Python数据统计与可视化
目录
1. 数据获取:
1.1 数据爬取
1.2 数据下载
2. 数据准备
2.1 数据整理
2.2 数据显示
2.3 数据选择
2.3.1 选择
2.3.2 筛选
3. 简单的统计与处理
3.1 简单统计与筛选
3.2 排序
3.3 计数统计
3.4 Grouping(分组)
3.5 merge
4. 聚类分析
5. Matplotlib
5.1 基础
5.2 图像属性
5.3 pandas绘图
6. 数据存储
6.1 csv数据格式
6.2 excel数据格式
7. python的理工类应用
学习笔记
1. 数据获取:
1.1 数据爬取
代码如下:
import requests
import re
import pandas as pd
def retrieve_dji_list():
try:
r = requests.get('http://money.cnn.com/data/dow30/')
except ConnectionError as err:
print(err)
search_pattern = re.compile(
'class="wsod_symbol">(.*?)<\/a>.*?(.*?)<\/span>.*?\n.*?class="wsod_stream">(.*?)<\/span>')
dji_list_in_text = re.findall(search_pattern, r.text)
dji_list = []
for item in dji_list_in_text:
dji_list.append([item[0], item[1], float(item[2])])
return dji_list
dji_list = retrieve_dji_list()
djidf = pd.DataFrame(dji_list)
print(djidf) import requests
import re
import json
import pandas as pd
def retrieve_quotes_historical(stock_code):
quotes = []
url = 'http://finance.yahoo.com/quote/%s/history?p=%s' % (stock_code, stock_code)
try:
r = requests.get(url)
except ConnectionError as err:
print(err)
m = re.findall('"HistoricalPriceStore":{"prices":(.*?),"isPending"', r.text)
if m:
quotes = json.loads(m[0]) # m = ['[{...},{...},...]']
quotes = quotes[::-1] # 原先数据为date最新的在最前面
return [item for item in quotes if not 'type' in item]
quotes = retrieve_quotes_historical('AXP')
quotesdf = pd.DataFrame(quotes)
# quotesdf = quotesdf_ori.drop(['adjclose'], axis = 1) 可用本语句删除adjclose列
print(quotesdf)
1.2 数据下载
数据下载直接网址:https://finance.yahoo.com/quote/AXP/history?p=AXP
读入:
import pandas as pd
quotestdf = pd.read_csv(r'D:\my_python_code\my_game\AXP.csv')使用网站提供api:豆瓣图书API
import requests
r = requests.get('https://api.douban.com/v2/book/1084336')
print(r.status_code)
利用语料库:
NLTK语料库
import nltk
nltk.download()出现界面,下载所需
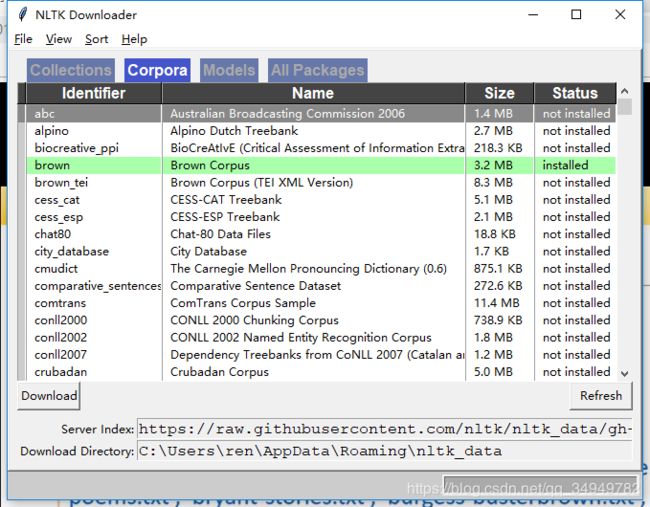
然后加载:
from nltk.corpus import brown
print(brown.fileids())2. 数据准备
对djidf加行索引与列索引,接上第一段代码:
cols = ['code','name','lasttrade']#
djidf.columns = cols
djidf.index = range(1,len(djidf)+1)数据准备(预处理)过程中常常需要进行数据的处理,例如数据清洗包括缺失值和异常值处理,数据变换如规范化数据,数据规约如属性规约(选择部分有代表性的属性)等,在Python有很多进行数据预处理的快速方法,以数据清洗中的缺失值处理为例,在实际过程中常常会发现有的数据是缺失(NaN)的,这些值是需要特别处理的。缺失值的判断可利用numpy中的isnan()函数,而对于Series或DataFrame,缺失值的判断和处理非常的方便,例如df.dropna()可以删掉含NaN(NA)的行df.dropna(how='all')只丢弃全为NaN的那些行,也可以进行值的插补,例如用0、均值、中位数或众数等进行填充插补,也可用插值法即基于已知点建立插值函数f(x),通过xi求得f(xi)来近似替代,常用方法有拉格朗日插值法和牛顿插值法NaN。以常用的简单填充为例,可用df.fillna(某一个值)方式用某一个值如0或平均值等代替NaN(例如df.fillna(0)表示用0代替NaN),也可用其method参数指定缺失值的填充方向,例如:
>>> fruit_df = pd.Series(['apple', 'orange', 'pear'], index=[0, 2, 5])
>>> fruit_df = fruit_df.reindex(range(7))
>>> fruit_df
0 apple
1 NaN
2 orange
3 NaN
4 NaN
5 pear
6 NaN
dtype: object
# inplace参数设为True表示直接修改原对象fruit_df,否则将填充后的结果返回,原对象不变
>>> fruit_df.fillna(method='ffill', inplace = True)
>>> print(fruit_df)
0 apple
1 apple
2 orange
3 orange
4 orange
5 pear
6 pear
dtype: objectffill表示用前一个非缺失值代替NaN填充,而bfill表示用下一个非缺失数据代替NaN填充,要根据数据的特点选择不同的填充方式,
>>> fruit_df = pd.Series(['apple', 'orange', 'pear'], index=[0, 2, 5])
>>> fruit_df = fruit_df.reindex(range(7))
>>> fruit_df.fillna(method='bfill', inplace = True)
>>> print(fruit_df)
0 apple
1 orange
2 orange
3 pear
4 pear
5 pear
6 NaN
dtype: object2.1 数据整理
时间戳使用:
from datetime import date
firstday = date.fromtimestamp(1464010200)
lastday = date.fromtimestamp(1495200600)

创建时间序列

例如:
import numpy as np
import pandas as pd
dates = pd.date_range('20181001', periods = 10)
listA = ['value']
result = pd.DataFrame(np.arange(1,11), index = dates,columns = listA)
print(result)2.2 数据显示
通过前面的处理得到,以下形式的数据
 djidf
djidf
 quotes
quotes
- 显示方式
- 行索引
- 列索引
- 数据值
- 数据描述
- 数据格式
print(list(djidf.index))
print(list(djidf.columns))
print(djidf.values)
print(djidf.describe())
djidf.dtype数据处理要转换格式,转换为float类型,代码参照
for item in dji_list_in_text:
dji_list.append([item[0], item[1], float(item[2])])
return dji_list查看数据细节
- 显示方式
- 显示行
- 显示列
#专用方法
djidf.head(5)
djidf.tail(5)
#切片
print(djidf[:5])
djidf[-5:]#注意顺序
注意,djidf[:5,:],是错误方法(擅长MATLAB,容易犯的错误),djidf不是矩阵,是表格型数据结构,类型如下:

其它显示
djidf.shape等
2.3 数据选择
选择方式,行、列、区域、筛选
2.3.1 选择
#行,索引方式
quotesdf['2017-05-01':'2017-05-05']
#列,采用列名
djidf['code']
#或
djidf.code
注意,不支持下面这种形式
djidf['code','lasttrade']
djidf['code':'lasttrade'].loc
使用位置(location),进行数据的选择。采用loc类,方式如下:
.loc[行标签,列标签]例如:
djidf.loc[1:5,]
djidf.loc[1:5,['code','lasttrade']]
djidf.loc[1,'lasttrade']#一个值可用
djidf.at[1,'lasttrade'].iloc
.iloc与.loc的区别,左闭右开,采用物理位置,用数字,例如:
djidf.loc[1:5,['code','lasttrade']]
#等价
djidf.iloc[1:6,[0,2]]注,单个值形如矩阵取法iloc与iat
.ix
pandas中还有另外一个常用的ix,它是loc和iloc的混合,它支持这两种方式可使用的方法。例如,假设有一个DataFrame:
cores
Name Chinese Python
a Wangwang 87 86
b Xiaoxiao 93 94
c Linlin 75 86
d Dudu 97 68
e Cuicui 85 98>>> scores.ix['a']
Name Wangwang
Chinese 87
Python 86
Name: a, dtype: object
>>> scores.ix[0]
Name Wangwang
Chinese 87
Python 86
Name: a, dtype: object>>> scores.ix[:,['Python']]
Python
a 86
b 94
c 86
d 68
e 98
>>> scores.ix[:,[2]]
Python
a 86
b 94
c 86
d 68
e 98以上例子可以看出ix确实是混合了loc和iloc两种使用方式,因此ix在pandas的数据选择中也是很常用的。
scores.ix['b':'d',['Chinese','Python']]
#等价于
scores.ix[1:4,[1,2]]
#结果
Chinese Python
b 93 94
c 75 86
d 97 682.3.2 筛选
quotes[(quotesdf.index>='2017-03-01')&(quotesdf.index<='2017-03-31')&(quotesdf.close>=80)]3. 简单的统计与处理
3.1 简单统计与筛选
- 1 求道指成分股中 30只股票最近一 次成交价的平均值? 股票最近一次成交价大于等于180的 公司名?
print(djidf.lasttrade.mean())
djidf[djidf.lasttrade>=180].name- 2 .统计美国运通公司近一年股票涨和跌分别的天数?
len(quotesdf[quotesdf.close>quotesdf.open])
len(quotesdf)-123 - 3. 统计美国运通公司近一年相邻两天收盘价的涨跌情况?
.diff 计算相邻对象之间是增加还是减少
.sign取符号函数
status = np.sign(np.diff(quotesdf.close))
print(status[np.where(status == 1)].size)
status[np.where(status == -1)].size
3.2 排序
-
1. 按最近一次成交价对30只道指成分股股票进行排序。根据排序结果列出前三甲公司名。
tempdf = djidf.sort_values(by = 'lasttrade', ascending = False)
tempdf[:3].name 3.3 计数统计
- 1. 统计2017年度1月份的股票开盘天数?
>>> t = quotesdf[(quotesdf.index >= '2017-01-01') & (quotesdf.index < '2017-02-01')]
>>> len(t) - 2. 统计近一年每个月的股票开盘天数?
listtemp = []
for i in range(len(quotesdf)):
temp = time.strptime(quotesdf.index[i],"%Y-%m-%d")
listtemp.append(temp.tm_mon)
tempdf = quotesdf.copy()
tempdf['month'] = listtemp
print(tempdf['month'].value_counts())
3.4 Grouping(分组)
分组
- 1. 统计近一年每个月的股票开盘天数?
x = tempdf.groupby('month').count()
print(x.close)
- 2. 统计近一年每个月的总成交量?
tempdf.groupby('month').volume.sum() 3.5 merge
合并
.append方法
- 把美国运通公司 本年度1月1日 至1月5日间的 股票交易信息合 并到近一年中前 两天的股票信息中?
p = quotesdf[:2]
q = quotesdf['2017-01-01':'2017-01-05']
p.append(q)
.concat方法
- 将美国运通 公司近一年 股票数据中 的前5个和 后5个合并。
pieces = [tempdf[:5], tempdf[len(tempdf)-5:]]
pd.concat(pieces)两个不同逻辑结构 的对象连接
piece1 = quotesdf[:3]
piece2 = tempdf[:3]
pd.concat([piece1,piece2], ignore_index = True).join方法
pd.merge(djidf.drop(['lasttrade'], axis = 1), AKdf, on = 'code')4. 聚类分析
聚类无标签
方法一:
import numpy as np
from scipy.cluster.vq import vq, kmeans, whiten
list1 = [88.0, 74.0, 96.0, 85.0]
list2 = [92.0, 99.0, 95.0, 94.0]
list3 = [91.0, 87.0, 99.0, 95.0]
list4 = [78.0, 99.0, 97.0, 81.0]
list5 = [88.0, 78.0, 98.0, 84.0]
list6 = [100.0, 95.0, 100.0, 92.0]
data = np.array([list1,list2,list3,list4,list5,list6])
whiten = whiten(data)#算出各列元素的标准差
centroids,_ = kmeans(whiten, 2)#对数据进行聚类,分为两类,返回元组
result,_= vq(whiten, centroids)#矢量量化函数
print(result)方法二:
import numpy as np
from sklearn.cluster import KMeans
list1 = [88.0,74.0,96.0,85.0]
list2 = [92.0,99.0,95.0,94.0]
list3 = [91.0,87.0,99.0,95.0]
list4 = [78.0,99.0,97.0,81.0]
list5 = [88.0,78.0,98.0,84.0]
list6 = [100.0,95.0,100.0,92.0]
X = np.array([list1,list2,list3,list4,list5,list6])
kmeans = KMeans(n_clusters = 2).fit(X)
pred = kmeans.predict(X)
print(pred)
分类,有标签,列如:
from sklearn import datasets
from sklearn import svm
clf = svm.SVC(gamma=0.001, C=100.)
digits = datasets.load_digits()
clf.fit(digits.data[:-1], digits.target[:-1])#对前n-1项训练
clf.predict(digits.data[-1])#最后一项进行预测5. Matplotlib
主要用于二维绘图,pyploy模块(绘图API)、pylab模块(集成库)
官网https://matplotlib.org/index.html#
5.1 基础
折线图
import matplotlib.pyplot as plt
…
x = closeMeansKO.index
y = closeMeansKO.values
plt.plot(x, y)
#绘制多条
import numpy as np
import matplotlib.pyplot as plt
t=np.arange(0.,4.,0.1)
plt.plot(t, t, t, t+2, t, t**2)
散点图
仅仅加上参数‘o’
plt.plot(x,y,'o')柱状图
plt.bar(x,y)pylab绘图
import numpy as np
import pylab as pl
t=np.arange(0.,4.,0.1)
pl.plot(t,t,t,t+2,t,t**2)
5.2 图像属性
属性在官网上看
例如:
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(0, 1)
y = np.sin(4 * np.pi * x) * np.exp(-5 * x)
plt.plot(x,y,'r--')#注意属性位置
plt.show()#一定要加show,否则不会显示图像
看列:
import pylab as pl
import numpy as np
pl.figure(figsize=(8,6),dpi=100)#figsize图的大小,dpi图的精度
t=np.arange(0.,4.,0.1)
pl.plot(t,t,color='red',linestyle='-',linewidth=3,label='Line 1')
pl.plot(t,t+2,color='green',linestyle='',marker='*',linewidth=3,label='Line 2')
pl.plot(t,t**2,color='blue',linestyle='',marker='+',linewidth=3,label='Line 3')
pl.legend(loc='upper left')#标签位置
pl.show()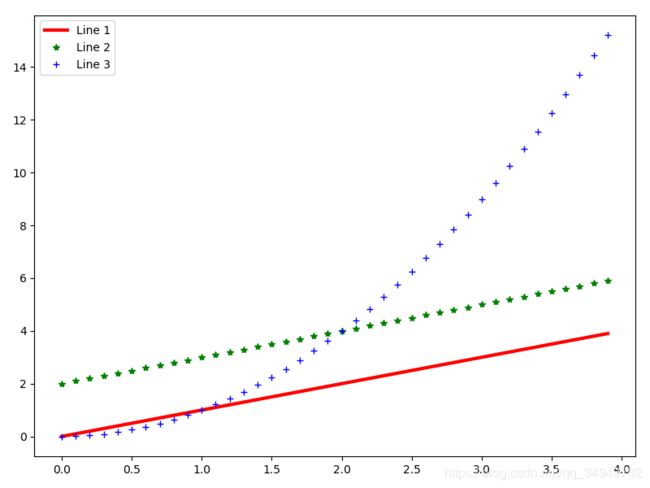 效果
效果
subplot(多张子图)
plt.subplot(211)
plt.plot(x,y,color='r',marker='o')
plt.subplot(212)
plt.plot(xi,yi,color='green',marker='o')
import matplotlib.pyplot as plt
fig, (ax0, ax1) = plt.subplots(2, 1) # 2行1列
ax0.plot(range(7), [3, 4, 7, 6, 2, 8, 9], color='r', marker='o')
ax0.set_title('subplot1') # 设置子图的标题
plt.subplots_adjust(hspace=0.1)#调整两个子图之间的距离,这里是垂直方向的距离
ax1.plot(range(7), [5, 1, 8, 2, 6, 9, 4], color='green', marker='o')
ax1.set_title('subplot2')
plt.show()子图
plt.axes([.1,.1,0.8,0.8])
plt.plot(x,y,color='green',marker='o')
plt.axes([.3,.15,0.4,0.3])
plt.plot(xi,yi,color='r',marker='o')
plt.savefig('1.jpg')
注意:plt与pl的区别。axes([left,bottom,width,height]) 参数范围为(0,1)
5.3 pandas绘图
能基于serise与datafrme绘图
例如:
plt.title('Stock Statistics of Coca-Cola')
plt.xlabel('Month')
plt.ylabel('Average Close Price')
plt.plot(closeMeansKO)
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
x = np.linspace(0, 1)
y = np.sin(4 * np.pi * x) * np.exp(-5 * x)
t = pd.DataFrame(y, index=x)
t.plot()
plt.show()- 绘制IBM公司近一年来的股票收 盘价折线图
quotes = retrieve_quotes_historical('IBM')
quotesdfIBM = pd.DataFrame(quotes)
quotesdfIBM.close.plot()
- 用柱状图比较Intel和IBM这 两家科技公司近一年来股票成交量
INTC_volumes = create_volumes('INTC')
IBM_volumes = create_volumes('IBM')
quotesIIdf = pd.DataFrame()
quotesIIdf['INTC'] = INTC_volumes
quotesIIdf['IBM'] = IBM_volumes
quotesIIdf.plot(kind = 'bar')#barh
- 用柱状图比较Intel和IBM这 两家科技公司近一年来的股 票成交量
quotesIIdf.plot(kind='bar',stacked = True)#quotesIIdf.plot(kind='bar')- Intel公司本年度前3个 月每个月股票收盘价 的占比
#饼图
quotesINTC.plot(kind = 'pie', subplots = True, autopct = '%.2f')#quotesINTC.plot()
quotesIIdf.plot(marker='v')
quotesIIdf.boxplot()
#箱型图
箱型图,有最值、中位数、分位数等
6. 数据存储
6.1 csv数据格式
列如:
将下列数据存入csv,再读入,并输出歌名
Singer Song
The rolling stones Satisfaction
Beatles Let It Be
Guns N' Roses Dont' Cry
Metallica Nothing Else Matters代码:
import pandas as pd
singer_data =['The rolling stones ','Beatles','Guns N','Roses','Metallica']#形成列表数据
song_data = ['Satisfaction',' Let It Be',"Dont' Cry" ,' Nothing Else Matters']
data = zip(singer_data,song_data)#打包成元组
list_data = [X for X in data]#采用例表解析,生成例表
df = pd.DataFrame(list_data,index=range(1,len(singer_data)),columns=['Singer','Song'])#转化为DataFrame,加上行列索引
df.to_csv('C:\\Users\\ren\\Desktop\\df.csv')#存为csv,采用//避免与转义字符弄混
result = pd.read_csv('C:\\Users\\ren\\Desktop\\df.csv')#读入,会在原数据上加上一列,放在第0列
print(result.Song)#也可用print(result['Song'])6.2 excel数据格式
跟csv处理相似,列子:
import pandas as pd
from scipy.interpolate import lagrange # 导入拉格朗日插值函数
list1 = list('abcdef')
str1 = '56.0 NaN 67.0 97.0 NaN 82.0'
list2 = str1.split(' ')
str2 = '87.0 89.0 66.0 NaN 92.0 75.0'
list3 = str2.split(' ')
str3 = '90.0 78.0 75.0 NaN 74.0 NaN'
list4 = str3.split(' ')
data = zip(list1,list2,list3,list4)
list_f = [X for X in data]
data_df = pd.DataFrame(list_f,columns=['name','A','B','C'])
#写入
data_df.to_excel('C:\\Users\\ren\\Desktop\\nan.xlsx')
#读入
df = pd.read_excel("C:\\Users\\ren\\Desktop\\nan.xlsx")
#拉格朗日插值
for i in df.columns:
for j in range(len(df)):
if (df[i].isnull())[j]: # 如果为空则进行插值
k = 3 # 设置取前后数的个数为3,默认为5
y = df[i][list(range(j - k, j)) + list(range(j + 1, j + 1 + k))]
y = y[y.notnull()] # 去掉取出数中的空值
df[i][j] = lagrange(y.index, list(y))(j)
print(df)
#两列求和,并更新
import pandas as pd
stu_df = pd.DataFrame()
stu_df = pd.read_excel('stu_scores.xlsx', sheet_name = 'scores')
stu_df['sum'] = stu_df['Python'] + stu_df['Math']
stu_df.to_excel('stu_scores.xlsx', sheet_name = 'scores')7. python的理工类应用
- 简单的三角函数计算
import numpy as np
import pylab as pl
x = np.linspace(-np.pi, np.pi, 256)
s = np.sin(x)
c = np.cos(x)
pl.title('Trigonometric Function')
pl.xlabel('X')
pl.ylabel('Y')
pl.plot(x,s)
pl.plot(x,c)
- 一组数据的快速傅里叶变换
import scipy as sp
import pylab as pl
listA = sp.ones(500)
listA[100:300] = -1
f = sp.fft(listA)
pl.plot(f)
- 图像处理库

from PIL import Image
#加水印
im1 = Image.open('1.jpg') #打开图片
print(im1.size, im1.format, im1.mode) #大小、格式、模式
Image.open('1.jpg').save('2.png') #存为
im2 = Image.open('2.png')
size = (288, 180)
im2.thumbnail(size) #创建缩略图
out = im2.rotate(45) #旋转45
im1.paste(out, (50,50))#将out放在第一张图上8. PYTHON的人文社科类应用
NLTK语料库