最强换脸算法:Few-Shot Adversarial Learning of Realistic Neural Talking Head Models论文解读
今天为大家带来一篇arXiv新上论文,来自三星AI,用于换脸,没错,而且不像deepfake那样要对被换的脸和要换谁的脸,这两个人的脸的大量数据信息。仅仅凭借一张A的脸,就能把视频中B的脸换成A的脸。如果给定A的脸的图像增多,效果也会越好。论文引起了广泛关注,作者也提供了demo视频,在油管上,大家也可以去搜索看看。这篇论文估计是要投ICCV的,目前在arXiv上是第一版,意思就是有些内容有小错误,甚至原理也没说太明白,论文上也没有作者的邮箱,没法咨询他们。我照我的理解讲述。
update on 2019.06.16
我把论文复现的代码开源到了个人GitHub,是一个失败的结果,我只迭代了几百步,发现输出的中间很离谱,具体都在github里面提到,感兴趣可以自行查看。之所以仍然开源是因为想邀请广大朋友成为contributor,也许有人能基于我的工作真的复现出来呐。(╹▽╹)
update on 2019.06.22
我从第一作者的别的论文找到了其邮箱,他回答了我的问题。

虽然解答了我的疑惑,但目前并没有时间去完善工程。留给以后吧。_

摘要
目前换脸(其实论文中叫做talking head model)模型(其实论文中叫做talking head model,就是把那种人头占很大面积,同时人在说话的视频片段,类似于给节目主持人特写镜头)都需要一个人脸的大量图像,然后基于这些一个人的人脸图像训练,才能得到不错的效果。作者提出了一种仅仅几张(few shot)目标人脸图像,就能将视频中其他的人脸换成目标人脸,且效果极其逼真,好到都能让蒙娜丽莎等名画中的肖像人脸动起来。
作者用了以下技术
- 基于GAN的元学习,在一个大数据集上训练,在测试阶段,仅仅需要几张目标人脸,就能做很好的域的迁移。使用对抗学习策略(GAN)
- 在测试阶段,元学习可以为生成器和判别器的参数用适合目标人脸的初始化方式。意思是训练的参数不是测试的参数,需要用一个映射矩阵去初始化,后面我们也能看到。
最后,这篇论文借鉴了很多风格迁移和GAN网络的思路。包括adaptive instance normalization, spectral normalization, self attention 等,复现起来应该蛮难的。三星估计也不会考虑开源这项技术。
方法
设 x i x_i xi是数据集视频序列中的第i个序列, x i ( t ) x_i(t) xi(t)是第i个序列的第t帧,论文使用【1】中的方法对所有样本提取了对应的关键点,并把这些关键点连接成线。

左图是一个 x i ( t ) x_i(t) xi(t),右图是对应的landmarks,记作 y i ( t ) y_i(t) yi(t)
整个模型分为三个部分
- Embedder:一个编码结构,输入 x i ( s ) , y i ( s ) x_i(s),y_i(s) xi(s),yi(s),,输出一个N维向量,记作 e ^ i \widehat{e}_i e i,设 ϕ \phi ϕ是Embedder的训练参数
- 生成器G:输入landmarks y i ( t ) y_i(t) yi(t),注意t和Embedder的s是不一样的,意思是 y i ( t ) y_i(t) yi(t)对应的原图没有出现在Embedder中,没有参与计算 e ^ i \widehat{e}_i e i;同时输入 e ^ i \widehat{e}_i e i,输出假图像 x ^ i ( t ) \widehat{x}_i(t) x i(t)。 G的训练参数可以分为两个部分,一个是 ψ \psi ψ,另一个是 ψ ^ i \widehat{\psi}_i ψ i,前者是person-generic 参数,后者是person-specific 的参数。但后者不是直接训练得到的,而是经过一个变换得到的: ψ ^ i = P e ^ i \widehat{\psi}_i=P\widehat{e}_i ψ i=Pe i,P是可训练的投影矩阵(这个P也是很关键的,是元学习之所以能快速的迁移到不同域的关键,在测试阶段会讲解)。
- 判别器D:输入真假图像 x i , x ^ i x_i,\widehat{x}i xi,x i中的一个,输入 y i ( t ) y_i(t) yi(t)和视频序列编号 i i i,输出真实度分数,评价x是真图像还是假图像,还评价x和 y i ( t ) y_i(t) yi(t)的位置拟合程度,就是说x的人脸的关键点是不是在对应的 y i ( t ) y_i(t) yi(t)上。判别器的参数有些多,有 θ , W , w 0 , b \theta,W,w_0,b θ,W,w0,b。其中 θ \theta θ是D中的卷积网络的部分。D中还有做矩阵运算的部分。
下面我将介绍每个模块的作用。
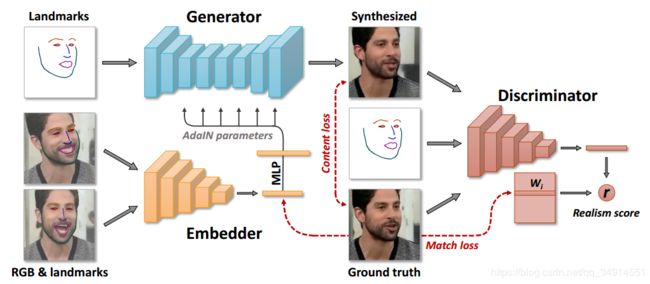
- Embedder: 论文说这个模块的作用是学到一个视频(域)的特有的信息(比如这个人的身份不变性),同时希望具有姿态的不变性。我们可以认为和人脸识别网络一样,一个视频对应一个特征,视频中的人脸图像的特征应该和整个视频的特征距离不大;不同视频的特征距离差很大。
- 生成器G: 就是生成假图像了,没的说了。值得关注的是,上图中的G有一部分输入来自于Embedder,其中Adain就是adaptive instance normalization。我的理解是,G根据landmark给出的脸型,用Embedder学到的特定的人脸信息按照给定的脸型补全,从而实现换脸的效果。
- 判别器D: 判别器有两部分。第一部分是编码器网络,将图像编码为向量。之后还有一个W去和向量相乘的操作,从损失函数可以见端倪。
元学习阶段(训练阶段)
生成器损失函数
因为采用对抗学习,所以有两个损失函数交替训练。
现在从一个视频序列中随意选取一帧记作t,再冲这个序列中选取K张不同于t的帧,这K帧记作 s 1 , . . . s k s_1,...s_k s1,...sk。我们计算 e ^ i \widehat{e}_i e i
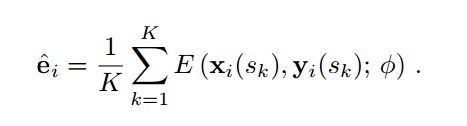
把 e ^ i \widehat{e}_i e i和第t帧对应的 y i ( t ) y_i(t) yi(t)送到G中,得到了假图像 x ^ i ( t ) \widehat{x}_i(t) x i(t),

我们已经得到了Embedder和G的所有必要的东西了,接下来就看看第一个损失函数

由三个部分组成:
- L C N T L_{CNT} LCNT表示 x i ( t ) x_i(t) xi(t)和 x ^ i ( t ) \widehat{x}_i(t) x i(t)的重建相似度。至于如何描述重建相似度,和风格迁移中的内容损失函数很相似,见【2】

- 第二项是对抗项,形式如下:


D值越大说明图像越真,那么整个对抗项越小。其中的 L F M L_{FM} LFM涉及到【3】,用来评估特征的相似程度,也帮助训练更加稳定。V是判别器卷积部分的输出,也是一个向量,和一个W的第i列相乘,至于 w 0 , b w_0,b w0,b论文说是训练参数,但不依赖于特定的视频序列。
- 损失函数第三项 L M C H L_{MCH} LMCH,用于优化两个向量的相似度,让这两个向量越相似。之前提到Embedder的输出是一个向量,判别器的卷积部分的输出也是一个向量,就是这两个向量。使用L1-differnet,就是L1 loss了
关于 D中的卷积部分V的学习的个人疑问
我们看到V和W相乘,想让D更大,意味着V的最优方向是每个元素和 W i W_i Wi是相同的正负号就行了,那这个式子是没有上界的啊,只要V满足正负号相同,数值越大就越好。个人没能理解这一点。需要看引用到的其它文献来理解
判别器损失函数
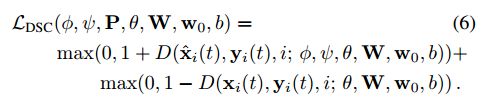
L D S C L_{DSC} LDSC括号中的内容全是判别器需要用到的参数,其中第一个来自Embedder,之后两个来自生成器;第三个参数,即 θ \theta θ是判别器卷积部分的参数,之后的 W , w 0 , b W,w_0,b W,w0,b也是训练参数。前三个参数不需要参与判别器的训练,后四个才是判别器需要优化的部分。
可以发现,判别器的损失函数是hinge loss,我们之前说了,D的输出越大,表示输入越可能是真样本。判别器的优化目的当然是想让假样本的D值小,真样本的D值大,照着这样的逻辑,我们发现 L D S C L_{DSC} LDSC确实为0的。其中最优的情况是假样本的D值为-1,真样本的D值为1。
W的作用
之前提到,W的第i列参与 x i x_i xi这个序列的计算:

W的每一列对应一个序列的向量,同时还有一个项 L M C H L_{MCH} LMCH,作用是将 W i W_i Wi和 e ^ i \widehat{e}_i e i优化距离,使二者尽量相似。那么大家应该知道,W的作用是啥了。 e ^ i \widehat{e}_i e i仅仅涉及到K张同一序列的一个人的表征,因为仅仅用到了K张所以表述应该没有很全面。但随着训练的进行,K会遍历一个序列的全部帧,同时优化W和e的距离,那么 W i W_i Wi可以看做是一个序列中针对一个人更普适性更准确的表达向量。
测试阶段
当元学习收敛之后,模型就能用一个模型没有见过的人脸A生成一个视频序列,这个视频序列的人脸B被替换成A。
假设我们给了A的脸有T张,(这里T当然可以等于1,但是为了生成更好的脸,T一般都不为1。)和对应的T张landmarks,分别记作 x ( 1 ) , x ( 2 ) . . . x ( T ) x(1),x(2)...x(T) x(1),x(2)...x(T),和 y ( 1 ) , y ( 2 ) , . . . y ( T ) y(1),y(2),...y(T) y(1),y(2),...y(T)。我们用Embedder计算这个人脸的平均表征向量(一般是一个人特有一个表征向量,不同人的表征向量距离应该差很大。)
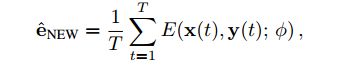
一种直接的办法是用想替换的视频中的landmark, e ^ N E W \widehat{e}_{NEW} e NEW输入到G中,直接就能实现换脸的,但是作者发现这样生成的脸仅仅能认为像,得到的结果还不够真。为了弥补应用在不同域带来的误差,作者提出一种finetuning的方式(可以认为是在线训练,但速度很快,且不用大量的数据增强,仅仅靠几张图片)
在训练环节,我们提到生成器的参数分为两部分,一个是 ψ \psi ψ,另一个是 ψ ^ i \widehat{\psi}_i ψ i,后者是用过一个映射 ψ ^ i = P e ^ i \widehat{\psi}_i=P\widehat{e}_i ψ i=Pe i优化的,所以在训练阶段,参与训练的其实是 ψ \psi ψ和P。
finetuning操作按照下列步骤:
- 经过训练得到的模型初始化参数之后, ψ ′ \psi' ψ′用 ψ ′ = P e ^ N E W \psi'=P\widehat{e}_{NEW} ψ′=Pe NEW初始化,之后 ψ ′ \psi' ψ′直接加入训练,而不是依靠P的映射间接参与训练。换言之,P在测试中起的作用就是初始化罢了。我认为P加速了域的迁移,我们在训练过程优化P来优化G的第二部分参数,通过大量的序列,P应该学到了更普适的信息;在测试的时候,仅仅用P初始化G的第二部分参数 ψ ′ \psi' ψ′,然后更新 ψ ′ \psi' ψ′来使得G更快适应于另一个域(测试集)。
- 判别器D的形式也发生了变化:

V还是D的卷积部分的输出,和训练阶段一致。 w ′ w' w′代替了 W i + w 0 W_i+w_0 Wi+w0, w ′ w' w′未涉及到训练中的任何部分,所以如何给 w ′ w' w′初始化便是一个关键。
之前说到,W的每一列对应一个训练集中的视频,所以W可以被认为是训练集专有的,W的列是训练序列中的人物的特有表征。同时别忘了G的损失的第三项的作用,是让 W i W_i Wi和 e ^ i \widehat{e}_i e i相似啊。那么我们初始化 w ′ w' w′的时候就可以这么做:
w ′ = e ^ N E W + w 0 w'=\widehat{e}_{NEW}+w_0 w′=e NEW+w0
( 真他娘的机智!!!以后有必要了解下元学习)
接着就是对抗学习训练,但这个阶段仅仅训练很少的迭代次数就行了。下图是finetuning细节,可以看到和训练阶段是一致的。

实现细节
因为这个方法涉及到了很多其他论文的成果吗,所以在implemantation details部分,论文说的不是很清楚,大部分是引用来说明。不过我还是大致说下。
- 生成器的结构是采用了【2】中结构,但是用残差结构代替了下采用和上采样(啥意思,意思是使用的全是不改变分辨率的卷积吗??!!)同时用instance normalization代替BN;我有一点没有明白,总结构图中的adain 到底是什么样的操作啊

- 接下来是Embedder和D,

他们使用的结构是大致一致的,更细致的内容还是推荐去看论文。博客主要介绍思路。 - 另外还有用到spectral normalization和自注意力(self-attention)。关于自注意力可以查看我的另一篇博文。
实验效果

左边的数字代表测试所用的图像数目,可以发现即便用一张,换出来的人都很逼真了。用32张几乎看不出是假脸。

甚至能让肖像也跟随一个视频中人脸的动作和表情,实现让画动起来的神奇操作!!想想一下爱因斯坦在给你上物理课,想想一下康熙皇帝的画像动起来再讲述他的故事。多么有趣啊。
参考文献
[1] How far are we from solving the 2d & 3d face alignment problem?
[2] Perceptual losses for real-time style transfer and super-resolution
[3] High-resolution image synthesis and semantic manipulation with conditional gans
最后
我会尝试复现一下,计划用两个月吧,毕竟牵扯到很多其他的论文。慢慢啃