绘制学习曲线——plot_learning_curve
学习曲线:一种用来判断训练模型的一种方法,通过观察绘制出来的学习曲线图,我们可以比较直观的了解到我们的模型处于一个什么样的状态,如:过拟合(overfitting)或欠拟合(underfitting)
先来看看如何解析学习曲线图:
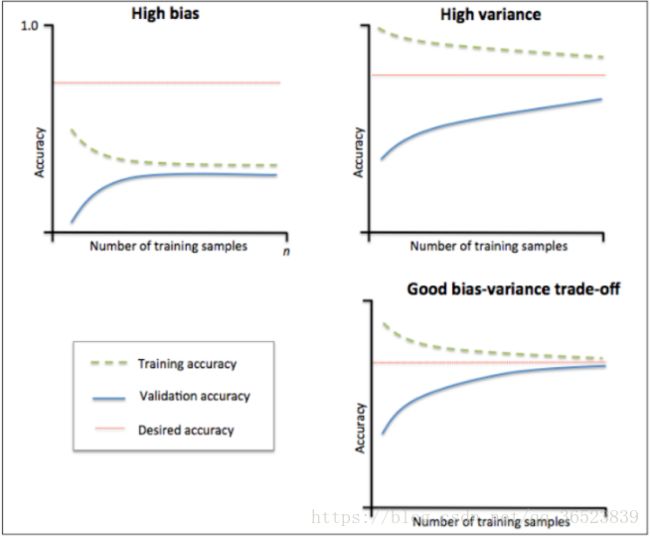
要看深刻了解上面的图形意义,你需要了解偏差(bias)、方差(variance)对于训练模型的意义,可以参考这里,当你了解后,我们来看看上面的图形代表的意义:(横坐标表示训练样本的数量,纵坐标表示准确率)
1:观察左上图,训练集准确率与验证集准确率收敛,但是两者收敛后的准确率远小于我们的期望准确率(上面那条红线),所以由图可得该模型属于欠拟合(underfitting)问题。由于欠拟合,所以我们需要增加模型的复杂度,比如,增加特征、增加树的深度、减小正则项等等,此时再增加数据量是不起作用的。
2:观察右上图,训练集准确率高于期望值,验证集则低于期望值,两者之间有很大的间距,误差很大,对于新的数据集模型适应性较差,所以由图可得该模型属于过拟合(overfitting)问题。由于过拟合,所以我们降低模型的复杂度,比如减小树的深度、增大分裂节点样本数、增大样本数、减少特征数等等。
3:一个比较理想的学习曲线图应当是:低偏差、低方差,即收敛且误差小。
在深刻了解到了学习曲线图的意义后,可以着手挥着该图了。
如何绘制学习曲线:
以下为sklearn官方文档的解释,这里仅做必要的解释:
通过使用sklearn提供的绘制模板,我们也可以根据数据的情况来改变绘制的条件。官方提供的两个样例分别是GaussianNB、SVC两个模型对于load_digits数据集进行拟合后绘制的学习曲线图。
附上完整代码,下面再对相关步骤做说明:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
from sklearn.datasets import load_digits
from sklearn.model_selection import learning_curve
from sklearn.model_selection import ShuffleSplit
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None,
n_jobs=1, train_sizes=np.linspace(.1, 1.0, 5)):
plt.figure()
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel("Training examples")
plt.ylabel("Score")
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.grid()
plt.fill_between(train_sizes, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std, alpha=0.1,
color="r")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std, alpha=0.1, color="g")
plt.plot(train_sizes, train_scores_mean, 'o-', color="r",
label="Training score")
plt.plot(train_sizes, test_scores_mean, 'o-', color="g",
label="Cross-validation score")
plt.legend(loc="best")
return plt
digits = load_digits()
X, y = digits.data, digits.target # 加载样例数据
# 图一
title = r"Learning Curves (Naive Bayes)"
cv = ShuffleSplit(n_splits=100, test_size=0.2, random_state=0)
estimator = GaussianNB() #建模
plot_learning_curve(estimator, title, X, y, ylim=(0.7, 1.01), cv=cv, n_jobs=1)
# 图二
title = r"Learning Curves (SVM, RBF kernel, $\gamma=0.001$)"
cv = ShuffleSplit(n_splits=10, test_size=0.2, random_state=0)
estimator = SVC(gamma=0.001) # 建模
plot_learning_curve(estimator, title, X, y, (0.7, 1.01), cv=cv, n_jobs=1)
plt.show()plot_learning_curve函数官方放提供的模板函数,可以无需修改,初学时我们仅需要知道传入的参数意义即可。
先说说函数里面的一个东西,也是画曲线的核心sklearn.model_selection的learning_curve,该学习曲线函数返回的是train_sizes,train_scores,test_scores:
在画训练集的曲线时:横轴为 train_sizes,纵轴为 train_scores_mean;
画测试集的曲线时:横轴为train_sizes,纵轴为test_scores_mean。
title:图像的名字。
cv:默认cv=None,如果需要传入则如下:
cv : int, 交叉验证生成器或可迭代的可选项,确定交叉验证拆分策略。
cv的可能输入是:
- 无,使用默认的3倍交叉验证,
- 整数,指定折叠数。
- 要用作交叉验证生成器的对象。
- 可迭代的yielding训练/测试分裂。
ShuffleSplit:我们这里设置cv,交叉验证使用ShuffleSplit方法,一共取得100组训练集与测试集,每次的测试集为20%,它返回的是每组训练集与测试集的下标索引,由此可以知道哪些是train,那些是test。
ylim:tuple, shape (ymin, ymax), 可选的。定义绘制的最小和最大y值,这里是(0.7,1.01)。
n_jobs : 整数,可选并行运行的作业数(默认值为1)。windows开多线程需要在"__name__"==__main__中运行。
好了,以上为查阅资料以及文档对于上面参数的解释,下面看看运行的结果:
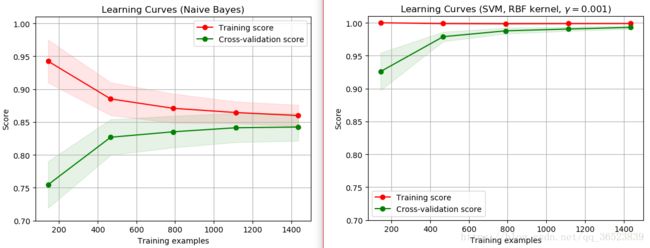
如上图,左边(朴素贝叶斯分类器)收敛但准虽然确度为0.85左右,属于欠拟合;右边(rbf核的SVM)训练分数一直都在一个很高的地方,可能属于一个过拟合问题,这时可以通过更多的训练样本来验证这个分数。
参考文献:官方文档 学习曲线
参考文献:官方文档 交叉验证