【深度学习】用Keras实现word2vec的CBOW模型
前言
尽管gensim里的word2vec已经非常好用,但用别人的模型始终难以直接解决自己的问题,于是去搜有没有直接能用的Keras版,找到了两版,分别为:
- 版本1:keras训练word2vec代码
- 版本2:【不可思议的Word2Vec】6. Keras版的Word2Vec
两位写的都很好,版本1代码上可以直接上手,版本2框架更清晰,但两位大佬的数据集都是基于多篇文章的,版本1是从微信接口里拿的,但我连接不上服务器;版本二的数据集未给,然后面向对象的写法本人不是很熟就不好改。于是就在学习版本框架理论的同时,在版本1上进行更改。
最终形成在单个文本内进行词向量训练。
数据
随便一个utf-8的中文文档就行,我这里为了求快,节选了《天龙八部》的第一章,记得改下编码utf-8。

停用词
也是网上扒的停用词,据说非常全,最全中文停用词表整理(1893个)。
def stopwordslist(): #设置停用词
stopwords = []
if not os.path.exists('./stopwords.txt'):
print('未发现停用词表!')
else:
stopwords = [line.strip() for line in open('stopwords.txt',encoding='UTF-8').readlines()]
return stopwords
分词
输入一个文档,输出全部原始句子和分好词的句子。
def getdata(fname):
f = open(fname,'r',encoding='UTF-8')
lines = f.readlines()
sentences = []
data = []
stopwords = stopwordslist()
for line in lines:
data.append(line.strip()) #原始句子
sts = list(jieba.cut(line.strip(), cut_all=False)) #分词后
splits = [] #去停用词后
for w in sts:
if w not in stopwords:
splits.append(w)
sentences.append(splits)
f.close()
return data,sentences
建字典
需要非常多的映射关系,这里还有一个降采样表,后面有对其功能的解释。
def bulid_dic(sentences): #建立各种字典
words = {} #词频表
nb_sentence = 0 #总句子数
total = 0. #总词频
for d in sentences:
nb_sentence += 1
for w in d:
if w not in words:
words[w] = 0
words[w] += 1
total += 1
if nb_sentence % 100 == 0:
print (u'已经找到%s个句子'%nb_sentence)
words = {i:j for i,j in words.items() if j >= min_count} #截断词频
id2word = {i+1:j for i,j in enumerate(words)} #id到词语的映射,0表示UNK
word2id = {j:i for i,j in id2word.items()} #词语到id的映射
nb_word = len(words)+1 #总词数(算上填充符号0)
subsamples = {i:j/total for i,j in words.items() if j/total > subsample_t}
subsamples = {i:subsample_t/j+(subsample_t/j)**0.5 for i,j in subsamples.items()} #这个降采样公式,是按照word2vec的源码来的
subsamples = {word2id[i]:j for i,j in subsamples.items() if j < 1.} #降采样表
return nb_sentence,id2word,word2id,nb_word,subsamples
构造训练数据
结合后文的框架图进行分析。
def data_generator(word2id,subsamples,data): #训练数据生成器
x,y = [],[]
_ = 0
for d in data:
d = [0]*window + [word2id[w] for w in d if w in word2id] + [0]*window
r = np.random.random(len(d))
for i in range(window, len(d)-window):
if d[i] in subsamples and r[i] > subsamples[d[i]]: #满足降采样条件的直接跳过
continue
x.append(d[i-window:i]+d[i+1:i+1+window])
y.append([d[i]])
_ += 1
if _ == nb_sentence_per_batch:
x,y = np.array(x),np.array(y)
z = np.zeros((len(x), 1))
return [x,y],z
word2vec
好了,终于到这步了。尽管这个东西出来挺久了,理论解释的人也一大把,但我在未完全自己跑一遍之前,仍是一知半解,似懂非懂,直到我遇到版本2的这一张图。

原谅我孤陋寡闻,原来Keras模型结构还能可视化出来(点个赞,顺便一起实现了)。
众所周知,CBOW是用某一个词的上下文(前面几个和后面几个)去预测它本身,但实现起来,word2vec绝不止这一点,其精华还在负(降)采样和层级softmax,两者都是为了加速而做的优化,我们来顺着这个图理解一下。
先看下参数,我们的window设置为5,那么就是用前5个词和后5个词去预测当前词,所以模型的输入是上下文,也就是10个词,这就是右边的第一个input层。右边的Embedding层也好理解,词向量维度为128,那就成了10*128的张量。再看第一个lambda层,其做的是加法,将10个128维的词向量同一维度直接加在一起形成了一个128维的张量,至此右边完成。
fname = 'corpus.txt' #数据集(语料库) 一个文档
word_size = 128 #词向量维度
window = 5 #窗口大小
nb_negative = 15 #随机负采样的样本数
min_count = 5 #频数少于min_count的词将会被抛弃
nb_worker = 4 #读取数据的并发数
nb_epoch = 2 #迭代次数,由于使用了adam,迭代次数1~2次效果就相当不错
subsample_t = 1e-5 #词频大于subsample_t的词语,会被降采样,这是提高速度和词向量质量的有效方案
nb_sentence_per_batch = 20
#目前是以句子为单位作为batch,多少个句子作为一个batch(这样才容易估计训练过程中的steps参数,另外注意,样本数是正比于字数的。)
再看左边,第二个输入层输入的就是当前词,也就是1个词。第二个lambda层做的是抽样,随机构造15个跟当前词不一样的词作为负样本,通过第三个lambda层拼接到一起。嵌入2次,分别得到W和b,也就是权重和偏置在第四个lambda层完成Dense(Wx+b)和Softmax的操作。
最后一步也就是整个模型的输出就是softmax的值,其有16维实际上是模型预测当前词是正例(1个)和负例(抽样的15个)的概率值,这就做到了通过输入上下文来识别当前词,且识别范围(解空间)由原先的所有词,限制到了负采样个数+1内,这就大大地加快了训练速度。而我们所需要的词向量就是右边的Embeding层,也就是第一个嵌入层的权重。
再对比下model搭建的代码,其实主要就是看每个Lambda层的作用。
def build_w2vm(word_size,window,nb_negative):
K.clear_session() #清除之前的模型,省得压满内存
#CBOW输入
input_words = Input(shape=(window*2,), dtype='int32')
input_vecs = Embedding(nb_word, word_size, name='word2vec')(input_words)
input_vecs_sum = Lambda(lambda x: K.sum(x, axis=1))(input_vecs) #CBOW模型,直接将上下文词向量求和
#构造随机负样本,与目标组成抽样
target_word = Input(shape=(1,), dtype='int32')
negatives = Lambda(lambda x: K.random_uniform((K.shape(x)[0], nb_negative), 0, nb_word, 'int32'))(target_word)
samples = Lambda(lambda x: K.concatenate(x))([target_word,negatives]) #构造抽样,负样本随机抽。负样本也可能抽到正样本,但概率小。
#只在抽样内做Dense和softmax
softmax_weights = Embedding(nb_word, word_size, name='W')(samples)
softmax_biases = Embedding(nb_word, 1, name='b')(samples)
softmax = Lambda(lambda x:
K.softmax((K.batch_dot(x[0], K.expand_dims(x[1],2))+x[2])[:,:,0])
)([softmax_weights,input_vecs_sum,softmax_biases]) #用Embedding层存参数,用K后端实现矩阵乘法,以此复现Dense层的功能
#留意到,我们构造抽样时,把目标放在了第一位,也就是说,softmax的目标id总是0,这可以从data_generator中的z变量的写法可以看出
model = Model(inputs=[input_words,target_word], outputs=softmax)
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
#请留意用的是sparse_categorical_crossentropy而不是categorical_crossentropy
model.summary()
return model
检验(计算TopK个相似度高的单词)
载入模型,取词向量,再求余弦相似度(先归一化再点积)。
def most_similar(word2id,w,k=10): #找相似性Topk个词
#通过词语相似度,检查我们的词向量是不是靠谱的
model = load_model('./word2vec.h5') #载入模型 在数据集较大的时候用空间换时间
# weights = model.get_weights()#可以顺便看看每层的权重
# for wei in weights:
# print(wei.shape)
embeddings = model.get_weights()[0]
normalized_embeddings = embeddings / (embeddings**2).sum(axis=1).reshape((-1,1))**0.5 #词向量归一化,即将模定为1
v = normalized_embeddings[word2id[w]]
sims = np.dot(normalized_embeddings, v)
sort = sims.argsort()[::-1]
sort = sort[sort > 0]
return [(id2word[i],sims[i]) for i in sort[:k]]
效果
由于求快,数据集非常小,词不多,精度不算准,但能用,以下为输入“天龙八部”后结果。
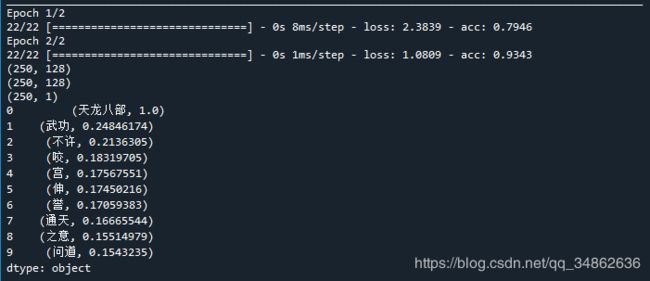
完整代码
需要一个数据文件(txt),一个停用词表(txt),还有一个代码文件(py)。
#! -*- coding:utf-8 -*-
#Keras版的Word2Vec,作者:苏剑林,http://kexue.fm
#Keras 2.0.6 + Tensorflow 测试通过
import numpy as np
from keras.layers import Input,Embedding,Lambda
from keras.models import Model,load_model
from keras.utils import plot_model
import keras.backend as K
import jieba
import pandas as pd
import os
def stopwordslist(): #设置停用词
stopwords = []
if not os.path.exists('./stopwords.txt'):
print('未发现停用词表!')
else:
stopwords = [line.strip() for line in open('stopwords.txt',encoding='UTF-8').readlines()]
return stopwords
def getdata(fname):
f = open(fname,'r',encoding='UTF-8')
lines = f.readlines()
sentences = []
data = []
stopwords = stopwordslist()
for line in lines:
data.append(line.strip()) #原始句子
sts = list(jieba.cut(line.strip(), cut_all=False)) #分词后
splits = [] #去停用词后
for w in sts:
if w not in stopwords:
splits.append(w)
sentences.append(splits)
f.close()
return data,sentences
def bulid_dic(sentences): #建立各种字典
words = {} #词频表
nb_sentence = 0 #总句子数
total = 0. #总词频
for d in sentences:
nb_sentence += 1
for w in d:
if w not in words:
words[w] = 0
words[w] += 1
total += 1
if nb_sentence % 100 == 0:
print (u'已经找到%s个句子'%nb_sentence)
words = {i:j for i,j in words.items() if j >= min_count} #截断词频
id2word = {i+1:j for i,j in enumerate(words)} #id到词语的映射,0表示UNK
word2id = {j:i for i,j in id2word.items()} #词语到id的映射
nb_word = len(words)+1 #总词数(算上填充符号0)
subsamples = {i:j/total for i,j in words.items() if j/total > subsample_t}
subsamples = {i:subsample_t/j+(subsample_t/j)**0.5 for i,j in subsamples.items()} #这个降采样公式,是按照word2vec的源码来的
subsamples = {word2id[i]:j for i,j in subsamples.items() if j < 1.} #降采样表
return nb_sentence,id2word,word2id,nb_word,subsamples
def data_generator(word2id,subsamples,data): #训练数据生成器
x,y = [],[]
_ = 0
for d in data:
d = [0]*window + [word2id[w] for w in d if w in word2id] + [0]*window
r = np.random.random(len(d))
for i in range(window, len(d)-window):
if d[i] in subsamples and r[i] > subsamples[d[i]]: #满足降采样条件的直接跳过
continue
x.append(d[i-window:i]+d[i+1:i+1+window])
y.append([d[i]])
_ += 1
if _ == nb_sentence_per_batch:
x,y = np.array(x),np.array(y)
z = np.zeros((len(x), 1))
return [x,y],z
def build_w2vm(word_size,window,nb_word,nb_negative):
K.clear_session() #清除之前的模型,省得压满内存
#CBOW输入
input_words = Input(shape=(window*2,), dtype='int32')
input_vecs = Embedding(nb_word, word_size, name='word2vec')(input_words)
input_vecs_sum = Lambda(lambda x: K.sum(x, axis=1))(input_vecs) #CBOW模型,直接将上下文词向量求和
#构造随机负样本,与目标组成抽样
target_word = Input(shape=(1,), dtype='int32')
negatives = Lambda(lambda x: K.random_uniform((K.shape(x)[0], nb_negative), 0, nb_word, 'int32'))(target_word)
samples = Lambda(lambda x: K.concatenate(x))([target_word,negatives]) #构造抽样,负样本随机抽。负样本也可能抽到正样本,但概率小。
#只在抽样内做Dense和softmax
softmax_weights = Embedding(nb_word, word_size, name='W')(samples)
softmax_biases = Embedding(nb_word, 1, name='b')(samples)
softmax = Lambda(lambda x:
K.softmax((K.batch_dot(x[0], K.expand_dims(x[1],2))+x[2])[:,:,0])
)([softmax_weights,input_vecs_sum,softmax_biases]) #用Embedding层存参数,用K后端实现矩阵乘法,以此复现Dense层的功能
#留意到,我们构造抽样时,把目标放在了第一位,也就是说,softmax的目标id总是0,这可以从data_generator中的z变量的写法可以看出
model = Model(inputs=[input_words,target_word], outputs=softmax)
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
#请留意用的是sparse_categorical_crossentropy而不是categorical_crossentropy
model.summary()
return model
def most_similar(word2id,w,k=10): #找相似性Topk个词
#通过词语相似度,检查我们的词向量是不是靠谱的
model = load_model('./word2vec.h5') #载入模型 在数据集较大的时候用空间换时间
# weights = model.get_weights()#可以顺便看看每层的权重
# for wei in weights:
# print(wei.shape)
embeddings = model.get_weights()[0]
normalized_embeddings = embeddings / (embeddings**2).sum(axis=1).reshape((-1,1))**0.5 #词向量归一化,即将模定为1
v = normalized_embeddings[word2id[w]]
sims = np.dot(normalized_embeddings, v)
sort = sims.argsort()[::-1]
sort = sort[sort > 0]
return [(id2word[i],sims[i]) for i in sort[:k]]
if __name__ == '__main__':
fname = 'seq.txt' #数据集(语料库) 一个文档
word_size = 60 #词向量维度
window = 5 #窗口大小
nb_negative = 15 #随机负采样的样本数
min_count = 0 #频数少于min_count的词将会被抛弃
nb_worker = 4 #读取数据的并发数
nb_epoch = 2 #迭代次数,由于使用了adam,迭代次数1~2次效果就相当不错
subsample_t = 1e-5 #词频大于subsample_t的词语,会被降采样,这是提高速度和词向量质量的有效方案
nb_sentence_per_batch = 20
#目前是以句子为单位作为batch,多少个句子作为一个batch(这样才容易估计训练过程中的steps参数,另外注意,样本数是正比于字数的。)
data,sentences = getdata(fname) #读原始数据
nb_sentence,id2word,word2id,nb_word,subsamples = bulid_dic(sentences) #建字典
ipt,opt = data_generator(word2id,subsamples,data) #构造训练数据
model = build_w2vm(word_size,window,nb_word,nb_negative) #搭模型
model.fit( ipt,opt,
steps_per_epoch= int(nb_sentence/nb_sentence_per_batch),
epochs=nb_epoch,
workers=nb_worker,
use_multiprocessing=True
)
model.save('word2vec.h5')
plot_model(model, to_file='./word2vec.png',show_shapes=True,dpi=300) #输出框架图
print(pd.Series(most_similar(word2id,'天龙八部')))