flask使用 secure_filename()获取中文文件名问题
用secure_filename获取中文文件名时,中文会被省略。
原因:secure_filename()函数只返回ASCII字符,非ASCII字符会被过滤掉。
解决
(下列方法均测试使用,推荐第一种和第二种)
1、修改源码;
D:\Program Files\Python37\Lib\site-packages\werkzeug\utils.py,找到secure_filename(filename)函数。
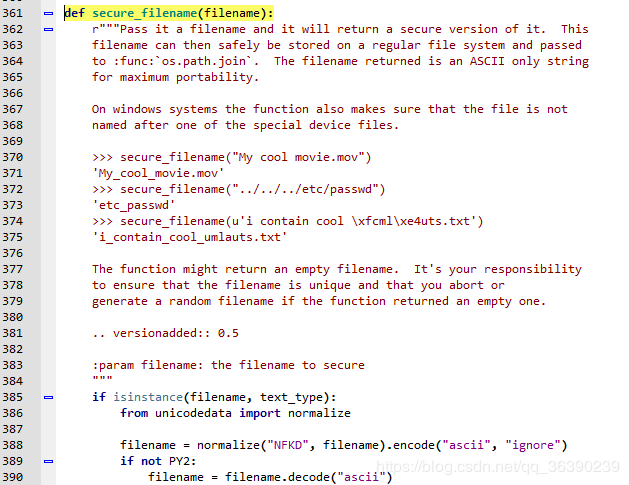
修改后:
if isinstance(filename, text_type):
from unicodedata import normalize
filename = normalize('NFKD', filename).encode('utf-8', 'ignore') # 转码
if not PY2:
filename = filename.decode('utf-8') # 解码
for sep in os.path.sep, os.path.altsep:
if sep:
filename = filename.replace(sep, ' ')
# myself define
# 正则增加对汉字的过滤
# \u4E00-\u9FBF 中文
#构建新正则
_filename_ascii_add_strip_re = re.compile(r'[^A-Za-z0-9_\u4E00-\u9FBF.-]')
# 使用正则
filename = str(_filename_ascii_add_strip_re.sub('', '_'.join(
filename.split()))).strip('._')
2、使用第三方库(pypinyin),将中文名转换成拼音;
from pypinyin import lazy_pinyin
filename = secure_filename(''.join(lazy_pinyin(file.filename)))3、使用uuid模块重命名文件名
python的uuid模块提供UUID类和函数uuid1(), uuid3(), uuid4(), uuid5() 来生成1, 3, 4, 5各个版本的UUID ( 需要注意的是: python中没有uuid2()这个函数)。
a) uuid.uuid1([node[, clock_seq]]) : 基于时间戳
使用主机ID, 序列号, 和当前时间来生成UUID, 可保证全球范围的唯一性. 但由于使用该方法生成的UUID中包含有主机的网络地址, 因此可能危及隐私. 该函数有两个参数, 如果 node 参数未指定, 系统将会自动调用 getnode() 函数来获取主机的硬件地址. 如果 clock_seq 参数未指定系统会使用一个随机产生的14位序列号来代替.
b) uuid.uuid3(namespace, name) : 基于名字的MD5散列值
通过计算命名空间和名字的MD5散列值来生成UUID, 可以保证同一命名空间中不同名字的唯一性和不同命名空间的唯一性, 但同一命名空间的同一名字生成的UUID相同.
c) uuid.uuid4() : 基于随机数
通过随机数来生成UUID. 使用的是伪随机数有一定的重复概率.
d) uuid.uuid5(namespace, name) : 基于名字的SHA-1散列值
通过计算命名空间和名字的SHA-1散列值来生成UUID, 算法与 uuid.uuid3() 相同.4、不使用secure_filename()函数进行文件名检测(不推荐)
5、自定义工具(耗时)