Python构建SVM分类器(线性)
1.SVM建立线性分类器
SVM用来构建分类器和回归器的监督学习模型,SVM通过对数学方程组的求解,可以找出两组数据之间的最佳分割边界。
2.准备工作
我们首先对数据进行可视化,使用的文件来自学习书籍配套管网。
首先增加以下代码:
import numpy as np
import matplotlib.pyplot as plt
import utilities
# Load input data
input_file = 'data_multivar.txt'
X, y = utilities.load_data(input_file)刚刚导入了需要的程序包,确定了文件的名称,接下来看load_data()方法:
#加载输入文件中的多变量数据
def load_data(input_file):
X = []
y = []
with open(input_file, 'r') as f:
for line in f.readlines():
data = [float(x) for x in line.split(',')]
X.append(data[:-1])
y.append(data[-1])
X = np.array(X)
y = np.array(y)
return X, y
需要将数据分成类,如下所示:
class_0 = np.array([X[i] for i in range(len(X)) if y[i]==0])
class_1 = np.array([X[i] for i in range(len(X)) if y[i]==1])数据分类后,我们将它们画出来:
plt.figure()
plt.scatter(class_0[:,0], class_0[:,1], facecolors='black', edgecolors='black', marker='s')
plt.scatter(class_1[:,0], class_1[:,1], facecolors='None', edgecolors='black', marker='s')
plt.title('Input data')
plt.show()
可以发现数据有两个类型组成,我们的目标是要建立一个可以将实心方块和空心方块分开的模型、
3.实现步骤
(1)将数据集分割为训练数据集和测试数据集,加入以下代码:
from sklearn import cross_validation
from sklearn.svm import SVC
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X, y, test_size=0.25, random_state=5)
(2)用线性核函数初始化一个SVM对象,并训练线性SVM分类器,加入以下函数:
params = {'kernel': 'linear'}
classifier = SVC(**params)
classifier.fit(X_train, y_train)
utilities.plot_classifier(classifier, X_train, y_train, 'Training dataset')可以看到以下的图形
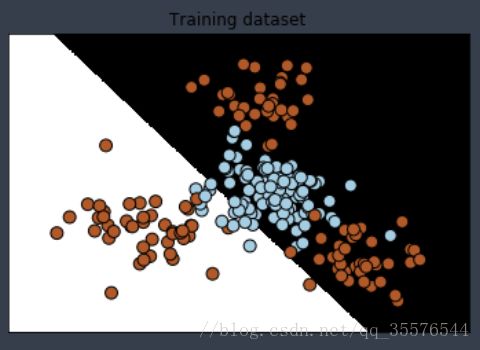
plot_classifier函数为之前构造过的画图函数。
接下来看分类器对测试集的执行,增加以下代码:
y_test_pred = classifier.predict(X_test)
utilities.plot_classifier(classifier, X_test, y_test, 'Test dataset')

接下来计算训练集的准确性:
from sklearn.metrics import classification_report
target_names = ['Class-' + str(int(i)) for i in set(y)]
print("\n" + "#"*30)
print("\nClassifier performance on training dataset\n")
print(classification_report(y_train,classifier.predict(X_train),
target_names = target_names))
print("#"*30+"\n")
最后查看分类器为测试集生成的分类报告:
print("#"*30)
print("\nClassification report on test dataset\n")
print(classification_report(y_test,y_test_pred,
target_names=target_names))
print("#"*30+"\n")
从前面的数据可视化图形中我们可以看到实心方块完全被空心方块保卫,也就是两种数据不是线性可分,无法画出一条分离两种类型数据的直线,需要利用非线性分类器。