Akka 指南 之「集群的使用方法」
温馨提示:Akka 中文指南的 GitHub 地址为「akka-guide」,欢迎大家
Star、Fork,纠错。
集群的使用方法
注释:本文描述了如何使用 Akka 集群。
文章目录
- 集群的使用方法
- 依赖
- 简单的项目
- 何时何地使用 Akka 集群?
- 微服务
- 传统的分布式应用
- 分布式整体
- 一个简单的集群示例
- 联接到种子节点
- 联接已配置的种子节点
- 使用 Cluster Bootstrap 自动联接种子节点
- 使用 joinSeedNodes 编程联接到种子节点
- Downing
- Auto-downing (DO NOT USE)
- Leaving
- WeaklyUp 成员
- 订阅集群事件
- Worker Dial-in Example
- 节点角色
- 如何在达到群集大小时启动
- 如何清理 Removed 状态的成员
- 更高级别的群集工具
- Cluster Singleton
- Cluster Sharding
- Distributed Publish Subscribe
- Cluster Client
- Distributed Data
- Cluster Aware Routers
- Cluster Metrics
- 故障检测器
- 如何测试?
- 管理
- HTTP
- JMX
- 命令行
- 配置
- Cluster Info Logging
- Cluster Dispatcher
- 配置兼容性检查
有关 Akka 集群概念的介绍,请参阅「集群规范」。
Akka 集群的核心是集群成员(cluster membership),以跟踪哪些节点是集群的一部分以及它们的健康状况。
依赖
为了使用 Akka 集群,你必须在你的项目中添加如下依赖:
<dependency>
<groupId>com.typesafe.akkagroupId>
<artifactId>akka-cluster_2.11artifactId>
<version>2.5.19version>
dependency>
dependencies {
compile group: 'com.typesafe.akka', name: 'akka-cluster_2.11', version: '2.5.19'
}
libraryDependencies += "com.typesafe.akka" %% "akka-cluster" % "2.5.19"
简单的项目
你可以查看「集群示例」项目,以了解 Akka 集群的实际使用情况。
何时何地使用 Akka 集群?
如果你打算使用微服务架构或传统的分布式应用程序,则必须进行架构的选择。这个选择将影响你应该如何使用 Akka 集群。
微服务
微服务(Microservices)具有许多吸引人的特性,例如,微服务的独立性允许多个更小、更专注的团队能够更频繁地提供新功能,并且能够更快地响应业务机会。响应式微服务(Reactive Microservices)应该是独立的、自主的,并且有一个单一的责任,正如 Jonas Bonér 在「Reactive Microsystems: The Evolution of Microservices at Scale」一书中所指出的那样。
在微服务架构中,你应该考虑服务内部和服务之间的通信。
一般来说,我们建议不要在不同的服务之间使用 Akka 集群和 Actor 消息传递,因为这会导致服务之间的代码耦合过紧,并且难以独立地部署这些服务,这是使用微服务架构的主要原因之一。有关这方面的一些背景,请参见「Lagom Framework」中关于「Internal and External Communication」的讨论,其中每个微服务都是一个 Akka 集群。
单个服务的节点需要较少的去耦。它们共享相同的代码,由单个团队或个人作为一个集合部署在一起。在滚动部署(rolling deployment)期间,可能有两个版本同时运行,但整个集合的部署只有一个控制点。因此,业务内通信可以利用 Akka 集群的故障管理和 Actor 消息传递使用方便和性能优异的优点。
在不同的服务之间,「Akka HTTP」或「Akka gRPC」可用于同步(但不阻塞)通信,而「Akka Streams Kafka」或其他「Alpakka」连接器可用于集成异步通信。所有这些通信机制都可以很好地与端到端的反向压力(end-to-end back-pressure)的消息流配合使用,同步通信工具也可以用于单个请求-响应(request response)交互。同样重要的是要注意,当使用这些工具时,通信的双方不必使用 Akka 实现,编程语言也不重要。
传统的分布式应用
我们承认微服务也带来了许多新的挑战,它不是构建应用程序的唯一方法。传统的分布式应用程序可能不那么复杂,在许多情况下也工作得很好。例如,对于一个小的初创企业,只有一个团队,在那里构建一个应用程序,上市时间就是一切。Akka 集群可以有效地用于构建这种分布式应用程序。
在这种情况下,你只有一个部署单元,从单个代码库构建(或使用传统的二进制依赖性管理模块化),但使用单个集群跨多个节点部署。更紧密的耦合是可以的,因为有一个部署和控制的中心点。在某些情况下,节点可能具有专门的运行时角色,这意味着集群不是完全相同的(例如,“前端”和“后端”节点,或专用的master/worker节点),但如果这些节点是从相同的构建构件运行的,则这只是一种运行时行为,不会造成与紧耦合中可能出现的问题相同的问题。
紧耦合的分布式应用程序多年来为行业和许多 Akka 用户提供了良好的服务,仍然是一个有效的选择。
分布式整体
还有一种反模式(anti-pattern),有时被称为“分布式整体(distributed monolith)”。你有多个彼此独立地构建和部署的服务,但是它们之间的紧密耦合使得这非常危险,例如共享集群、共享代码和服务 API 调用的依赖项,或者共享数据库模式。由于代码和部署单元的物理分离,有一种错误的自主权感,但是由于一个服务的实现中的更改泄漏到其他服务的行为中,你很可能会遇到问题。参见 Ben Christensen 的「Don’t Build a Distributed Monolith」。
在这种情况下,发现自己处于这种状态的组织通常会通过集中协调多个服务的部署来作出反应,此时,在承担成本的同时,你已经失去了微服务的主要好处。你正处于一个中间状态,以一种单独的方式构建和部署那些并不真正可分离的东西。有些人这样做,有些人设法使它工作,但这不是我们推荐的,它需要小心管理。
一个简单的集群示例
以下配置允许使用Cluster扩展。它加入集群,Actor 订阅集群成员事件并记录它们。
application.conf配置如下:
akka {
actor {
provider = "cluster"
}
remote {
log-remote-lifecycle-events = off
netty.tcp {
hostname = "127.0.0.1"
port = 0
}
}
cluster {
seed-nodes = [
"akka.tcp://[email protected]:2551",
"akka.tcp://[email protected]:2552"]
# auto downing is NOT safe for production deployments.
# you may want to use it during development, read more about it in the docs.
#
# auto-down-unreachable-after = 10s
}
}
# Enable metrics extension in akka-cluster-metrics.
akka.extensions=["akka.cluster.metrics.ClusterMetricsExtension"]
# Sigar native library extract location during tests.
# Note: use per-jvm-instance folder when running multiple jvm on one host.
akka.cluster.metrics.native-library-extract-folder=${user.dir}/target/native
要在 Akka 项目中启用集群功能,你至少应该添加「Remoting」设置,但使用集群。akka.cluster.seed-nodes通常也应该添加到application.conf文件中。
- 注释:如果你在 Docker 容器中运行 Akka,或者由于其他原因,节点具有单独的内部和外部 IP 地址,则必须根据 NAT 或 Docker 容器中的 Akka 配置远程处理。
种子节点是为集群的初始、自动、连接配置的接触点。
请注意,如果要在不同的计算机上启动节点,则需要在application.conf中指定计算机的 IP 地址或主机名,而不是127.0.0.1。
使用集群扩展的 Actor 可能如下所示:
/*
* Copyright (C) 2018 Lightbend Inc.
*/
package jdocs.cluster;
import akka.actor.AbstractActor;
import akka.cluster.Cluster;
import akka.cluster.ClusterEvent;
import akka.cluster.ClusterEvent.MemberEvent;
import akka.cluster.ClusterEvent.MemberUp;
import akka.cluster.ClusterEvent.MemberRemoved;
import akka.cluster.ClusterEvent.UnreachableMember;
import akka.event.Logging;
import akka.event.LoggingAdapter;
public class SimpleClusterListener extends AbstractActor {
LoggingAdapter log = Logging.getLogger(getContext().getSystem(), this);
Cluster cluster = Cluster.get(getContext().getSystem());
//subscribe to cluster changes
@Override
public void preStart() {
cluster.subscribe(getSelf(), ClusterEvent.initialStateAsEvents(),
MemberEvent.class, UnreachableMember.class);
}
//re-subscribe when restart
@Override
public void postStop() {
cluster.unsubscribe(getSelf());
}
@Override
public Receive createReceive() {
return receiveBuilder()
.match(MemberUp.class, mUp -> {
log.info("Member is Up: {}", mUp.member());
})
.match(UnreachableMember.class, mUnreachable -> {
log.info("Member detected as unreachable: {}", mUnreachable.member());
})
.match(MemberRemoved.class, mRemoved -> {
log.info("Member is Removed: {}", mRemoved.member());
})
.match(MemberEvent.class, message -> {
// ignore
})
.build();
}
}
Actor 将自己注册为某些集群事件的订阅者。它在订阅开始时接收与集群当前状态对应的事件,然后接收集群中发生更改的事件。
你自己运行这个例子最简单的方法是下载准备好的「Akka Cluster Sample with Java」和教程。它包含有关如何运行SimpleClusterApp的说明。此示例的源代码可以在「Akka Samples Repository」中找到。
联接到种子节点
- 注释:当在云系统上启动集群时,如 Kubernetes、AWS、Google Cloud,、Azure、Mesos 或其他维护 DNS 或其他发现节点的方式,你可能希望使用开源「Akka Cluster Bootstrap」模块实现的自动加入过程。
联接已配置的种子节点
你可以决定是手动加入集群,还是自动加入到配置的初始接触点,即所谓的种子节点。在连接过程之后,种子节点并不特殊,它们以与其他节点完全相同的方式参与集群。
当一个新节点启动时,它会向所有种子节点发送一条消息,然后向首先应答的节点发送join命令。如果没有任何种子节点响应(可能尚未启动),则会重试此过程,直到成功或关闭。
你在application.conf配置文件中定义种子节点:
akka.cluster.seed-nodes = [
"akka.tcp://ClusterSystem@host1:2552",
"akka.tcp://ClusterSystem@host2:2552"]
当 JVM 启动时,也可以将其定义 Java 系统属性:
-Dakka.cluster.seed-nodes.0=akka.tcp://ClusterSystem@host1:2552
-Dakka.cluster.seed-nodes.1=akka.tcp://ClusterSystem@host2:2552
种子节点可以任意顺序启动,不需要运行所有的种子节点,但是在初始启动集群时必须启动配置列表seed-nodes中第一个元素的节点,否则其他种子节点将不会初始化,其他节点也不能加入集群。第一个种子节点之所以特殊,其原因是避免从空集群开始时形成分离的岛(islands)。同时启动所有配置的种子节点是最快的(顺序无关紧要),否则它可以占用配置的seed-node-timeout,直到节点可以加入。
一旦启动了两个以上的种子节点,就可以关闭第一个种子节点。如果第一个种子节点重新启动,它将首先尝试加入现有集群中的其他种子节点。请注意,如果同时停止所有种子节点,并使用相同的seed-nodes配置重新启动它们,它们将自己加入并形成新的集群,而不是加入现有集群的其余节点。这可能是不需要的,应该通过将几个节点列为种子节点来避免冗余,并且不要同时停止所有节点。
使用 Cluster Bootstrap 自动联接种子节点
与手动配置种子节点(这在开发或静态分配的节点 IP 中很有用)不同,你可能希望使用云提供者(cloud providers)或集群协调者(cluster orchestrator)或其他某种形式的服务发现(如托管 DNS)来自动发现种子节点。开源的 Akka 管理库包括「Cluster Bootstrap」模块,它就专注于处理这个问题。有关更多详细信息,请参阅其文档。
使用 joinSeedNodes 编程联接到种子节点
你还可以使用Cluster.get(system).joinSeedNodes以编程方式连接种子节点,这在启动时使用一些外部工具或 API 动态发现其他节点时很有吸引力。当使用joinSeedNodes时,除了应该是第一个种子节点的节点之外,不应该包括节点本身,并且应该将其放在joinSeedNodes的参数中的第一个节点中。
import akka.actor.Address;
import akka.cluster.Cluster;
final Cluster cluster = Cluster.get(system);
List<Address> list = new LinkedList<>(); //replace this with your method to dynamically get seed nodes
cluster.joinSeedNodes(list);
在配置属性seed-node-timeout中定义的时间段之后,将自动重试联系种子节点失败的尝试。在尝试联接失败之后,经过retry-unsuccessful-join-after配置的时间,将自动重试加入特定种子节点失败的尝试。重试意味着它尝试联系所有种子节点,然后连接首先应答的节点。如果种子节点列表中的第一个节点在配置的seed-node-timeout时间内无法联系任何其他种子节点,那么它将连接自身。
默认情况下,给定种子节点的联接将无限期重试,直到成功联接为止。如果配置超时失败,则可以中止该进程。当中止时,它将运行「Coordinated Shutdown」,默认情况下将终止ActorSystem。也可以将 Coordinated Shutdown 配置为退出 JVM。如果seed-nodes是动态组装的,并且在尝试失败后使用新seed-nodes重新启动,则定义此超时非常有用。
akka.cluster.shutdown-after-unsuccessful-join-seed-nodes = 20s
akka.coordinated-shutdown.terminate-actor-system = on
如果不配置种子节点或使用joinSeedNodes,则需要手动加入集群,可以使用「JMX」或「HTTP」执行。
你可以加入集群中的任何节点。它不必配置为种子节点。请注意,你只能联接到现有的集群成员,这意味着对于bootstrapping,某些节点必须联接到自己,然后以下节点可以联接它们以组成集群。
Actor 系统只能加入一次集群。其他尝试将被忽略。当它成功加入时,必须重新启动才能加入另一个集群或再次加入同一个集群。重新启动后可以使用相同的主机名和端口,当它成为集群中现有成员的新化身(incarnation),尝试加入时,将从集群中删除现有成员,然后允许它加入。
- 注释:对于集群中的所有成员,
ActorSystem的名称必须相同。当你启动ActorSystem时,将给出ActorSystem的名称。
Downing
当故障检测器(failure detector)认为某个成员unreachable时,不允许leader履行其职责,例如将新加入成员的状态更改为Up。节点必须首先再次reachable,或者unreachable的成员的状态必须更改为Down。将状态更改为Down可以自动或手动执行。默认情况下,必须使用「JMX」或「HTTP」手动完成。
它也可以用Cluster.get(system).down(address)以编程方式执行。
如果一个节点仍在运行,并且将其自身视为Down,那么它将关闭。如果在运行时将run-coordinated-shutdown-when-down设置为on(默认值),则 Coordinated Shutdown 将自动运行,但是节点不会尝试优雅地离开集群,因此不会发生分片和单例迁移。
「Split Brain Resolver」是「Lightbend Reactive Platform」的一部分,它提供了一种针对downing问题的预打包(pre-packaged)解决方案。如果你不使用 RP,你无论如何都应该仔细阅读 Split Brain Resolver 的文档,并确保你使用的解决方案能够处理此处描述的问题。
Auto-downing (DO NOT USE)
有一个自动downing的功能,但你不应该在生产中使用。出于测试目的,你可以通过配置启用它:
akka.cluster.auto-down-unreachable-after = 120s
这意味着在配置时间内没联接成功的话,集群的leader将自动改变unreachable节点的状态为down。
这是一种从集群成员中删除unreachable节点的天真方法。它在开发过程中是有用的,但在生产环境中,它最终会破坏集群。当发生网络分裂时,分裂的两侧将看到另一侧unreachable,并将其从集群中移除。这导致了两个分开的、断开的簇的形成,称为 Split Brain。
此行为不限于网络分裂(network partitions)。如果集群中的节点过载,或者经历长 GC 暂停,也可能发生这种情况。
- 警告:
- 我们建议不要在生产中使用 Akka 集群的
auto-down功能。它对生产系统有多种不良后果。 - 如果你使用的是 Cluster Singleton 或 Cluster Sharding,那么它可能会破坏这些特性提供的契约。两者都保证了一个 Actor 在集群中是唯一的。启用
auto-down功能后,可能形成多个独立集群。当这种情况发生时,保证的唯一性将不再是真的,从而导致系统中的不良行为。 - 当 Akka Persistence 与 Cluster Sharding 结合使用时,这种情况更为严重。在这种情况下,缺少唯一性的 Actor 会导致多个 Actor 写入同一个日志。Akka Persistence 的工作是单一写入原则(
single writer principle)。拥有多个写入者会损坏日志并使其无法使用。 - 最后,即使你不使用 Persistence、Sharding 或 Singletons 等特性,
auto-downing也会导致系统形成多个小集群。这些小集群将彼此独立。它们将无法通信,因此你可能会遇到性能下降。一旦出现这种情况,就需要人工干预来修正集群。 - 由于这些问题,
auto-downing不应该在生产环境中使用。
- 我们建议不要在生产中使用 Akka 集群的
Leaving
从集群中删除成员有两种方法。
你可以停止 Actor 系统(或 JVM 进程)。它将被检测为unreachable,并在自动或手动downing后移除,如上文所述。
如果你告诉集群一个节点应该离开,那么可以执行更优雅的退出。这可以使用「JMX」或「HTTP」执行。也可以通过以下方式以编程方式执行:
final Cluster cluster = Cluster.get(system);
cluster.leave(cluster.selfAddress());
注意,这个命令可以发送给集群中的任何成员,不一定是要离开的成员。
当集群节点将自己视为Exiting时,Coordinated Shutdown 将自动运行,即从另一个节点退出将触发leaving节点上的关闭过程。当使用 Akka 集群时,会自动添加集群的优雅离开任务,包括 Cluster Singletons 的优雅关闭和 Cluster Sharding,即运行关闭过程也会触发尚未进行的优雅离开。
通常情况下,这是自动处理的,但在此过程中,如果出现网络故障,可能仍然需要将节点的状态设置为Down,以便完成删除。
WeaklyUp 成员
如果一个节点是unreachable的,那么消息聚合是不可能的,因此leader的任何行为也是不可能的。但是,在这个场景中,我们仍然可能希望新节点加入集群。
如果不能达到聚合,加入成员将被提升为WeaklyUp,并成为集群的一部分。一旦达到消息聚合,leader就会把WeaklyUp的成员调为Up。
默认情况下启用此功能,但可以使用配置选项禁用此功能:
akka.cluster.allow-weakly-up-members = off
你可以订阅WeaklyUp的成员事件,以使用处于此状态的成员,但你应该注意,网络分裂另一端的成员不知道新成员的存在。例如,在quorum decisions时,你不应该把WeaklyUp的成员计算在内。
订阅集群事件
可以使用Cluster.get(system).subscribe订阅集群成员的更改通知。
cluster.subscribe(getSelf(), MemberEvent.class, UnreachableMember.class);
完整状态的快照akka.cluster.ClusterEvent.CurrentClusterState将作为第一条消息发送给订阅者,随后是在有更新事件时,再发送消息。
请注意,如果在完成初始联接过程之前启动订阅,则可能会收到一个空的CurrentClusterState,其中不包含成员,后面是已联接的其他节点的MemberUp事件。例如,当你在cluster.join()之后立即启动订阅时,可能会发生这种情况,如下所示。这是预期行为。当节点在集群中被接受后,你将收到该节点和其他节点的MemberUp。
Cluster cluster = Cluster.get(getContext().getSystem());
cluster.join(cluster.selfAddress());
cluster.subscribe(getSelf(), MemberEvent.class, UnreachableMember.class);
为了避免在开始时接收空的CurrentClusterState,你可以像下例所示这样使用它,将订阅推迟到接收到自己节点的MemberUp事件为止:
Cluster cluster = Cluster.get(getContext().getSystem());
cluster.join(cluster.selfAddress());
cluster.registerOnMemberUp(
() -> cluster.subscribe(getSelf(), MemberEvent.class, UnreachableMember.class)
);
如果你发现处理CurrentClusterState不方便,可以使用ClusterEvent.initialStateAsEvents()作为参数进行订阅。这意味着,你将收到与当前状态相对应的事件,以模拟在过去发生事件时,如果正在监听这些事件,你将看到的情况,而不是作为第一条消息接收CurrentClusterState。请注意,这些初始事件只对应于当前状态,而不是集群中实际发生的所有更改的完整历史记录。
cluster.subscribe(getSelf(), ClusterEvent.initialStateAsEvents(),
MemberEvent.class, UnreachableMember.class);
跟踪成员生命周期的事件有:
ClusterEvent.MemberJoined,新成员已加入集群,其状态已更改为Joining。ClusterEvent.MemberUp,新成员已加入集群,其状态已更改为Up。ClusterEvent.MemberExited,某个成员正在离开集群,其状态已更改为Exiting。请注意,在另一个节点上发布此事件时,该节点可能已关闭。ClusterEvent.MemberRemoved,成员已从集群中完全删除。ClusterEvent.UnreachableMember,一个成员被认为是unreachable,由至少一个其他节点的故障检测器检测到。ClusterEvent.ReachableMember,在unreachable之后,成员被认为是reachable的。以前检测到它不可访问的所有节点都再次检测到它是可访问的。
有更多类型的变更事件,请参阅扩展akka.cluster.ClusterEvent.ClusterDomainEvent类的 API 文档,以了解有关事件的详细信息。
有时,不订阅集群事件,只使用Cluster.get(system).state()获取完整成员状态是很方便的。请注意,此状态不一定与发布到集群订阅的事件同步。
Worker Dial-in Example
让我们来看一个示例,该示例演示了名为backend的工作者如何检测并注册到名为frontend的新主节点。
示例应用程序提供了一个转换文本的服务。当一些文本发送到其中一个frontend服务时,它将被委托给一个backend,后者执行转换作业,并将结果发送回原始客户机。新的backend节点以及新的frontend节点可以在集群中动态地添加或删除。
消息:
public interface TransformationMessages {
public static class TransformationJob implements Serializable {
private final String text;
public TransformationJob(String text) {
this.text = text;
}
public String getText() {
return text;
}
}
public static class TransformationResult implements Serializable {
private final String text;
public TransformationResult(String text) {
this.text = text;
}
public String getText() {
return text;
}
@Override
public String toString() {
return "TransformationResult(" + text + ")";
}
}
public static class JobFailed implements Serializable {
private final String reason;
private final TransformationJob job;
public JobFailed(String reason, TransformationJob job) {
this.reason = reason;
this.job = job;
}
public String getReason() {
return reason;
}
public TransformationJob getJob() {
return job;
}
@Override
public String toString() {
return "JobFailed(" + reason + ")";
}
}
public static final String BACKEND_REGISTRATION = "BackendRegistration";
}
backend执行文件转换工作:
public class TransformationBackend extends AbstractActor {
Cluster cluster = Cluster.get(getContext().getSystem());
//subscribe to cluster changes, MemberUp
@Override
public void preStart() {
cluster.subscribe(getSelf(), MemberUp.class);
}
//re-subscribe when restart
@Override
public void postStop() {
cluster.unsubscribe(getSelf());
}
@Override
public Receive createReceive() {
return receiveBuilder()
.match(TransformationJob.class, job -> {
getSender().tell(new TransformationResult(job.getText().toUpperCase()),
getSelf());
})
.match(CurrentClusterState.class, state -> {
for (Member member : state.getMembers()) {
if (member.status().equals(MemberStatus.up())) {
register(member);
}
}
})
.match(MemberUp.class, mUp -> {
register(mUp.member());
})
.build();
}
void register(Member member) {
if (member.hasRole("frontend"))
getContext().actorSelection(member.address() + "/user/frontend").tell(
BACKEND_REGISTRATION, getSelf());
}
}
请注意,TransformationBackend Actor 订阅集群事件以检测新的、潜在的frontend节点,并向它们发送注册消息,以便它们知道可以使用backend工作者。
接收用户作业并委托给已注册的backend的frontend节点:
public class TransformationFrontend extends AbstractActor {
List<ActorRef> backends = new ArrayList<ActorRef>();
int jobCounter = 0;
@Override
public Receive createReceive() {
return receiveBuilder()
.match(TransformationJob.class, job -> backends.isEmpty(), job -> {
getSender().tell(
new JobFailed("Service unavailable, try again later", job),
getSender());
})
.match(TransformationJob.class, job -> {
jobCounter++;
backends.get(jobCounter % backends.size())
.forward(job, getContext());
})
.matchEquals(BACKEND_REGISTRATION, x -> {
getContext().watch(getSender());
backends.add(getSender());
})
.match(Terminated.class, terminated -> {
backends.remove(terminated.getActor());
})
.build();
}
}
请注意,TransformationFrontend Actor 监视已注册的backend,以便能够将其从可用backend列表中删除。Death Watch 对集群中的节点使用集群故障检测器,例如检测网络故障和 JVM 崩溃,并优雅地终止被监视的 Actor。当unreachable的集群节点被关闭和删除时,Death Watch 将向监视 Actor 生成Terminated消息。
在示例中运行Worker Dial-in Example最简单的方法是下载准备好的「Akka Cluster Sample with Java」和教程。它包含有关如何运行Worker Dial-in Example示例的说明。此示例的源代码可以在「Akka Samples Repository」中找到。
节点角色
并非集群的所有节点都需要执行相同的功能:可能有一个子集运行 Web 前端,一个子集运行数据访问层,一个子集用于数字处理。例如,通过集群感知路由器(cluster-aware routers)部署 Actor,可以考虑节点角色(node roles)以实现这种职责分配。
节点的角色在名为akka.cluster.roles的配置属性中定义,通常在启动脚本中将其定义为系统属性或环境变量。
节点的角色是可以订阅的MemberEvent中成员信息的一部分。
如何在达到群集大小时启动
一个常见的用例是在集群已经初始化、成员已经加入并且集群已经达到一定的大小之后启动 Actor。
通过配置选项,你可以在leader将Joining成员的状态更改为Up之前定义所需的成员数:
akka.cluster.min-nr-of-members = 3
以类似的方式,你可以在leader将Joining成员的状态更改为Up之前,定义特定角色所需的成员数:
akka.cluster.role {
frontend.min-nr-of-members = 1
backend.min-nr-of-members = 2
}
可以在registerOnMemberUp回调中启动 Actor,当当前成员状态更改为Up时,将调用该回调,例如集群至少具有已定义的成员数。
Cluster.get(system).registerOnMemberUp(new Runnable() {
@Override
public void run() {
system.actorOf(Props.create(FactorialFrontend.class, upToN, true),
"factorialFrontend");
}
});
这个回调可以用于启动 Actor 以外的其他事情。
如何清理 Removed 状态的成员
你可以在registerOnMemberRemoved回调中进行一些清理,当当前成员状态更改为Removed或群集已关闭时,将调用该回调。
另一种方法是将任务注册到 Coordinated Shutdown 中。
- 注释:在已关闭的群集上注册
OnMemberRemoved回调,该回调将立即在调用方线程上调用,否则稍后当当前成员状态更改为Removed时将调用该回调。你可能希望在群集启动后安装一些清理处理,但在安装时群集可能已经关闭,这取决于竞争是否正常。
更高级别的群集工具
Cluster Singleton
对于某些用例,确保集群中某个类型的某个 Actor 恰好运行在某个位置是方便的,有时也是强制的。
这可以通过订阅成员事件来实现,但有几个情况需要考虑。因此,这个特定的用例由「Cluster Singleton」覆盖。
Cluster Sharding
将 Actor 分布在集群中的多个节点上,并支持使用其逻辑标识符与 Actor 进行交互,但不必关心它们在集群中的物理位置。
详见「Cluster Sharding」。
Distributed Publish Subscribe
在集群中的 Actor 之间发布订阅消息,并使用 Actor 的逻辑路径发布点对点(point-to-point)消息,即发送方不必知道目标 Actor 正在哪个节点上运行。
详见「Distributed Publish Subscribe」。
Cluster Client
从不是集群一部分的 Actor 系统到集群中某个地方运行的 Actor 的通信。客户端不必知道目标 Actor 正在哪个节点上运行。
详见「Cluster Client」。
Distributed Data
当需要在 Akka 集群中的节点之间共享数据时,Akka 分布式数据(Distributed Data)非常有用。通过提供类似 API 的键值(key-value)存储的 Actor 访问数据。
详见「Distributed Data」。
Cluster Aware Routers
所有路由(routers)都可以知道集群中的成员节点,即部署新的routees或在集群中的节点上查找routees。当一个节点无法访问或离开集群时,该节点的routees将自动从「路由」中注销。当新节点加入集群时,会根据配置向路由添加额外的routees。
详见「Cluster Aware Routers」。
Cluster Metrics
集群的成员节点可以收集系统健康度量(health metrics),并将其发布到其他集群节点和系统事件总线(system event bus)上注册的订阅者。
详见「Cluster Metrics」。
故障检测器
在集群中,每个节点都由几个(默认最多 5 个)其他节点监控,当其中任何一个节点检测到unreachable该节点时,信息将通过gossip传播到集群的其余部分。换句话说,只要有一个节点将一个节点标记为unreachable,则集群的其余部分也将该节点标记为unreachable。
故障检测器(failure detector)还将检测节点是否可以再次reachable。当监视unreachable节点的所有节点再次检测到它是reachable时,在消息传播之后,集群将认为它是reachable的。
如果系统消息无法传递到节点,那么它将被隔离,然后它将无法从unreachable的状态返回。如果有太多未确认的系统消息(例如监视、终止、远程 Actor 部署、远程父级监控的 Actor 失败),则可能发生这种情况。然后需要将节点移动到down或removed状态,并且必须重新启动隔离节点的 Actor 系统,然后才能再次加入集群。
集群中的节点通过发送心跳来相互监控,以检测是否可以从集群的其余部分访问节点。心跳到达时间由「The Phi Accrual Failure Detector」的实现来解释。
故障的等级由一个称为phi的值给出。phi故障检测器的基本思想是用动态调整的尺度来表示phi的值,以反映当前的网络状况。
phi值计算如下:
phi = -log10(1 - F(timeSinceLastHeartbeat))
式中,F是正态分布的累积分布函数,平均值和标准偏差根据历史心跳到达时间估计。
在配置中,你可以调整akka.cluster.failure-detector.threshold来定义什么时候将phi值视为故障。
低阈值容易产生许多误报,但可以确保在发生真正的崩溃时快速检测。相反,高阈值产生的错误更少,但需要更多的时间来检测实际的崩溃。默认阈值为8,适用于大多数情况。然而,在云环境中,例如 Amazon EC2,为了解决此类平台上有时出现的网络问题,其值可以增加到12。
下图说明了自上一次心跳以来,phi是如何随着时间的增加而增加的:
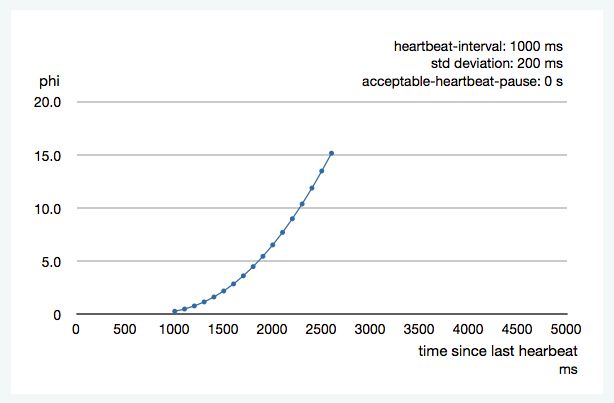
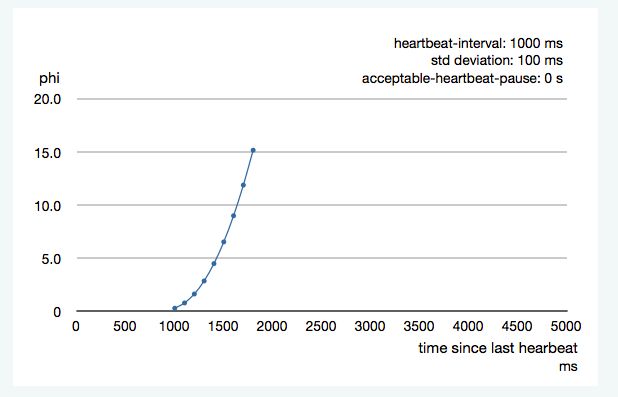
根据历史到达时间的平均值和标准偏差计算phi。前面的图表是200ms标准偏差的一个例子。如果心跳到达时的偏差较小,曲线会变陡,即可以更快地确定故障。对于100ms的标准偏差,曲线看起来是这样的:
为了能够承受突发的异常情况,例如垃圾收集暂停和短暂的网络故障,故障检测器可以通过akka.cluster.failure-detector.acceptable-heartbeat-pause配置一个边界值。你可能需要根据你的环境调整此配置。这就是配置acceptable-heartbeat-pause为3s的可接受心跳暂停的曲线:

Death Watch 对集群中的节点使用集群故障检测器,即它检测网络故障和 JVM 崩溃,并优雅地终止被监视的 Actor。当无法访问的群集节点被关闭和删除时,Death Watch 将向监视 Actor 生成Terminated消息。
如果在系统加载时遇到可疑的误报,你应该为集群 Actor 定义一个单独的调度程序,如「Cluster Dispatcher」中所述的。
如何测试?
目前,使用sbt multi-jvm插件进行的测试只记录在 Scala 中。有关详细信息,请转到此页对应的 Scala 版本查看。
管理
HTTP
HTTP API 提供了集群的信息和管理。详见「Akka Management」。
JMX
集群的信息和管理以根名称akka.Cluster的 JMX MBeans 提供。JMX 信息可以用普通的 JMX 控制台,如 JConsole 或 JVisualVM 显示。
在 JMX 中,你可以:
- 查看属于集群的哪些成员
- 查看此节点的状态
- 查看每个成员的角色
- 将此节点连接到群集中的另一个节点
- 将群集中的任何节点标记为
down - 告诉群集中的任何节点离开
成员节点由格式为akka.://@:的地址标识。
命令行
- 警告:
Deprecation warning,命令行脚本已被否决,并计划在下一个主要版本中删除。使用带有curl或类似代码的 HTTP 管理 API。
可以使用「Akka GitHub」中提供的脚本akka-cluster管理集群。将脚本和jmxsh-R5.jar放在同一个目录中。
不带参数运行它,可以查看有关如何使用脚本的说明:
Usage: ./akka-cluster ...
Supported commands are:
join - Sends request a JOIN node with the specified URL
leave - Sends a request for node with URL to LEAVE the cluster
down - Sends a request for marking node with URL as DOWN
member-status - Asks the member node for its current status
members - Asks the cluster for addresses of current members
unreachable - Asks the cluster for addresses of unreachable members
cluster-status - Asks the cluster for its current status (member ring,
unavailable nodes, meta data etc.)
leader - Asks the cluster who the current leader is
is-singleton - Checks if the cluster is a singleton cluster (single
node cluster)
is-available - Checks if the member node is available
Where the should be on the format of
'akka.://@:'
Examples: ./akka-cluster localhost 9999 is-available
./akka-cluster localhost 9999 join akka.tcp://MySystem@darkstar:2552
./akka-cluster localhost 9999 cluster-status
配置
集群有几个配置属性。有关更多信息,请见「参考配置」。
Cluster Info Logging
你可以使用以下配置属性在info级别停止群集事件的日志记录:
akka.cluster.log-info = off
你可以在info级别启用群集事件的详细日志记录,例如用于临时故障排除,配置属性为:
akka.cluster.log-info-verbose = on
Cluster Dispatcher
集群扩展是由 Actor 实现的,可能需要为这些 Actor 创建一个隔离墙,以避免来自其他 Actor 的干扰。尤其是那些用于故障检测的心跳 Actor,如果不给他们定期运行的机会,他们可能会产生误报。为此,你可以定义一个单独的调度程序(dispatcher),用于集群 Actor:
akka.cluster.use-dispatcher = cluster-dispatcher
cluster-dispatcher {
type = "Dispatcher"
executor = "fork-join-executor"
fork-join-executor {
parallelism-min = 2
parallelism-max = 4
}
}
- 注释:通常不需要为集群配置单独的调度程序。默认调度程序应该足以执行集群任务,即不应更改
akka.cluster.use-dispatcher。如果在使用默认调度器时出现与集群相关的问题,这通常表示你正在默认调度器上运行阻塞或 CPU 密集型参与者/任务(actors/tasks)。为这些参与者/任务使用专用的调度器,而不是在默认调度器上运行它们,因为这样可能会使系统内部任务匮乏。相关配置属性:akka.cluster.use-dispatcher = akka.cluster.cluster-dispatcher。对应的默认值:akka.cluster.use-dispatcher =。
配置兼容性检查
创建集群是指部署两个或多个节点,然后使它们的行为像一个应用程序一样。因此,配置集群中所有节点的兼容设置非常重要。
配置兼容性检查(Configuration Compatibility Check)功能确保集群中的所有节点都具有兼容的配置。每当一个新节点加入一个现有的集群时,它的配置设置的一个子集(只有那些需要检查的)被发送到集群中的节点以进行验证。一旦在集群端检查了配置,集群就会发送回自己的一组必需的配置设置。然后,加入节点将验证它是否符合集群配置。只有在两侧的所有检查都通过时,新加入的节点才会继续。
通过扩展akka.cluster.JoinConfigCompatChecker并将其包含在配置中,可以添加新的自定义检查程序。每个检查器必须与唯一键关联:
akka.cluster.configuration-compatibility-check.checkers {
my-custom-config = "com.company.MyCustomJoinConfigCompatChecker"
}
- 注释:
- 配置兼容性检查默认启用,但可以通过设置
akka.cluster.configuration-compatibility-check.enforce-on-join = off来禁用。这在执行滚动更新时特别有用。显然,只有当完全关闭集群不是一个选项时,才应该这样做。具有不同配置设置的节点的集群可能会导致数据丢失或数据损坏。 - 仅应在联接节点上禁用此设置。始终在两侧执行检查,并记录警告。在不兼容的情况下,连接节点负责决定是否中断进程。
- 如果使用 Akka 2.5.9 或更高版本对集群执行滚动更新(不支持此功能),则不会执行检查,因为正在运行的集群无法验证加入节点发送的配置,也无法发送回自己的配置。
- 配置兼容性检查默认启用,但可以通过设置
英文原文链接:Cluster Usage.
———— ☆☆☆ —— 返回 -> Akka 中文指南 <- 目录 —— ☆☆☆ ————