插值方法: 拉格朗日插值--逐步插值的自适应算法
插值方法: 拉格朗日插值--逐步插值的自适应算法
1.问题描述
称为插值节点,所要插值的点x称插值点。
插值计算的目的在于,通过尽可能简便的方法,利用所给数据表加工出插值点x上具有足够精度的插值结果y.
在这种意义,插值过程是个数据加工的过程。
2.理论与方法

多项式的系数与所给的数据点并没有直接的联系,所以我们考虑增加一个多项式的基函数会不会更好,例如,这里
这样一个表达式是很容易进行操作的,对于不同点或插值的公式。
这样一个多项式基函数就是通过Largrange插值构造的,对于n阶多项式满足
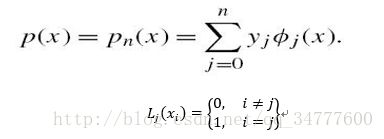

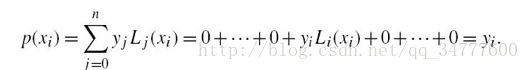
Divided differences and Newton’s form
We have seen thestandard monomial basis , This has led to a relativelyinferior procedure for constructing p= but an easy procedure for evaluating at a given argument x , On the other hand,with the Lagrangepolynomial basis


3.算法设计
根据给定的数据表(xi,yi),i=0,1,...,n及插值点x,根据公式求得插值结果y


在实际计算时可以这样设计计算流程。依与插值点x的距离,事先由近及远顺序排列插值节点x0,x1,...,xn然后逐行生成逐步插值表,每增添一行引进一个新的节点,这一过程直到相邻的两个对角线元素的偏差|Yi,i+1 - Yi-1,i|满足精度要求为止。这就是逐步插值的自适应法。
计算程序:
依与插值点x的距离,事先由近及远地顺序排列插值节点x0,x1,...,xn
逐行生成插值表 对 i=0,1,...,n 计算

检查计算误差 对给定精度e,当|Yi,i+1 - Yi-1,i|< e计算终止,并输出Yi,i+1作为插值结果。
自然停机 当i=n时输出Yn-1,n作为插值结果。
4.案例分析
Example1:
The population in millions of the United States from 1920 to2000 can be tabulated as following
|
Date |
1920 |
1930 |
1940 |
1950 |
1960 |
1970 |
1980 |
1990 |
2000 |
Population |
106.46 |
123.08 |
132.12 |
152.27 |
180.67 |
205.05 |
227.23 |
249.46 |
281.42 |
|
using first-, second-through senventh-order interpolating polynomials to predict the population in2000 based on the most recent data.
拉格朗日多项式:

5.代码
void _3()
{
double p[8];
double x[8] = { 1920,1930,1940,1950,1960,1970,1980,1990 };
double y[8] = { 106.46,123.08,132.12,152.27,180.67,205.05,227.23,249.46 };
double w[8][8], q[8];
for (int i = 1; i < 8; i++)
{
for (int j = 0; j <= i; j++)
{
w[i][j] = 1;
for (int k = 0; k <= i; k++)
{
if (j != k) w[i][j] *= (x[j] - x[k]);
}
w[i][j] = 1 / w[i][j];
// cout << w[i][j] << endl;
}
// cout << endl;
}
//cout << endl;
double xx = 2000;
for (int i = 1; i < 8; i++)
{
q[i] = 1;
for (int j = 0; j <= i; j++)
{
q[i] *= (xx - x[j]);
}
// cout << q[i] << endl;
}
//cout << endl;
for (int i = 1; i < 8; i++)
{
double temp = 0;
for (int j = 0; j <= i; j++)
{
temp += (w[i][j] * y[j]) / (xx - x[j]);
}
p[i] = q[i] * temp;
cout << setw(2) << i << "阶插值结果: " << p[i] << endl;
}
}End