机器学习学习笔记之一——用python实现简单一元函数、二元函数的梯度下降
今天开始正正经经,好好的写机器学习的笔记。
再一次从头翻过来学机器学习,在有一些python和大学数学的基础下,首先要搞的果然还是梯度下降,本篇记录的是用jupyter完成的一次作业:python实现一维数组和二维数组的梯度下降,目的只在于熟悉梯度下降。
第一部分:一元函数的数据生成与图像呈现
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
import math
from mpl_toolkits.mplot3d import Axes3D
import warnings
# 解决中文显示问题
mpl.rcParams['font.sans-serif'] = [u'SimHei']
mpl.rcParams['axes.unicode_minus'] = False
%matplotlib inline
"""
原图像:
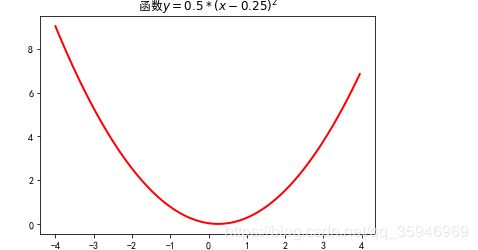
1、构建一个函数为 y = 0.5 * (x-0.25) ** 2 的图像。
2、随机生成X点,根据X点生成Y点。
3、画出图像。
"""
# 一维原始图像
# 原函数
def f1(x):
return 0.5 * (x - 0.25) ** 2
# 构建数据
X = np.arange(-4,4,0.05)
Y = np.array(list(map(lambda t: f1(t),X)))
Y
# 作图
plt.figure(facecolor='w')
plt.plot(X,Y,'r-',linewidth=2)
plt.title(u'函数$y=0.5 * (x - 0.25)^2$')
plt.show()结果如图:
第二部分:一元函数的梯度下降求解过程,以及求解过程图像呈现
"""
对当前一维原始图像求最小点:
1、随机取一个点(横坐标为x),设定阿尔法参数值。
2、对这个点求导数 ,x =x - α*(dY/dx)。
3、重复第二步、设置迭代 y的变化量小于多少时 不再继续迭代。
"""
# 导数
def h1(x):
return 0.5 * 2 * (x-0.25)
x = 4
alpha = 0.5
f_change = f1(x) # y的变化量
iter_num = 0 # 迭代次数
GD_X = [x] #保存梯度下降所经历的点
GD_Y = [f1(x)]
while(f_change > 1e-10) and iter_num<100:
tmp = x - alpha * h1(x)
f_change = np.abs(f1(x) - f1(tmp))
x = tmp
GD_X.append(x)
GD_Y.append(f1(x))
iter_num += 1
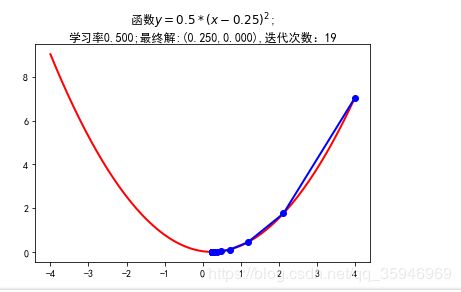
print(u"最终结果为:(%.5f,%.5f)"%(x,f1(x)))
print(u"迭代过程中X的取值,迭代次数:%d" % iter_num)
print(GD_X)
%matplotlib inline
plt.figure(facecolor='w')
plt.plot(X,Y,'r-',linewidth=2) #第三个参数是颜色和形状,red圈就是ro-,red直线就是r-
plt.plot(GD_X, GD_Y, 'bo-', linewidth=2)
plt.title(u'函数$ y = 0.5 * (x-0.25)^2$;\n学习率%.3f;最终解:(%.3f,%.3f),迭代次数:%d'%(alpha,x,f1(x),iter_num))
结果如图:
第三部分:二元函数的数据生成、图像显示
"""
二维原始图像
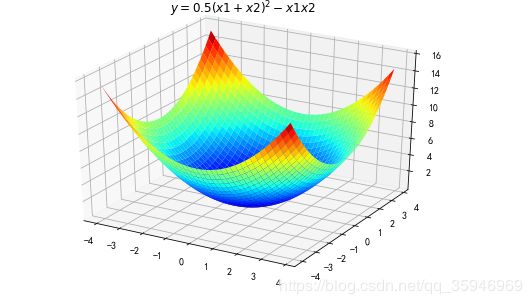
1、构建一个函数为 y = 0.5 (x1+x2)^2 - x1 x2 的图像。
2、随机生成X1,X2点,根据X1,X2点生成Y点。
3、画出图像。
"""
def f2(x1,x2):
return 0.5 * (x1+x2) ** 2 - x1 * x2
X1 = np.arange(-4,4,0.2)
X2 = np.arange(-4,4,0.2)
X1, X2 = np.meshgrid(X1, X2) # 生成xv、yv,将X1、X2变成n*m的矩阵,方便后面绘图
Y = np.array(list(map(lambda t : f2(t[0],t[1]),zip(X1.flatten(),X2.flatten()))))
Y.shape = X1.shape # 1600的Y图还原成原来的(40,40)
%matplotlib inline
#作图
fig = plt.figure(facecolor='w')
ax = Axes3D(fig)
ax.plot_surface(X1,X2,Y,rstride=1,cstride=1,cmap=plt.cm.jet)
ax.set_title(u'$ y = 0.5 (x1+x2)^2 - x1 x2 $')
plt.show()结果如图:
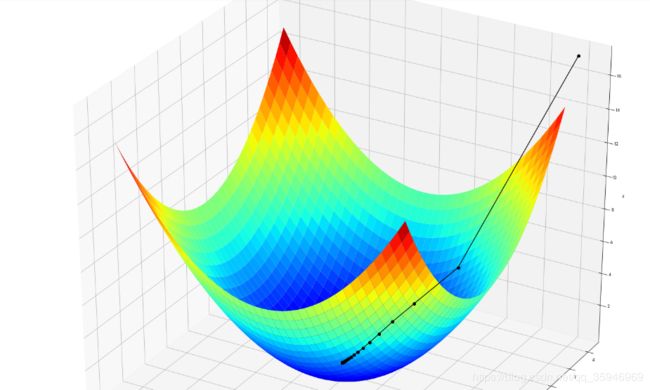
第四部分:二元函数的梯度下降求结果层
"""
对当前二维图像求最小点¶
1、随机取一个点(x1,x2),设定α参数值
2、对这个点分别求关于x1、x2的偏导数,x1 =x1 - α*(dY/dx1),x2 =x2 - α*(dY/dx2)
3、重复第二补,设置 y的变化量 小于多少时 不再重复。
"""
# 二维原始图像
def f2(x, y):
return 0.15 * (x + 0.5) ** 2 + 0.25 * (y - 0.25) ** 2 + 0.35 * (1.5 * x - 0.2 * y + 0.35 ) ** 2
## 偏函数
def hx1(x, y):
return 0.15 * 2 * (x + 0.5) + 0.25 * 2 * (1.5 * x - 0.2 * y + 0.35 ) * 1.5
def hx2(x, y):
return 0.25 * 2 * (y - 0.25) - 0.25 * 2 * (1.5 * x - 0.2 * y + 0.35 ) * 0.2
x1 = 4
x2 = 4
alpha = 0.5
#保存梯度下降经过的点
GD_X1 = [x1]
GD_X2 = [x2]
GD_Y = [f2(x1,x2)]
# 定义y的变化量和迭代次数
y_change = f2(x1,x2)
iter_num = 0
while(y_change > 1e-10 and iter_num < 100) :
tmp_x1 = x1 - alpha * hx1(x1,x2)
tmp_x2 = x2 - alpha * hx2(x1,x2)
tmp_y = f2(tmp_x1,tmp_x2)
f_change = np.absolute(tmp_y - f2(x1,x2))
x1 = tmp_x1
x2 = tmp_x2
GD_X1.append(x1)
GD_X2.append(x2)
GD_Y.append(tmp_y)
iter_num += 1
print(u"最终结果为:(%.5f, %.5f, %.5f)" % (x1, x2, f2(x1,x2)))
print(u"迭代过程中X的取值,迭代次数:%d" % iter_num)
print(GD_X1)
# 作图
fig = plt.figure(facecolor='w',figsize=(20,18))
ax = Axes3D(fig)
ax.plot_surface(X1,X2,Y,rstride=1,cstride=1,cmap=plt.cm.jet)
ax.plot(GD_X1,GD_X2,GD_Y,'ko-')
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_zlabel('z')
ax.set_title(u'函数;\n学习率:%.3f; 最终解:(%.3f, %.3f, %.3f);迭代次数:%d' % (alpha, x1, x2, f2(x1,x2), iter_num))
plt.show()