']['id'])
#处理与前面不大一样
r_7 = requests.get(url_7, headers=headers_7)
r_7.encoding = "utf-8"#该网页是utf-8编码
soup = BeautifulSoup(r_7.text, 'html.parser')#用静态网页工具把str转换成网页
new_list = soup.find('div', {'id': 'app'})
new_2 = new_list.find_all_next('table')#找到其内容所在的地方。
for i in new_2:
pre_a = i.find('a')
id_http.append(pre_a.__getitem__('href'))#记录其标识
接下来开始发送微信消息:
# 构建机器人
bot = wxpy.Bot(cache_path=True, console_qr=False)#登陆微信号
xiaohao = bot.friends().search("张张张")[0]#找到一个联系人,可以发消息的
设置循环开是监听消息:
print("开始监听")
while True:
time.sleep(5)
# 监视雪球
for i in zip(url_xueqiu, headers_xueqiu):
temp_r = get_url(i[0], i[1])
try:
temp_need = get_xueqiu(temp_r)
except:
print("无网络连接")
break
for j in temp_need:
if [j['id'], j['user_id']] not in id_xueqiu:
text_temp = j['text']
text_temp = text_temp.replace(''
, '')
text_temp = text_temp.replace('', '\n')
text_send = j['user']['screen_name'] + "有新消息:\n\n" + text_temp
print(text_send)
xiaohao.send(text_send)
id_xueqiu.append([j['id'], j['user_id']])
# 监视微博
for i in zip(url_weibo, headers_weibo):
temp_r = get_url(i[0], i[1])
try:
temp_need = get_weibo(temp_r)
except:
print("无网络连接")
break
for j in temp_need:
if j['mblog']['id'] not in id_weibo:
text_send = j['mblog']['user']['screen_name'] + "有新消息:\n\n" + j['mblog']['text']
print(text_send)
xiaohao.send(text_send)
id_weibo.append(j['mblog']['id'])
# 7X24小时新闻
try:
r_7 = requests.get(url_7, headers=headers_7)
r_7.encoding = "utf-8"
soup = BeautifulSoup(r_7.text, 'html.parser')
new_list = soup.find('div', {'id': 'app'})
new_2 = new_list.find_all_next('table')
for i in new_2:
pre_a = i.find('a')
if pre_a.__getitem__('href') not in id_http:
text_send = "7*24小时新闻有新消息:\n\n" + pre_a.get_text() + '\n' + pre_a.__getitem__('href')
xiaohao.send(text_send)
print(text_send)
id_http.append(pre_a.__getitem__('href'))
except:
print("无网络连接")
代码:
import wxpy
import requests
import json
import time
from bs4 import BeautifulSoup
def get_url(url, kv):
try:
r = requests.get(url, headers=kv)
r.raise_for_status()
return r
except:
return 0
def get_xueqiu(r):
r_text = r.text
r_json = json.loads(r_text)
need = r_json['statuses']
return need
def get_weibo(r):
r_text = r.text
r_json = json.loads(r_text)
need = r_json['data']['cards']
return need
if __name__ == '__main__':
# 构建机器人
bot = wxpy.Bot(cache_path=True, console_qr=False)
xiaohao = bot.friends().search("张张张")[0]
# 雪球
url_xueqiu = []
headers_xueqiu = []
url_xueqiu.append("https://xueqiu.com/v4/statuses/user_timeline.json?page=1&user_id=3072042836")
url_xueqiu.append("https://xueqiu.com/v4/statuses/user_timeline.json?page=1&user_id=3801921172")
url_xueqiu.append("https://xueqiu.com/v4/statuses/user_timeline.json?page=1&user_id=1314783718")
headers_xueqiu.append({'Referer': 'https://xueqiu.com/u/3072042836',
'User-Agent': 'Mozilla/5.0',
'cookie': 'aliyungf_tc=AQAAAKd7yFTFjAoAtcKEdSDxLV5FCp46; acw_tc=2760821a15820984687844418edc2e869d8485911ed7c90640c4ba33632f81; s=dx11t858l7; xq_a_token=b2f87b997a1558e1023f18af36cab23af8d202ea; xq_r_token=823123c3118be244b35589176a5974c844687d5e; xq_id_token=eyJ0eXAiOiJKV1QiLCJhbGciOiJSUzI1NiJ9.eyJ1aWQiOi0xLCJpc3MiOiJ1YyIsImV4cCI6MTU4MzE0MzIwMCwiY3RtIjoxNTgyMDk4NDI5MjU0LCJjaWQiOiJkOWQwbjRBWnVwIn0.OuUax528Ug96Mv18JXYbgemPn4dZbo3coZmcmHu49DG3xX4Esf3xtJZzfyq9_S3Uame_Euq47p4XL-xuqG3nmS0zN5SOrRCf2g6WFMQAzIXAOyqQIHGvZn3EnZ-dkElXNi_5QUNG8Uvu_HL6_9KAdaQryU5Kn8Tkkzu3xd05sbxy9WT_qEZe6Fega2Sjh2GlwO-k7FsvkBJcbkFlKTmZnk6HaqrPVlIrMlV6C5X2QPZEYFXq5RiRkEpkVwh9SaG3_UwI8kbGI_ggKF7aPpc48aV-ZxCsZhbV8kLkJ96vZlm4ZP18AeYjZpEA5thAjOhjYjDOpjWIAE0iC-eEAgpO2g; u=181582098495409; cookiesu=181582098495409; Hm_lvt_1db88642e346389874251b5a1eded6e3=1582098497; device_id=f3bae24173cc39686f529ebf5b4ab06a; Hm_lpvt_1db88642e346389874251b5a1eded6e3=1582100987'}
)
headers_xueqiu.append({'Referer': 'https://xueqiu.com/u/3801921172',
'User-Agent': 'Mozilla/5.0',
'cookie': 'aliyungf_tc=AQAAAKd7yFTFjAoAtcKEdSDxLV5FCp46; acw_tc=2760821a15820984687844418edc2e869d8485911ed7c90640c4ba33632f81; s=dx11t858l7; xq_a_token=b2f87b997a1558e1023f18af36cab23af8d202ea; xq_r_token=823123c3118be244b35589176a5974c844687d5e; xq_id_token=eyJ0eXAiOiJKV1QiLCJhbGciOiJSUzI1NiJ9.eyJ1aWQiOi0xLCJpc3MiOiJ1YyIsImV4cCI6MTU4MzE0MzIwMCwiY3RtIjoxNTgyMDk4NDI5MjU0LCJjaWQiOiJkOWQwbjRBWnVwIn0.OuUax528Ug96Mv18JXYbgemPn4dZbo3coZmcmHu49DG3xX4Esf3xtJZzfyq9_S3Uame_Euq47p4XL-xuqG3nmS0zN5SOrRCf2g6WFMQAzIXAOyqQIHGvZn3EnZ-dkElXNi_5QUNG8Uvu_HL6_9KAdaQryU5Kn8Tkkzu3xd05sbxy9WT_qEZe6Fega2Sjh2GlwO-k7FsvkBJcbkFlKTmZnk6HaqrPVlIrMlV6C5X2QPZEYFXq5RiRkEpkVwh9SaG3_UwI8kbGI_ggKF7aPpc48aV-ZxCsZhbV8kLkJ96vZlm4ZP18AeYjZpEA5thAjOhjYjDOpjWIAE0iC-eEAgpO2g; u=181582098495409; cookiesu=181582098495409; Hm_lvt_1db88642e346389874251b5a1eded6e3=1582098497; device_id=f3bae24173cc39686f529ebf5b4ab06a; Hm_lpvt_1db88642e346389874251b5a1eded6e3=1582102587'}
)
headers_xueqiu.append({'Referer': 'https://xueqiu.com/u/1314783718',
'User-Agent': 'Mozilla/5.0',
'cookie': 'acw_tc=2760821a15820984687844418edc2e869d8485911ed7c90640c4ba33632f81; s=dx11t858l7; device_id=f3bae24173cc39686f529ebf5b4ab06a; aliyungf_tc=AQAAAFkbfHaZAQsAK8KEddBs2OH7Zmqv; xq_a_token=b2f87b997a1558e1023f18af36cab23af8d202ea; xqat=b2f87b997a1558e1023f18af36cab23af8d202ea; xq_r_token=823123c3118be244b35589176a5974c844687d5e; xq_id_token=eyJ0eXAiOiJKV1QiLCJhbGciOiJSUzI1NiJ9.eyJ1aWQiOi0xLCJpc3MiOiJ1YyIsImV4cCI6MTU4MzE0MzIwMCwiY3RtIjoxNTgyMzg1Mjg3MTgwLCJjaWQiOiJkOWQwbjRBWnVwIn0.Crta07q4xFTBXA1raWy-kFHZydPOytwS5Tz1CN14ABe5ruoojfHDVH_Y1shaGaqrpP_9b_l2Zg4Dx87WAC4-wWCNzSijCyKkwqtAQXS9QpfjH79-zmqAloo86dz5DY_H297QDuQZd0-Psi6-hQW2o70lc75DI2pTHWRHVeENRH1sIaWUylGaouXLugIM1ppXLdgyEqf85zGJQxPQUX-ryNOQINn6FBKPw4lfn--2k78U-aCZmPh-Mxx_BStyEOAZPkWwcYiBxcGpU_Wr9tlqedaj-NoTR71mJ5OZFToqYEzcvkk1BKUbPh1li4g1KZ7DhK-FVOivyi8o70c8TN3ygg; u=741582385322747; Hm_lvt_1db88642e346389874251b5a1eded6e3=1582098497,1582385350; cookiesu=381582390368314; Hm_lpvt_1db88642e346389874251b5a1eded6e3=1582390370'}
)
# 微博:
url_weibo = []
headers_weibo = []
url_weibo.append("https://m.weibo.cn/api/container/getIndex?type=uid&value=3191919325&containerid=1076033191919325")
headers_weibo.append({'Referer': 'https://m.weibo.cn/u/3191919325',
'User-Agent': 'Mozilla/5.0'})
url_weibo.append("https://m.weibo.cn/api/container/getIndex?type=uid&value=2301894077&containerid=1076032301894077")
headers_weibo.append({'Referer': 'https://m.weibo.cn/u/2301894077',
'User-Agent': 'Mozilla/5.0'})
# 雪球每7X24小时新闻
url_7 = 'https://xueqiu.com/?category=livenews&tdsourcetag=s_pctim_aiomsg'
headers_7 = {'Referer': 'https://xueqiu.com/u/1314783718',
'User-Agent': 'Mozilla/5.0',
'cookie': 'acw_tc=2760821a15820984687844418edc2e869d8485911ed7c90640c4ba33632f81; s=dx11t858l7; device_id=f3bae24173cc39686f529ebf5b4ab06a; aliyungf_tc=AQAAAFkbfHaZAQsAK8KEddBs2OH7Zmqv; xq_a_token=b2f87b997a1558e1023f18af36cab23af8d202ea; xqat=b2f87b997a1558e1023f18af36cab23af8d202ea; xq_r_token=823123c3118be244b35589176a5974c844687d5e; xq_id_token=eyJ0eXAiOiJKV1QiLCJhbGciOiJSUzI1NiJ9.eyJ1aWQiOi0xLCJpc3MiOiJ1YyIsImV4cCI6MTU4MzE0MzIwMCwiY3RtIjoxNTgyMzg1Mjg3MTgwLCJjaWQiOiJkOWQwbjRBWnVwIn0.Crta07q4xFTBXA1raWy-kFHZydPOytwS5Tz1CN14ABe5ruoojfHDVH_Y1shaGaqrpP_9b_l2Zg4Dx87WAC4-wWCNzSijCyKkwqtAQXS9QpfjH79-zmqAloo86dz5DY_H297QDuQZd0-Psi6-hQW2o70lc75DI2pTHWRHVeENRH1sIaWUylGaouXLugIM1ppXLdgyEqf85zGJQxPQUX-ryNOQINn6FBKPw4lfn--2k78U-aCZmPh-Mxx_BStyEOAZPkWwcYiBxcGpU_Wr9tlqedaj-NoTR71mJ5OZFToqYEzcvkk1BKUbPh1li4g1KZ7DhK-FVOivyi8o70c8TN3ygg; u=741582385322747; Hm_lvt_1db88642e346389874251b5a1eded6e3=1582098497,1582385350; cookiesu=901582391948014; Hm_lpvt_1db88642e346389874251b5a1eded6e3=1582391948'}
# 存储id
id_weibo = []
id_xueqiu = []
id_http = []
for i in zip(url_xueqiu, headers_xueqiu):
temp_r = get_url(i[0], i[1])
temp_need = get_xueqiu(temp_r)
for j in temp_need:
id_xueqiu.append([j['id'], j['user_id']])
for i in zip(url_weibo, headers_weibo):
temp_r = get_url(i[0], i[1])
temp_need = get_weibo(temp_r)
for j in temp_need:
id_weibo.append(j['mblog']['id'])
r_7 = requests.get(url_7, headers=headers_7)
r_7.encoding = "utf-8"
soup = BeautifulSoup(r_7.text, 'html.parser')
new_list = soup.find('div', {'id': 'app'})
new_2 = new_list.find_all_next('table')
for i in new_2:
pre_a = i.find('a')
id_http.append(pre_a.__getitem__('href'))
print("开始监听")
while True:
time.sleep(5)
# 监视雪球
for i in zip(url_xueqiu, headers_xueqiu):
temp_r = get_url(i[0], i[1])
try:
temp_need = get_xueqiu(temp_r)
except:
print("无网络连接")
break
for j in temp_need:
if [j['id'], j['user_id']] not in id_xueqiu:
text_temp = j['text']
text_temp = text_temp.replace(''
, '')
text_temp = text_temp.replace('', '\n')
text_send = j['user']['screen_name'] + "有新消息:\n\n" + text_temp
print(text_send)
xiaohao.send(text_send)
id_xueqiu.append([j['id'], j['user_id']])
# 监视微博
for i in zip(url_weibo, headers_weibo):
temp_r = get_url(i[0], i[1])
try:
temp_need = get_weibo(temp_r)
except:
print("无网络连接")
break
for j in temp_need:
if j['mblog']['id'] not in id_weibo:
text_send = j['mblog']['user']['screen_name'] + "有新消息:\n\n" + j['mblog']['text']
print(text_send)
xiaohao.send(text_send)
id_weibo.append(j['mblog']['id'])
# 7X24小时新闻
try:
r_7 = requests.get(url_7, headers=headers_7)
r_7.encoding = "utf-8"
soup = BeautifulSoup(r_7.text, 'html.parser')
new_list = soup.find('div', {'id': 'app'})
new_2 = new_list.find_all_next('table')
for i in new_2:
pre_a = i.find('a')
if pre_a.__getitem__('href') not in id_http:
text_send = "7*24小时新闻有新消息:\n\n" + pre_a.get_text() + '\n' + pre_a.__getitem__('href')
xiaohao.send(text_send)
print(text_send)
id_http.append(pre_a.__getitem__('href'))
except:
print("无网络连接")