python3 scrapy实战:爬取猎聘网招聘数据至数据库(反爬虫)
首先注明:感谢拉勾网提供的权威、质量的数据,本人抱着学习的态度,不愿增加其服务器负担,与dos攻击。
继前两篇爬取拉勾网、直聘网后的第三篇文章,同样是使用scrapy来获取网站的招聘信息,并且保存至MySQL数据库,与前两篇文章有所差异,下面进入正题:
猎聘网的信息也比较权威、质量,由于吸取了前两次的教训,总结了经验后,在本次的scrapy爬取过程中并没有出现网站的制裁,只是猎聘网的数据信息有点不规范,所以质量相对前两个网站,要稍差一点,所以后期的数据分析工作也会更麻烦了。不过没关系,重在学习嘛:
首先我们来分析一下需要爬取得网页信息:
https://www.liepin.com/job
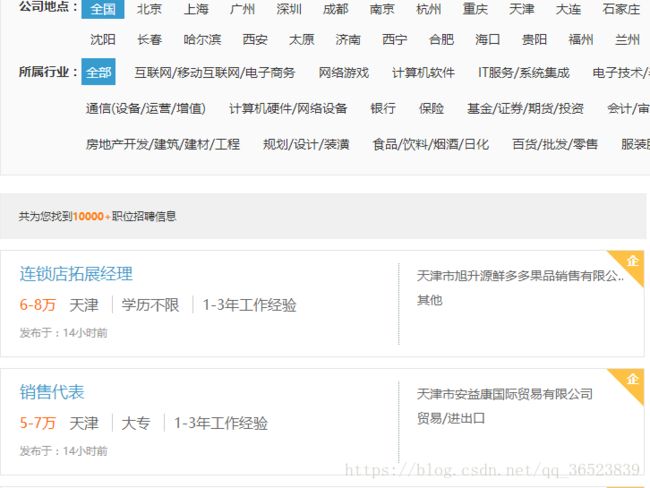
下面这个招聘信息就是我们后面要获取的信息,获取的内容包括(城市、规模、学历、领域、职位、薪水、工作经验等7个内容)
由于我们需要的有的信息在此网页没有,所以我么你需要获取该招聘信息的网址,进入子网页,匹配出所需信息,所以这个网站信息没有前两个好,但是获取信息难度还要高一点。做了前面网页相同的措施,所以没有遇到爬取限制(不知道它设置没有哦)
不停的更换user_agent:

列一长串user_agent出来,后面我们随机选取。
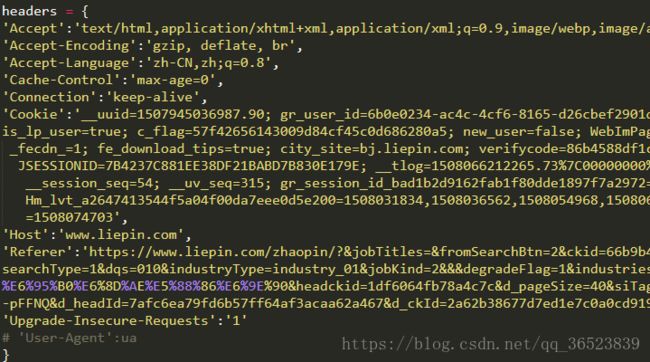
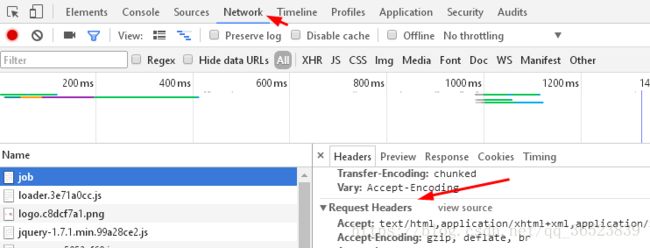
headers的设置,这个在F12的Network的数据包中查找到:
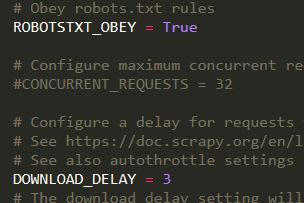
还有在setting中开启某些设置(下载延迟等也是一个措施):
好了简单的措施我们都做了,下面就开始创建scrapy来爬取(这个网站我并没有做太多反爬虫措施):
创建scrapy(不累述,如果不清楚可以先查阅一下资料):

我们先编写容器文件,以便确定我们需要获取的信息(这里我在items里面新建的类,也可以使用原来的):

接着我们来编写spider文件:
spider源码(注意我们需要进入子网页,来获取更多的信息):
# -*- coding: utf-8 -*-
import scrapy
import requests
from bs4 import BeautifulSoup
import re
import random
import time
import os #下面有解释这几个库
path = os.path.abspath(os.path.join(os.getcwd(), "../.."))
import sys
sys.path.append(path)
from get_liepin.items import LiepinItem
import main
user_Agent = [
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60',
'Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; en) Opera 9.50',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0',
'Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; SE 2.X MetaSr 1.0)',
]
headers = {
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate, br',
'Accept-Language':'zh-CN,zh;q=0.8',
'Cache-Control':'max-age=0',
'Connection':'keep-alive',
'Cookie':'__uuid=1507945036987.90; gr_user_id=6b0e0234-ac4c-4cf6-8165-d26cbef2901d; user_kind=0; \
is_lp_user=true; c_flag=57f42656143009d84cf45c0d686280a5; new_user=false; WebImPageId=webim_pageid_364027361196.51575;\
_fecdn_=1; fe_download_tips=true; city_site=bj.liepin.com; verifycode=86b4588df1c040dea596018c8003fff6; abtest=0;\
JSESSIONID=7B4237C881EE38DF21BABD7B830E179E; __tlog=1508066212265.73%7C00000000%7CR000000075%7C00000000%7C00000000;\
__session_seq=54; __uv_seq=315; gr_session_id_bad1b2d9162fab1f80dde1897f7a2972=b5a2b0a7-66d1-421a-b505-a4aeccd698ba; \
Hm_lvt_a2647413544f5a04f00da7eee0d5e200=1508031834,1508036562,1508054968,1508066212; Hm_lpvt_a2647413544f5a04f00da7eee0d5e200\
=1508074703',
'Host':'www.liepin.com',
'Referer':'https://www.liepin.com/zhaopin/?&jobTitles=&fromSearchBtn=2&ckid=66b9b401d4cbc8f3&d_=&isAnalysis=true&&init=-1&\
searchType=1&dqs=010&industryType=industry_01&jobKind=2&&°radeFlag=1&industries=040&salary=100$999&&&key=\
%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90&headckid=1df6064fb78a4c7c&d_pageSize=40&siTag=ZFDYQyfloRvvhTxLnVV_Qg%7EJC8W0LLXNSaYEa5s\
-pFFNQ&d_headId=7afc6ea79fd6b57ff64af3acaa62a467&d_ckId=2a62b38677d7ed1e7c0a0cd919475b0b&d_sfrom=search_unknown&d_&curPage=1',
'Upgrade-Insecure-Requests':'1'
# 'User-Agent':ua
}
class LiepinSpider(scrapy.Spider):
name = 'liepin'
url0 = 'https://www.liepin.com'
url1 = 'https://www.liepin.com/job/pn'
url2 = '/?d_pageSize=40&d_headId=af1e7099f9b8206fd0cec1840bab13b6&d_ckId=af1e7099f9b8206fd0cec1840bab13b6&d_sfrom=search_rencai&d_curPage=0'
page = 100
def get_data(self,link): #此函数用来获取上个页面没有的两个信息
time.sleep(0.1)
ua = random.choice(user_Agent)
headers['User_Agent'] = ua
html = requests.get(link,headers=headers).text
soup = BeautifulSoup(html,'lxml',from_encoding='utf-8')
data = soup.find_all(name='li')
flag = 0
for i in data:
if(i.find_all(name='span')):
pattern = re.compile(r"企业规模.*?[\u4e00-\u9fa5]+") #使用BeautifulSoup和正则表达式来获取
result = pattern.match(i.text)
pattern2 = re.compile(r"所属行业.*?")
result2 = re.findall(pattern2,i.text)
if(result):
flag +=1
companySize = result.group(0)[5:]
if(result2):
flag +=1
industryField = i.text.replace(",","").replace("/","").split()[1]
if(flag == 2):
return companySize,industryField
else:
return None,None
def parse(self, response):
item = LiepinItem()
for i in range(1,41):
city = response.xpath('/html/body/div[1]/div[2]/div/div/div[2]/ul/li[{}]/div/div[1]/p[1]/a/span//text()'.format(str(i))).extract()
education = response.xpath('/html/body/div[1]/div[2]/div/div/div[2]/ul/li[{}]/div/div[1]/p[1]/span[2]//text()'.format(str(i))).extract()
positionName = response.xpath('/html/body/div[1]/div[2]/div/div/div[2]/ul/li[{}]/div/div[1]/a//text()'.format(str(i))).extract()
h = response.xpath('/html/body/div[1]/div[2]/div/div/div[2]/ul/li[{}]/div/div[1]/p[1]/span[1]'.format(str(i))).extract()
salary = response.xpath('/html/body/div[1]/div[2]/div/div/div[2]/ul/li[{}]/div/div[1]/p[1]/span[1]//text()'.format(str(i))).extract()
try:
k = salary[0].split('-')
if(len(k)==1):
mi = int(k[0][:k[0].find('万')])*10/12
ma = int(k[0][:k[0].find('万')])*10/12
else:
mi = int(k[0])*10/12
ma = int(k[1][:k[1].find('万')])*10/12
salary_min = round(mi)
salary_max = round(ma)
salary_h = str(salary_min)+'k'+'-'+str(salary_max)+'k'
except:
salary_min = None
salary_max = None
salary_h = None
workYear = response.xpath('/html/body/div[1]/div[2]/div/div/div[2]/ul/li[{}]/div/div[1]/p[1]/span[3]//text()'.format(str(i))).extract()
work_link = response.xpath('/html/body/div[1]/div[2]/div/div/div[2]/ul/li[{}]/div/div[1]/a//@href'.format(str(i))).extract()
try: #这里异常判断,因为获取的值可能有缺失
companySize,industryField = self.get_data(work_link[0])
except:
companySize = None
industryField = None
next_page_href = response.xpath('/html/body/div[1]/div[2]/div/div/div[3]/div/a[8]//@href').extract()[0]
next_page_data = response.xpath('/html/body/div[1]/div[2]/div/div/div[3]/div/a[8]//@data-promid').extract()[0]
next_link = self.url0+next_page_href+'?'+next_page_data #链接
ua = random.choice(user_Agent)
headers['User_Agent'] = ua #头
if((companySize!=None) and (industryField!=None)):
item['city'] = city[0][:2]
item['salary'] = salary_h
item['workYear'] = workYear[0][:-4]
item['education'] = education[0]
item['industryField'] = industryField
item['companySize'] = companySize
item['positionName'] = positionName[0]
item['salary_min'] = salary_min
item['salary_max'] = salary_max
yield item
if(self.page<99): #一共有100页
print("pn:{}运行中请勿打断...".format(self.page+1))
time.sleep(1)
self.page +=1
yield scrapy.http.Request(url=next_link,headers=headers,callback=self.parse)
def start_requests(self):
start_url = self.url1+str(1)+self.url2
ua = random.choice(user_Agent)
headers['User-Agent'] = ua
return [scrapy.http.Request(url=start_url,headers=headers,callback=self.parse)]首先我们使用start_requests来请求第一页信息,返回至parse函数中,然后在parse中通过判断当前页数,来确定是否继续爬取网页。需要注意的上面的文件中我们导入了之前创建的容器类LagouItem()。os.path.abspath是我用来导入上上层文件的路径,sys.path我用来添加main.py和items.py文件的路径,main.py中,就是执行scraoy的命令,你也可以在cmd中执行scrapy,我之前的文章有介绍很方便的。spider很简单,代码不多,我们介绍pipelines文件。
判断当前的页数,使用拼接的方式来获取新的网页,需要注意的是,子网页中我们没有使用xpath来匹配,而是使用的BeautifulSoup和re正则表达式来获取另外两个信息。
pipelines源码:
import pymysql
import re
class GetLiepinPipeline(object):
def table_exists(self,con,table_name): #这个函数用来判断数据表是否存在
sql = "show tables;"
con.execute(sql)
tables = [con.fetchall()]
table_list = re.findall('(\'.*?\')',str(tables))
table_list = [re.sub("'",'',each) for each in table_list]
if table_name in table_list:
return 1
else:
return 0
def process_item(self, item, spider):
connect = pymysql.connect(
user = 'root',
password = 'root@123456',
db = 'MYSQL',
host = '127.0.0.1',
port = 3306,
charset = 'utf8'
)
con = connect.cursor()
con.execute("use w_lagouwang")
table_name = 'liepinwang'
if(self.table_exists(con,table_name) != 1):
con.execute("drop table if exists liepinwang")
sql = '''create table liepinwang(city varchar(20),companySize varchar(20),education varchar(20),
industryField varchar(50),positionName varchar(40),salary varchar(20),salary_max varchar(10),salary_min varchar(10),
workYear varchar(30))'''
con.execute(sql) #如果不存在,创建表
data = {'city':item['city'],'companySize':item['companySize'],'education':item['education'],
'industryField':item['industryField'],'positionName':item['positionName'],'salary':item['salary'],
'salary_max':item['salary_max'],'salary_min':item['salary_min'],'workYear':item['workYear']}
city = data['city']
companySize = data['companySize']
education = data['education']
industryField = data['industryField']
positionName = data['positionName']
salary = data['salary']
salary_max = data['salary_max']
salary_min = data['salary_min']
workYear = data['workYear']
con.execute('insert into liepinwang(city,companySize,education,industryField,positionName,salary,salary_max,salary_min,workYear)values(%s,%s,%s,%s,%s,%s,%s,%s,%s)',
[city,companySize,education,industryField,positionName,salary,salary_max,salary_min,workYear])
connect.commit() #每次上传后记得提交
con.close()
connect.close()其实很简单的,就是sql语句有点多,和一个判断表的函数,真正的代码不多。
好了,接下来就是运行了,等等我们先配置一下setting文件:
接下来就可以运行了。。。
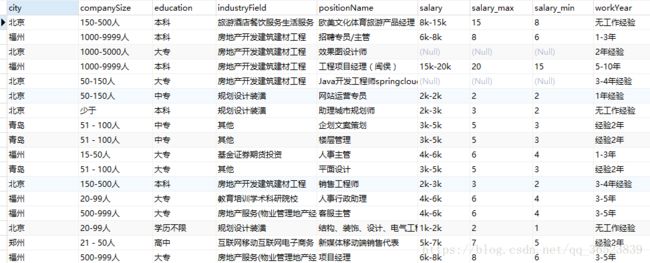
大致数据像上面,对于上面的数据我还做过一点处理,但是不影响上面的操作。
好了猎聘网反爬虫的项目就完成了,可以看出还是挺简单的,只是每一步都有需要细心,还有就是注意文件之间的关联性,其他的就没有了。在这几篇文章中我介绍了scrapy爬取 直聘网、拉勾网,猎聘网等网站,都带有一定的反爬虫机制。由于太累了,可能写的不太详细,有问题的朋友可以留言交流。