go爬虫实现,基于beego实现爬取豆瓣 第二篇 进阶篇
go爬虫实现,基于beego实现爬取豆瓣 第一篇 入门篇 传送门

先来了解golang的正则api
regexp 包
函数
func MustCompile(str string) *Regexp //返回一个正则对象
func (re *Regexp) FindAllStringSubmatch(s string, n int) [][]string //匹配文本返回 匹配的内容
常用的正则表达式
. 匹配除换行符以外的任意字符
\w 匹配字母或数字或下划线或汉字
\s 匹配任意空白符
\d 匹配数字
\b 匹配单词的开始和结束
^ 匹配字符的开始
$ 匹配字符的结束
正则表达式的数量约束
* 重复零次或者跟多次
+ 重复一次或者更多次
? 重复一次或者零次
{n} 重复n次
{n,} 重复n次或者更多次
{n,m} 重复n次或m次
正则表达式捕获
(内容) 匹配内容,并自动存入数组返回
看了正则以后 我们来自己写一个正则匹配看看吧
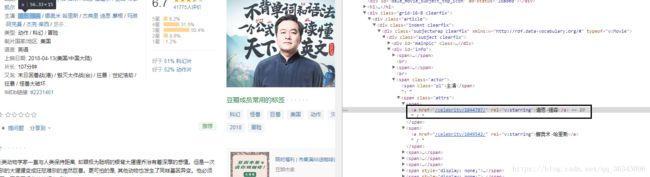
现在来对着 道恩·强森 写一段正则吧
我加了\s* \s匹配任意空白符 * 数量为0或者更多 好下面继续 我们发现 href 的数字是会变的所以我们在这样写
\d* 匹配数字 数量0或者更多
捕获主演的名字
reg:=MustCompile(`
贴一下我捕获其他的信息的代码吧
//匹配导演名称
func GetMovieDirector(moviehtml string) string {
if moviehtml == "" {
return ""
}
reg := regexp.MustCompile(`(.*)`)
result := reg.FindAllStringSubmatch(moviehtml, -1)
if len(result) == 0 {
return ""
}
return string(result[0][1])
}
//匹配电影名
func GetPianNmae(htmls string) string {
if htmls == "" {
return ""
}
//regexp是正则的包,我们先写好正则的规则
reg := regexp.MustCompile(`(.*)`)
//然后进行匹配 -1 表示全部返回 如果写一个1 他就返回匹配到的第一个 返回是一个[][]string
result := reg.FindAllStringSubmatch(htmls, -1)
//如果没有匹配到内容返回空
if len(result) == 0 {
return ""
}
return string(result[0][1])
}
//匹配编剧
func GetBianju(moviehtml string) string {
if moviehtml == "" {
return ""
}
reg := regexp.MustCompile(`(.*?)`)
result := reg.FindAllStringSubmatch(moviehtml, -1)
if len(result) == 0 {
return ""
}
res := ""
for _, v := range result {
if res == "" {
res += v[1]
} else {
res = res + "," + v[1]
}
}
return res
}
//匹配主演
func GetZhuyan(moviehtml string) string {
if moviehtml == "" {
return ""
}
reg := regexp.MustCompile(`(.*?)`)
result := reg.FindAllStringSubmatch(moviehtml, -1)
if len(result) == 0 {
return ""
}
res := ""
for _, v := range result {
if res == "" {
res += v[1]
} else {
res = res + "," + v[1]
}
}
return res
}
//电影类型
func Dianyleix(moviehtml string) string {
if moviehtml == "" {
return ""
}
reg := regexp.MustCompile(`(.*?)`)
result := reg.FindAllStringSubmatch(moviehtml, -1)
if len(result) == 0 {
return ""
}
res := ""
for _, v := range result {
if res == "" {
res += v[1]
} else {
res = res + "," + v[1]
}
}
return res
}
//图片地址
func GetPicsrc(moviehtml string) string {
if moviehtml == "" {
return ""
}
reg := regexp.MustCompile(`制片国家/地区:\s*(.*?)\s*
`)
result := reg.FindAllStringSubmatch(moviehtml, -1)
if len(result) == 0 {
return ""
}
return string(result[0][1])
}
//电影语言
func GetLang(moviehtml string) string {
if moviehtml == "" {
return ""
}
reg := regexp.MustCompile(`语言:\s*(.*?)
`)
result := reg.FindAllStringSubmatch(moviehtml, -1)
if len(result) == 0 {
return ""
}
return string(result[0][1])
}
//电影上映时间
func GetShangtime(moviehtml string) string {
if moviehtml == "" {
return ""
}
reg := regexp.MustCompile(`上映日期:\s*`)
result := reg.FindAllStringSubmatch(moviehtml, -1)
if len(result) == 0 {
return ""
}
return string(result[0][1])
}
//电影时长
func GetTime(moviehtml string) string {
if moviehtml == "" {
return ""
}
reg := regexp.MustCompile(`片长:\s*`)
result := reg.FindAllStringSubmatch(moviehtml, -1)
if len(result) == 0 {
return ""
}
return string(result[0][1])
}
//电影评分
func Getsping(moviehtml string) string {
if moviehtml == "" {
return ""
}
reg := regexp.MustCompile(`(.*?)`)
result := reg.FindAllStringSubmatch(moviehtml, -1)
if len(result) == 0 {
return ""
}
return string(result[0][1])
} 在将爬过来的数据全部存入数据库
在models.go里面连接数据库
//注册数据库
func init() {
//注册mysql驱动
orm.RegisterDriver("mysql", orm.DRMySQL)
//连接数据库
orm.RegisterDataBase("default", "mysql", "root:123@(127.0.0.1:3306)/pachong?charset=utf8")
//生成数据库表表单映射
orm.RegisterModelWithPrefix("movie_", new(Info))
//开启自动建表
orm.RunSyncdb("default", false, false)
//开启ormdebug模式
orm.Debug = true
}
type Info struct {
Id int64 `orm:"pk" from:"id"`
Movie_id int64 //电影id
Movie_name string //电影名称
Movie_pic string //电影图片
Movie_director string //电影导演
Movie_writer string //电影编剧
Movie_country string //电影产地
Movie_language string //电影语言
Movie_main_character string //电影主演
Movie_type string //电影类型
Movie_on_time string //电影上映时间
Movie_span string //电影时长
Movie_grade string //电影评分
Addtime int64
Status int
}
这是我的表 ,随便乱建的就不要吐槽了
然后我们就可以把抓取过来的这些数据写入数据库 返回Getgradbta()方法
package controllers
import (
"pachong/models"
"github.com/astaxie/beego"
"github.com/astaxie/beego/httplib"
)
type GrabdataDisat struct {
beego.Controller
}
func (this *GrabdataDisat) Getgradbta() {
//关闭模板渲染
this.EnableRender = false
//爬虫入口url
urls := "https://movie.douban.com/subject/26430636/?from=showing"
//爬取
resps := httplib.Get(urls)
//得到内容
htmls, err := resps.String()
if err != nil {
panic(err)
}
maps := make(map[string]string)
maps["movie_name"] = models.GetPianNmae(htmls)
maps["movie_director"] = models.GetMovieDirector(htmls)
maps["movie_pic"] = models.GetPicsrc(htmls)
maps["movie_writer"] = models.GetBianju(htmls)
maps["movie_country"] = models.Getage(htmls)
maps["movie_main_character"] = models.GetZhuyan(htmls)
maps["movie_type"] = models.Dianyleix(htmls)
maps["movie_language"] = models.GetLang(htmls)
maps["movie_on_time"] = models.GetShangtime(htmls)
maps["movie_span"] = models.GetTime(htmls)
maps["movie_grade"] = models.Getsping(htmls)
//存入数据库
models.SqlExcute("movie_info", maps, "")
}SqlExcute 是一个网数据库增加数据的方法 我也贴一下把 可以用orm 带的增加方法 可以用我这种方法
// 数据库插入修改
func SqlExcute(table string, data map[string]string, where string) (num int64, err error) {
if table == "" {
err = errors.New("表名不能为空")
num = 0
return
}
if data == nil {
err = errors.New("表名不能为空")
num = 0
return
}
o := orm.NewOrm()
sql := ""
if where == "" {
var field []string
var value []string
for k, v := range data {
field = append(field, "`"+k+"`")
if v != "" {
value = append(value, "'"+v+"'")
} else {
value = append(value, "null")
}
}
field_str := strings.Join(field, ",")
value_str := strings.Join(value, ",")
sql = "insert into " + table + "(" + field_str + ") values(" + value_str + ")"
} else {
var set []string
for k, v := range data {
if v != "" {
set = append(set, "`"+k+"`='"+v+"'")
} else {
set = append(set, "`"+k+"`=null")
}
}
set_str := strings.Join(set, ",")
sql = "update " + table + " set " + set_str + " where " + where
}
res, err2 := o.Raw(sql).Exec()
if err2 != nil {
err = err2
num = 0
} else {
num, err = res.LastInsertId()
}
return
}到此就可以实现把目标网址的所有信息全部存入数据库了,但是现在还只能爬一个我们写死的网址。应该是像第一篇所说的 自动去爬取网址自动提取数据再存入数据库的一个这样的循环 ,所以下一篇就来实现一下吧 我们的小爬虫最后一步
