response介绍及应用、乱码问题解决
1. http协议响应数据-response
1.1. 响应数据组成
1.2. 响应行
HTTP/1.1 200 OK |
格式:协议版本+http状态码+状态码含义
1.2.1. http状态码
介绍
用于描述用户浏览器与服务器通信过程中的状态表示
状态码个数
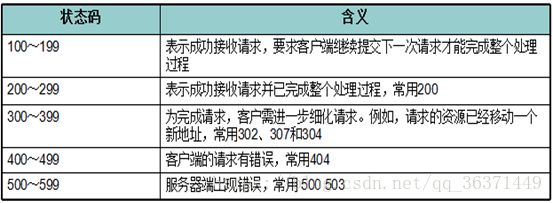
常用状态码
200,通信正常
304,通知浏览器使用缓存(浏览器本地有缓存文件,不请求服务器了)
404,服务器上没有找到对应的资源。用户的错误,用户输错了url导致的。
405,提交的请求方式服务器上没有相应的方法处理,比如,用户提交了post请求,servlet里面没有doPost()方法就会报错.
500,服务器发生错误了,错误是由开发人员代码逻辑不完全导致的。99%是开发人员的错误。
302,通知浏览器进行页面跳转的动作执行
1.3. 响应头
1.3.1. 请求头介绍
响应头的数据构成,响应头的数据是响应给浏览器,一般我们不用读取,但是我们可以设置响应头的数据,让浏览器按照我们指定的设置进行执行响应的功能。响应头信息如下:
Location:http://www.it315.org/index.jsp --跳转方向
Server:apache tomcat --服务器型号
Content-Encoding:gzip --数据压缩
Content-Length: 80 --数据长度
Content-Language: zh-cn --语言环境
Content-Type:text/html; charset=GB2312 --编码
Last-Modified: Tue, 11 Jul2000 18:23:51 GMT --最后修改时间
Refresh:1;url=http://www.it315.org --定时刷新
Content-Disposition:attachment; filename=aaa.zip --下载
Set-Cookie:SS=Q0=5Lb_nQ;path=/search
Expires: -1 --缓存
Cache-Control: no-cache --缓存
Pragma: no-cache --缓存
Connection:close/Keep-Alive --连接
Date: Tue, 11 Jul 200018:23:51 GMT --时间
1.3.2. 设置响应头的核心方法
response.setHeader(name,value) |
由于响应头的格式是以key-value的格式,所以设置响应头的数据需要设置这两个参数就可以了 |
例子
response.setHeader(“location”,”/day37/hello.html”); |
1.3.3. Location
1.3.3.1. 作用
响应头location的作用是通知浏览器要进行页面跳转的目标地址。
http状态码302的作用是通知浏览器进行页面跳转的动作执行,所以响应头location
和http状态码302配合起来才可以完成页面跳转。
1.3.3.2. 实现跳转代码
//需求:跳转到资源CountServlet
//response.setHeader(name, value); 设置响应头key-value格式
response.setHeader("location", "/day37/count");
//设置http状态码为302
response.setStatus(302);
1.3.3.3. 优化跳转资源代码
//一句搞定页面跳转,实现原理就是上面的2句代码
//day37不能写死在代码中,防止修改工程名字,建议使用servletContext获取工程名字
response.sendRedirect(getServletContext().getContextPath()+"/count");
1.3.4. Content-Encoding
1.3.4.1. 格式
Content-Encoding:gzip --数据压缩响应头信息
1.3.4.2. 作用
通知浏览器解压数据后再显示数据。Content-Encoding:gzip,浏览器只支持解压gzip格式的压缩文件。
1.3.4.3. 介绍
一般向客户端浏览器输出大量数据时,为了提供网络传输数据需要对数据进行压缩之后在响应给浏览器,但是浏览器接收的是一个压缩文件,所以需要服务器设置响应头content-encoding通知浏览器解压文件后再显示数据。
1.3.5. Content-Type
1.3.5.1. 格式
Content-Type:text/html; charset=GB2312 --编码
1.3.5.2. 介绍
官方叫法,设置响应正文类型,报文类型,一共包含2部分内容。
第一部分text/htm设置响应的数据类型Mime-Type,这里设置的是响应文本字符串html代码。服务器可以响应任何类型的资源给客户端,资源不同,Mime-Type不同。
这里设置的是响应文本字符串html代码。服务器可以响应任何类型的资源给客户端,资源不同,Mime-Type不同。例如
text/html |
Html代码 |
text/plain |
Txt文本文件 |
image/jpeg |
Jpg图片文件 |
Application/json |
Json数据 |
第二部分charset=GB2312,响应的字符码表gb2312
通知浏览器以什么码表解码数据
1.3.5.3. 作用
content-type用于服务器通知浏览器采用什么码表对服务器响应的数据进行解码。由于服务器响应数据默认采用iso8859-1码表,然而中国大陆浏览器默认采用GBK码表,所以通过设置响应头content-type来统一码表,解决响应中文数据乱码问题。
1.3.5.4. 服务器端输出中文数据有2种方式
1.3.5.4.1. 字节流输出
response.getOutputStream().write("你好".getBytes());
1.3.5.4.2. 字符流输出
//输出的字符流
PrintWriterout = response.getWriter();
//输出字符
out.write("你好");//会乱码
1.3.5.5. 解决服务器输出字符流中文乱码
1.3.5.5.1. 乱码介绍
浏览器与服务器传输中文数据会乱码,原因就是服务器响应数据默认采用iso8859-1码表,浏览器默认采用GBK码表,所以就会乱码
1.3.5.5.2. 解决服务器输出字符流中文乱码问题实现原理
说明:浏览器与服务器传输中文数据需要进行url编码,url编码过程如下:
1. 对字节数组中的负数加256
2. 将加后的字节数组转换为十六进制整型数据
3. 之后在每个16进制数据前加%
例如浏览器与服务器传输你好两个汉字,真实传递的是url编码数据“%E3%BK%A1%B6%19%BA”,如下图就是模拟服务器输出你好给浏览器最终显示结果“??”乱码了的过程
解决上图输出中文字符流乱码问题需要2个步骤:
1. 服务器默认输出中文编码iso8859-1码表修改为utf-8编码码表
2. 服务器通知浏览器采用utf-8解码码表解析数据
1.3.5.5.3. 使用响应头content-type解决乱码代码
//优化解决中文乱码代码
//(即实现修改服务器编码码表为utf-8,又实现通知浏览器解码码表utf-8)
//实现原理是封装了上面2句代码
response.setContentType("text/html;charset=utf-8");
//输出的字符流
PrintWriter out = response.getWriter();
//输出字符
1.3.5.5.4. 优化解决乱码代码
//优化解决中文乱码代码
//(即实现修改服务器编码码表为utf-8,又实现通知浏览器解码码表utf-8)
//实现原理是封装了上面2句代码
response.setContentType("text/html;charset=utf-8");
//输出的字符流
PrintWriter out = response.getWriter();
//输出字符
out.write("hello world 你好");
思考问题
publicvoid doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { response.getOutputStream().write("你好".getBytes());
//思考,字符流输出中文默认乱码,字节流输出默认不乱码,为什么呢? //.getBytes()如果无参,默认是GBK编码,浏览器有默认以gbk解码,所以不乱码了 //使用字节流不安全,因为只有中国浏览器默认以GBK解码。 //所以,输出中文,建议字符流,明确设置服务器码表与浏览器码表一样就安全了
} |
1.3.1. refresh
1.3.1.1. 格式
Refresh:1;url=http://www.it315.org --定时刷新
描述:1秒以后页面跳转到http://www.it315.org
1.3.1.2. 作用
设置浏览器定时刷新页面或定时跳转到指定的资源
1.3.2. Content-Disposition
1.3.2.1. 格式
Content-disposition :attachment; filename=aaa.zip --下载
attachment,通知浏览器不要显示数据要以附件形式下载
filename=aaa.zip,下载的文件名字
1.3.2.2. 作用
通知浏览器不要直接显示数据,以附件形式下载数据。默认浏览器查看数据是直接显示数据,有的资源下载网站需要下载资源数据而不是直接显示,所以需要通过设置响应头content-disposition来通知浏览器以附件下载数据。
1.3.2.3. 案例:实现不同类型的文件下载
l 使用超链接下载的不足:
1) 文本和图片是直接打开,不是下载
2) 容易暴露真实地址,有可能会有盗链
l 步骤:
1) 从链接上得到文件名
2) 得到文件的MIME类型
3) 设置content-type头为MIME类型
4) 设置content-disposition头
5) 得到文件的输入流
6) 得到response的输出流
7) 写出到浏览器端
8) 下载文件名使用汉字的情况
l 下载页面:
DOCTYPE html>
<title>资源下载列表title>
<meta charset="utf-8">
head>
<h2>文件下载页面列表h2>
<h3>超链接的下载h3>
<a href="download/file.txt">文本文件a><br/>
<a href="download/file.jpg">图片文件a><br/>
<a href="download/file.zip">压缩文件a><br/>
<h3>手动编码的下载方式h3>
<a href="down?filename=file.txt">文本文件a><br/>
<a href="down?filename=file.jpg">图片文件a><br/>
<a href="down?filename=file.zip">压缩文件a><br/>
body>
html>
DownServlet
|
public void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
//处理手动编码下载请求 // 1) 从链接上得到文件名 String file = request.getParameter("filename"); // 2) 得到文件的MIME类型 String type = getServletContext().getMimeType("/download/" + file); System.out.println(type); // 3) 设置content-type头为MIME类型 response.setHeader("content-type", type); // 4) 设置content-disposition头,以附件的方式下载文件filename后是文件名,在ie和chrome中汉字使用url编码格式 response.setHeader("content-disposition", "attachment; filename=" + URLEncoder.encode(file, "utf-8")); // 5) 得到文件的输入流 InputStream in = getServletContext().getResourceAsStream("/download/" + file); // 6) 得到response的输出流 OutputStream out = response.getOutputStream(); // 7) 写出到浏览器端 int len = 0; byte[] buf = new byte[1024]; while((len=in.read(buf))!=-1) { out.write(buf,0,len); } in.close(); out.close(); }
|
1.4. 响应体
1.4.1. 介绍
就是服务器输出数据给用户看,浏览器直接要显示给用户,就是服务器输出数据
1.4.2. 作用
1. 输出字符数据、字节数据
2. 输出资源文件数据(资源图片)
3. 输出缓存(内存中)图片(资源没有对应的物理资源)--验证码