https://mp.csdn.net/
Python爬虫 - 最新版12306(2018-12-26)从登录到订票
- 爬虫的原理简述
- 准备
- 一、登录部分
- 处理验证码图片
- 获取验证码图片
- 验证验证码图片
- 点击式验证码图片
- 账号登录
- 账号密码检测
- 到认证中心认证及将TK种到自己的Cookies中
- 二、查询车票信息部分
- 查询车票信息
- 处理并显示车票信息
- 获取车站名信息及处理车站代号
- 三、下单部分
- 选择需要购买的车次
- 检测用户是否登录及检测是否有未完成订单
- 填写购票信息
- 选择乘客
- 选择座位
- 提交订单
- 检测订单信息
- 请求火车票
- 全部代码
一两年前就开始写12306的爬虫,每次才开始都立了一个目标:从登录到查票、订票,如果没有票还可以抢票,一条龙服务。结果每次都是理想丰满现实骨感:
某次:能登录成功了,可把我牛逼坏了,为了奖励自己先放松一段时间(主要为偷懒找一个借口…),然后这个py文件就不知道被放在某个文件夹里多少个月了。
下一次:突然有一天打开这个文件夹,咦?怎么还有一个12306.py的文件?想了一会。。。哦,这好像是几个月前用来爬12306的,打开一看,这是谁写的啊?肯定不是我写的,这么垃圾?注释都没有?给谁看?我写一个肯定比这个好。然后心血来潮又从头开始写,然后又写到某某地方:像我这么优秀的人不能总沉迷于写代码,不行,得找室友开开黑。
…
N次:在某某某老师的压力下,重新写了12306,能登录了,能查票了,能订票了。(抢票也写了,但是没有试验过)。
在这些版本里用过python2里面的urllib、urllib2、cookielib等(好像用了储存cookie的,现在都忘了。。。)写过,后来学了Python3,又用requests这个号称:Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用。并且向你抛出一个警告:非专业使用其他 HTTP 库会导致危险的副作用,包括:安全缺陷症、冗余代码症、重新发明轮子症、啃文档症、抑郁、头疼、甚至死亡。(我不知道Python2里有不有requests)。吓得我赶紧使用这个来写爬虫。后来又发现了selenium这个自动化测试的,感觉这个更简单。(所以没有用这个写过12306,太简单了,不能装逼啊)。如果你看了网上用selenium实现的12306爬虫,你肯定不会选择我这种。

爬虫的原理简述
自己总结的,表述可能不是很准确,能明白大概意思就ok。
我们在使用浏览器正常访问网站的时候,我们通过鼠标点点点等操作,浏览器就可以执行显示我们点击的内容。实际上是我们点击了一些特定的标签或者触发了一些绑定事件什么的,向服务器发送请求,然后接受服务器返回的响应。比如说我们在网页中看到一张图片,那么它可能就是这么来的:先找到服务器主机,对它说:喂,把XXX图片给我。服务器看你顺眼就可能把这张图片给你了(或者看你不是人(通过爬虫进行请求))。得到这张图片,通过浏览器解析就可以看到网页中的图片了。所以这张图片就是这么来的:喂,把XXX图片给我(请求)——把这张图片给你(响应)——浏览器解析(处理响应)。
所以爬虫是什么?简单说就是我们模拟浏览器发送请求——获取响应——处理响应(希望我理解的是正确的)
不批跨了,下面进入正题。(如果看了上面一个12306就爬了几年的就知道我也是个菜鸡,如有错误的地方请指出,如实在看不下去的,想拍我的,我只想对你说:求求你顺着网线来打我啊)。
准备
没有什么可准备的,python运行环境肯定没有问题吧,肯定熟悉Python基础语法以及对Python爬虫有一点了解吧,至于需要安装什么库在用到的时候会告诉安装需要什么库,如果在开头就告诉安装大量的库,如果安装顺利还好,不顺利肯定会影响自己的心情,甚至成为《Python爬虫从入门到放弃》的读者。
一、登录部分
最新版12306(2018年12月11日的)登录有两种方式进行登录:用户名密码登录和二维码登录,我们这里使用第一种方法:用户名加密码进行登录。
登录分析:在我们正常进行登录时,我们都是把账号密码、验证码都输入好了再点击登录按钮就可以进行登录了,在我们看来这就是一个登录操作。其实网页处理的时候把这个登录分为账号密码验证和验证码验证两个部分。所以我们要进行模拟登录就需要进行分析它究竟是先进行什么验证(其实想一下就可以猜到一般都是先进行验证码验证,如果成功再进行账号密码验证)。当然也可以试一下嘛。先胡乱输账号密码和验证码,点击登录按钮,发现它是先提醒你验证码验证失败了,说明是先检测验证码是否正确再检测账号密码。也可以打开F12进行正确登录,通过请求的先后顺序也可以看出验证的顺序。如果你还不信就看JS代码吧(本博文关于JS请求的内容不会讲,如果遇到就直接告诉你们url或者参数什么的,第一:我的JS也是水得很的,只能看懂很简单的代码,所以可能会错误百出;第二是怕没有接触过前端的看了就懵逼了)。既然分析出了登录处理的先后顺序,那么我们下面先对验证码进行处理,然后再对账号密码进行处理。
处理验证码图片
我们需要处理验证码,验证码从哪来?请看下面讲解。
获取验证码图片
我们需要处理验证码,验证码从哪来?肯定不是自己造一个啊。所以我们来看看它是怎么来的。进入12306登录界面,按F12或者右键检查元素,打开开发者工具(我用的QQ浏览器,浏览器不同,开发者工具有可能不同),选择Network。这样就准备就绪了。

这里面就可以看到向服务器发送的请求。现在我们要获得一张验证码,怎么获得?看到刷新那两个字没有?对,就是验证码图片右上角的那个。点它一下,在开发者工具里出现了什么?没错,这就是向服务器要图片的请求。
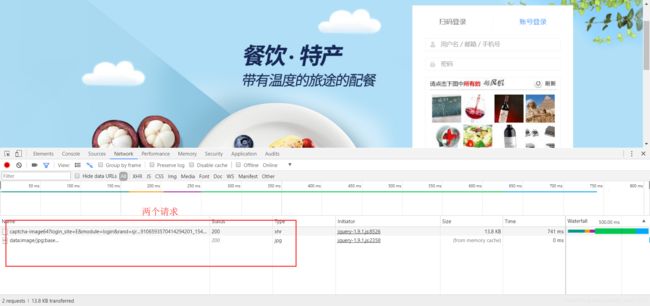
我们点一下第一个请求,然后又出现了一些东西,最上面有Headers、Preview、Response什么的,点击Response,也就是响应,看到中文字没有?生成验证码成功?把下面的滚动条往后拉,怎么全是一些看不懂的天文,你说我验证码生成成功了,它在哪里啊?有点经验的都知道,这些天文就是base64编码过的图片数据。其实在之前的12306版本中不会做这样的编码。
以前获取图片的链接是这个:https://kyfw.12306.cn/passport/captcha/captcha-image?login_site=E&module=login&rand=sjrand&1545056237081&callback=jQuery19106593570414294201_1545055363558&_=1545055363561
现在获取图片的链接是这个:https://kyfw.12306.cn/passport/captcha/captcha-image64?login_site=E&module=login&rand=sjrand&1545056237081&callback=jQuery19106593570414294201_1545055363558&_=1545055363561。
看出主要的部分有什么不同了吗?没错,现在的就是在“captcha-image”后面多了“64”,64?不就是base64嘛。哈哈哈。
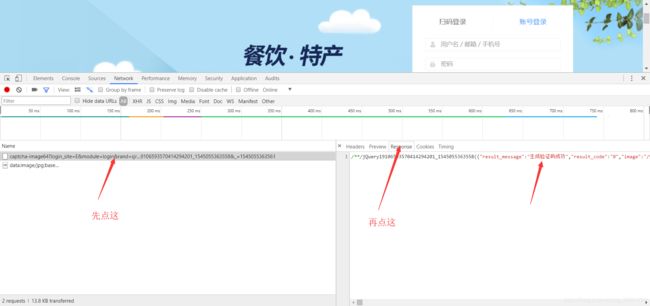
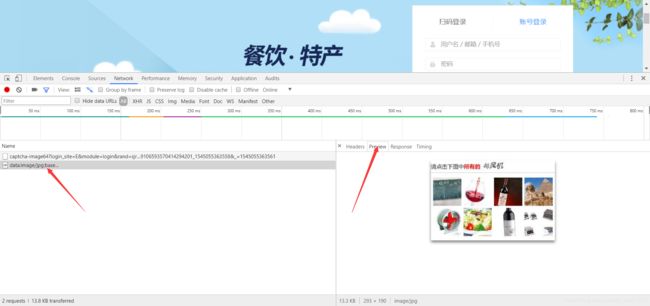
我们在点第二个看看,这次我们点Preview。看到没,这就是验证码图片。点击Headers,发现里面也有很多天文,仔细一看,好像和第一个请求的响应里面的差不多。可以猜出图片就是这些天文生成的。
下面我们开始在Python里面来获取验证码图片。
import requests # 导入requests
url = 'https://kyfw.12306.cn/passport/captcha/captcha-image64?login_site=E&module=login&rand=sjrand&1545056237081&callback=jQuery19106593570414294201_1545055363558&_=1545055363561'
res = requests.get(url)
print(res.text)
运行,发现和第一个请求响应的结果一样,说明我们获取验证码图片成功了。那么怎么把天文转为图片呢?这里就需要用到base64这个库,对base64的字符串进行解码。
import requests
import base64
url = 'https://kyfw.12306.cn/passport/captcha/captcha-image64' # 我发现后面的参数不写也能够获取,那我们就不写吧
res = requests.get(url).json() # 把结果转为json形式
print(res['image']) # 打印可以看到我们已经把那些看不懂的字符串提取出来了
with open('captcha.jpg', 'wb') as f:
f.write(base64.b64decode(res['image'])) # 把字符串转为字节,然后写入到图片文件中
找到你保存到的图片位置,可以看到我们已经把验证码图片拿到了。是不是很简单?

验证验证码图片
得到了验证码图片,现在就可以开始进行验证了。怎么验证?为什么12306知道我点击的图片是对的或者是错的?啥?不知道?不知道就打开F12,正常请求一下,看看它是怎么进行验证的。
照着下面的步骤来。

点击登录按钮后又出现了三个新的请求。点击captcha-check的那个请求,在右边可以看的你点击的验证码是否是正确的。
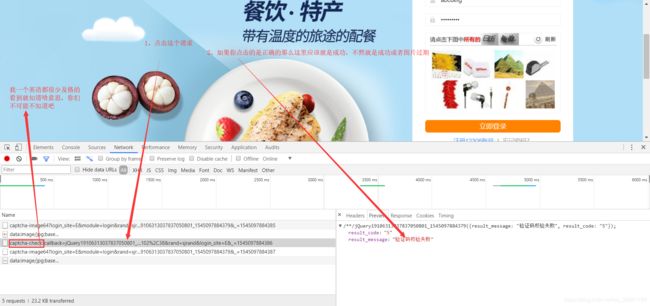
响应里面告诉我们点击的图片是否正确,那么它是怎么知道我们点击的图片是否是正确的呢?老司机已经猜到了,肯定在请求里携带了参数的啊。
就像我和你考试对答案,我问你:第一题我选对了吗?你肯定会说:你是傻逼吗?你都不告诉我你第一题选什么,我怎么知道你选对没有?
检测图片是否点击正确一样,图片是题目,点击的结果是答案。所以服务器知道我们点击的验证码是否正确,肯定是以某种形式把我们点击的信息传递给服务器了,这样服务器才能进行判断。
还是点击刚才的那个请求,然后点击Headers,滑动到最下面,如图。(有可能浏览器不一样,开发者工具显示就不一样,比如说火狐它就是中文的,并且把参数也给你单独分了出来,其实都是差不多的)。
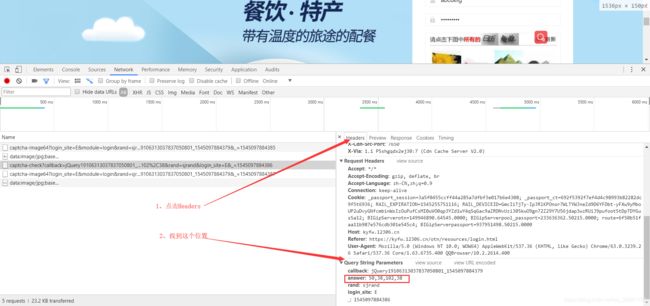
在我圈出来的地方看到没?answer=答案,这意思就是我选的答案是这个,问服务器我选对没有。仔细观察,我们刚才明明只点了两个图片,怎么答案出现了四个?你再试一下点一个、三个或者更多,发现都是你点击图片的2倍。这是什么意思?在数学中,我们怎么在一个平面确定一个点?你肯定脱口而出:不就是它的横纵坐标来确定吗,这么简单的问题,中国学生都知道。再回到12306,发现12306好像也是这么判断我们点击的哪个图片了。点击一个图片,就有两个答案,不就是横纵坐标吗。我们再试一下点击验证码图片的最左上角,和最右下角,再看一下传递的答案,发现前两个数字接近0,后两个参数接近图片的大小。(忘了说了,在程序猿的世界里,数数从0开始数,坐标原点(0,0)在左上角)。
知道我们向服务器发送的答案是怎么来的了,现在我们就在Python中写。先获取一张验证码图片,保存到你指定的位置,找到你保存的图片打开,然后选择正确的图片,输入我们下面计算的点坐标,发送给服务器,让服务器告诉我们是否点击的是正确的。
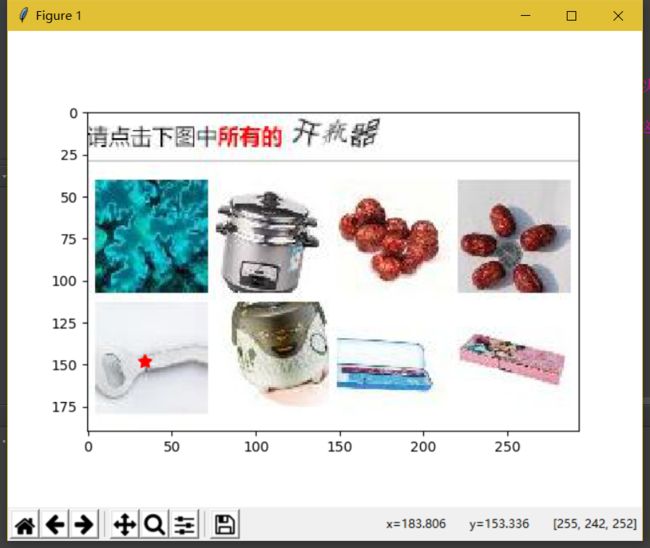
在做之前我们还有计算一下哪些范围内的点才是正确的(不计算也可以,我在后面也写了一个弹出一张验证码,点击就可以了)。比如我们要点击下面这张图片中的开瓶器。第一张和第八张是开瓶器吧。当我们点击的两个点落在这两张图片的范围内,服务器就算我们点击正确了。所以我们计算一下这些图片的中心点的大概位置。灵魂画手已上线,如图所示。

 只是算大概位置,计算结果我们都取算出结果左右5的倍数的整数吧。比如说第一个点是:(37.5,37.5) 可以取(35,35)或者(40,40)。
只是算大概位置,计算结果我们都取算出结果左右5的倍数的整数吧。比如说第一个点是:(37.5,37.5) 可以取(35,35)或者(40,40)。
第一个点:(35,35)
第二个点:(110,35)
第三个点:(185,35)
第四个点:(260,35)
第五个点:(35,110)
第六个点:(110,110)
第七个点:(185,110)
第八个点:(260,110)
我们把获取验证码图片的代码和检测的代码封装成函数。代码如下:
import requests # 导入这个库
import base64
# 获取一张验证码图片
def get_captcha():
url = 'https://kyfw.12306.cn/passport/captcha/captcha-image64' # 我发现后面的参数不写也能够获取,那我们就不写吧
res = requests.get(url)
with open('captcha.jpg', 'wb') as f:
f.write(base64.b64decode(res.json()['image'])) # 把字符串转为字节,然后写入到图片文件中
# 检测验证码图片
def captcha_check():
url = 'https://kyfw.12306.cn/passport/captcha/captcha-check'
answer = input('请输入验证码:') # 注意输入的格式: x1,y1,x2,y2
# get请求可以直接在地址后面拼接参数,也可以用params进行传递参数。
params = {
'callback': 'jQuery19104534505650716114_1545106279315',
'answer': answer,
'rand': 'sjrand',
'login_site': 'E',
'_': '1545106279318'
}
res = requests.get(url, params=params)
print(res.text) # 打印检测图片的响应信息
if __name__=='__main__':
get_captcha()
captcha_check()
![]()
自己试一试,看看打印,怎么样?是不是无论怎么输入都打印:验证码校验失败,信息为空?就算输入错了,也不应该告诉我们为空啊,不信在浏览器上点击错误的图片试一下,发现它是告诉你输入的是错误的。我们明明输了,为什么它说信息为空?原因:虽然你告诉了服务器你的答案,但是你没有告诉它这个答案是去检测哪张验证码图片!因为在你访问12306时,其他人有可能在访问。比如张三向服务器请求了一张图片,李四这时候也请求一张图片,张三告诉服务器:我点击的验证码是XXXX,你看我点的对不对?服务器就懵了,因为服务器和张三、李四都是通过网线连接的,就给服务器发一个答案,它总不可能顺着网线来找你,看是谁要图片。所以验证图片和答案应该也是有一个对应关系的,在发送点击的答案时也要把这个答案的图片(或者代表这张图片的标志)发给服务器验证。
那么怎么知道是验证谁的图片?我们正常登录时它是怎么知道的呢?看一下获取验证码图片请求的头信息,里面的Response Headers响应头,有一个Set-Cookie字段。查看_passport_session对应的值。再查看检测验证码的请求的头信息,里面的Request Headers请求头,有一个Cookie,找到_passport_session对应的值,把它和刚才我们在获取验证码响应头里面的对比一下,发现它们是一样的。相关Cookie和Session知识:Cookie/Session机制详解
当你向服务器请求一张验证码图片时,服务器给你通过Set-Cookie,给你一个Cookie,就相当于把你这张图片做了标记,下次在验证图片的时候,再把这个标记和你点击的答案传给服务器,服务器就知道:哦,你要我验证XXX图片的答案。
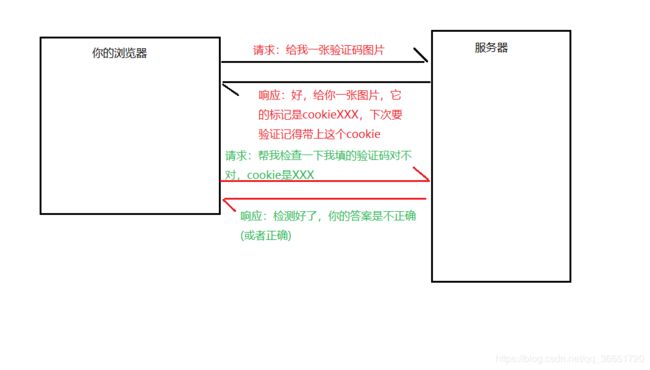
既然知道了为什么总是提醒我们信息为空了,就动手在Python里面在获取图片时拿到服务器给的cookie,然后再检测图片时,把cookie方在检测请求头里。能不能成功,试一下就知道了。
import requests # 导入这个库
import base64
# 获取一张验证码图片
def get_captcha():
url = 'https://kyfw.12306.cn/passport/captcha/captcha-image64' # 我发现后面的参数不写也能够获取,那我们就不写吧
res = requests.get(url)
global cookies # 设置一个全局的变量
cookies = res.cookies # 从这个响应里面获取cookies,保存到全局变量中
# print('服务器设置的Cookies:', cookies)
with open('captcha.jpg', 'wb') as f:
f.write(base64.b64decode(res.json()['image'])) # 把字符串转为字节,然后写入到图片文件中
# 检测验证码图片
def captcha_check():
url = 'https://kyfw.12306.cn/passport/captcha/captcha-check'
answer = input('请输入验证码:') # 注意输入的格式: x1,y1,x2,y2
params = {
'callback': 'jQuery19104534505650716114_1545106279315',
'answer': answer,
'rand': 'sjrand',
'login_site': 'E',
'_': '1545106279318'
}
res = requests.get(url, params=params, cookies=cookies) # 在请求检测验证码图片时,给请求头加上全局变量中的cookies
print(res.text)
# print(res.request.headers['Cookie']) # 打印检测验证码图片请求头里的cookie
if __name__ == '__main__':
get_captcha()
captcha_check()
没有成功?不可能,你打印一下检测验证码图片请求头里的cookie是不是和服务器设置的一样。
![]()

点击式验证码图片
这里我再贴出获取验证码图片后直接显示出来可以直接点击的代码,就不用每次输入那么麻烦了。(你如果觉得下面的代码写起来更麻烦那就用输入的方式吧)。需要安装第三方库:numpy、matplotlib、PIL ,应该都可以直接用pip直接安装,如果不行就在网上找其他方法安装,满大街都是。
import requests
import base64
import numpy as np
from matplotlib import pyplot as plt
from PIL import Image
import io
points = [] # 储存点击点的坐标
# 获取一张验证码图片
def get_captcha():
url = 'https://kyfw.12306.cn/passport/captcha/captcha-image64' # 我发现后面的参数不写也能够获取,那我们就不写吧
res = requests.get(url)
global cookies # 设置一个全局的变量
cookies = res.cookies # 从这个响应里面获取cookies,保存到全局变量中
# print('服务器设置的Cookies:', cookies)
return io.BytesIO(base64.b64decode(res.json()['image'])) # BytesIO把图片字节存入内存,使Image.open可以像文件一样操作它
# 如果要显示图片,可以直接返回图片的字节,就不用保存图片然后再用Image.open打开(当然,如果你用不来也可以先保存到本地,然后用Image.open打开)
# with open('captcha.jpg', 'wb') as f:
# f.write(base64.b64decode(res.json()['image'])) # 把字符串转为字节,然后写入到图片文件中
# 显示验证码图片
def show_img():
o_img = Image.open(get_captcha())
np_img = np.array(o_img) # 把这个图片GRB转为矩阵(和多维列表差不多)
plt.imshow(np_img) # 放入显示的图片矩阵
plt.gcf().canvas.mpl_connect('button_press_event', mouse_press) # 添加鼠标按下事件
plt.show() # 显示
# 鼠标按下
def mouse_press(event):
x = event.xdata # 在图片中点击的x坐标
y = event.ydata # 在图片中大奖的y坐标
if y < 40:
return
points.append([int(x), int(y)]) # 添加到全局的变量中
plt.scatter([x for x, y in points], [y for x, y in points], c='r', s=100, marker=(5, 1, 0)) # 画散点图,第一个参数是横坐标,第二个是纵坐标,c是颜色,s是大小,marker是形状
plt.gcf().canvas.draw() # 重新绘制
# 检测验证码图片
def captcha_check():
url = 'https://kyfw.12306.cn/passport/captcha/captcha-check'
answer = ','.join([str(x) + ',' + str(y) for x, y in points]) # 转为需要传递的参数格式
params = {
'callback': 'jQuery19104534505650716114_1545106279315',
'answer': answer,
'rand': 'sjrand',
'login_site': 'E',
'_': '1545106279318'
}
res = requests.get(url, params=params, cookies=cookies) # 在请求检测验证码图片时,给请求头加上全局变量中的cookies
print(res.text)
# print(res.request.headers['Cookie']) # 打印检测验证码图片请求头里的cookie
if __name__ == '__main__':
show_img()
captcha_check()
现在我们就可以直接点击正确的图片,然后关掉这个窗口(这个窗口相当于阻塞),就可以进行验证了。
显示出来的图片:
账号登录
上面我们已经把验证码验证成功了,接下来就该是登录的第二部分了:账号和密码处理。有了上面的经验,下面不就轻车熟路了吗?

账号密码检测
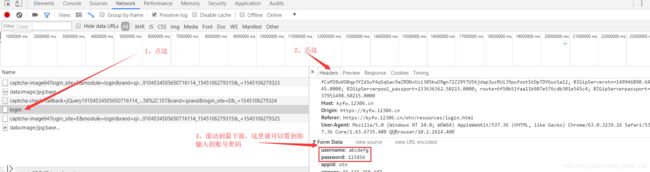
还是一样,在登录界面打开开发者工具,这次我们把验证码输入正确,账号密码随你输,点击登录,发现在检测验证码去请求后面又多了一个login请求。一看就知道是对登录的账号密码进行验证的请求。肯定也传递了参数,跟上面传递点击的图片答案一样,按着那个步骤找到传参的位置。可以看到你输入的用户名和密码。
这个就简单了,直接在Python里面进行请求登录。
# 登录
def login():
url = 'https://kyfw.12306.cn/passport/web/login'
data = {
'username': '你的账户',
'password': '你的密码',
'appid': 'otn',
# 'answer': '43,115,258,107' # 这里可以不用写这个参数,以前版本的12306也没有这个参数,允也许现在没有对它进行验证吧
}
res = requests.post(url, data=data, cookies=cookies) # 这里也要加上全局的cookies
print(res.text)
if __name__ == '__main__':
show_img()
captcha_check()
login()
运行,不出意外的话出现下面这个。
![]()
登录成功!!!这么简单?怎么比验证码还简单?别急,我们先来验证是不是真的登录成功了。
到认证中心认证及将TK种到自己的Cookies中
正常登录进去在个人中心会显示:XXX,先生或者女士,上午好,下午好什么的。我们也用Python请求这个地址:https://kyfw.12306.cn/otn/view/index.html,然后打印它的响应,是网页源代码,按ctrl+F在打印的网页源代码中搜索你的名字,这样肯定是找不到滴。因为它是通过ajax进行加载的,需要了解的可以在JS源代码中看到。我就直接说了ajax进行请求的地址了(担心对JS没有了解的老哥会懵),在开发者工具里面也可以看到这个请求:https://kyfw.12306.cn/otn/index/initMy12306Api
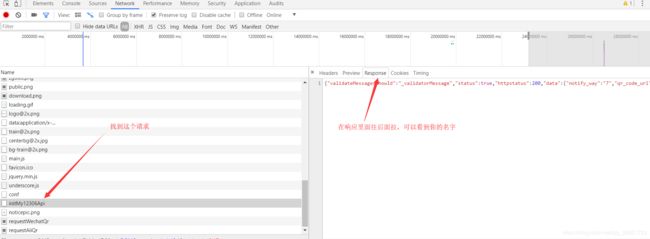
我们的个人中心的名字就是通过这个请求来的,在登录成功后也请求一下这个地址,看可不可以获得我们的名字。先贴一张图片,因为结果是不正确的。这个请求的响应是得到的是登录界面的网页代码。也就是说我们请求初始化个人信息的一些参数,服务器判断我们没有登录,就给我们重定向到登录界面了。可是我们在上面登录就返回的结果里面告诉我们登录成功了啊,为什么它要跳转到登录界面要我们重新登录?思路和验证码验证一样,服务器把你当成两个人了呗,猜测应该是cookies有问题。

查看这个请求的cookies,发现一个JSESSIONID,老司机都应该知道,一般网站登录成功后会给你一个JSESSIONID,每次浏览器发出的请求,都会在请求头里带JSESSIONID来标识你自己。 所以这个JSESSIONID我们需要加在请求头里,它怎么来的?不知道。还有一个名字为tk的也是一个关键的cookie。这个是怎么来的?也不知道。但是肯定都是在先前的请求中服务器响应给我们的,所以我们要在这个请求的前面去找。
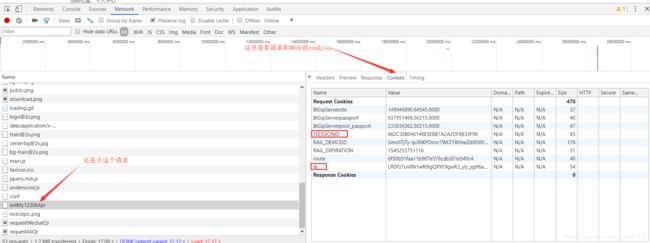
这么多请求怎么可能一个一个找吧。如果看到懂一点点JS代码的可以从登录的JS代码开始看,里面把请求了什么url和参数怎么来的都告诉你了,不然就靠下面这个猜测加估计找吧。提醒一下:这里最好用火狐浏览器,我的获取到的部分请求的响应在这种开发者工具里会加载失败,我也不清楚,或许就是我的问题吧,我用火狐浏览器开发者工具就可以看到,当然如果有会抓包工具的应该就更好吧,反正我是用不来。
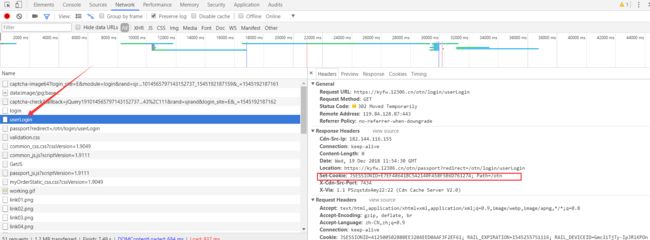
一般css、图片这些请求是不需要看的。我们先看JSESSIONID从哪来的,从刚才登录的那个login请求开始向下找,发现它下面一个请求叫userLogin,(忘记说了,在跳转界面是,像QQ浏览器这种的开发者工具会清空旧界面的请求日志,所以这里需要把Preserve log勾上,就在小红点那一行。火狐浏览器就不用了,它会保存)。怎么登录了一次,还要登录一次?恩,好像不符合常理,那就点开看一下。
因为initMy12306Api请求头用到了cookie,那么一定是前面的响应头中设置了cookie,所以我们只看响应头里面有不有Set-Cookie。开发者工具不一样有可能显示的结果不一样,比如用我们QQ浏览器,userLogin这个响应头里面有Set-Cookie这个字段,用火狐的话就没有。但是,有这个Set-Cookie,里面的JSESSIONID对应的值不不一定就是我们要找的,把userLogin这个请求Set-Cookie中的JSESSIONID对应的值和上面的initMy12306Api请求中的对照看一下,发现它们是不一样的,所以这个JSESSIONID不是我们需要找的。
QQ浏览器中:
火狐浏览器中:虽然响应头没有Set-cookie,但是在请求头里携带了一个JSESSIONID的cookie,我也不知道它怎么来的。把它的值和initMy12306Api中的比较一下发现不对,所以不知道它怎么来的也无所谓了,反正也不需要它。

紧接着userLogin下面的名字为passport?redirect=/otn/login/userLogin的请求,好像是什么重定向啥啥啥的,里面也有有“用户登录”这个英文:userLogin。既然我们选择了一个一个看的方法那就看一下吧。点看一看,嘿,里面也有Set-cookie这个字段,它里面也有JSESSIONID的cookie,把它和initMy12306Api中的一对比,发现它们一样,终于找到了JSESSIONID了。(其实这个请求我们在写代码的时候不需要。在后面有一个“将TK种到自己的Cookies中”——JS源代码中是这样写的,这个请求会给你设置JSESSIONID。有的老哥就会说了:眼睛都看花了,你居然说这个请求其实不需要? 恩,没错,还是那句话,顺着网线来拍我呀。哈哈哈。其实也不是全部没有用,因为很多网站都会做这样的设置,不一定只局限于Cookie,有可能你请求一个链接时,它里面需要一个必须的参数,而这个参数就有可能是前面请求得到的,所以你也可以用这种方法进行查找)。
然后再找tk从哪里来的(放心,这个是必须要的)。结合刚才登录成功返回的信息
{“result_message”:“登录成功”,“result_code”:0,“uamtk”:“jFCtvgZBmIb8ItK1OAoBp65EgG5wCOEnn-UkzooBJZY091210”},发现有一个umatk,大概浏览一下全部请求也有个叫umatk,点开看一下。发现好像就Set-Cookie有一个名字为umatk的cookie。感觉没有啥用,那就继续往吧。嘿,晃眼一看,就接着下面也有一个差不多的:uamauthclient,打开看一下。哇,Set-Cookie里面果然有一个叫tk的cookie,再和initMy12306Api的tk一比较,一样。说明我们请求这个url就可以得到tk这个cookie。
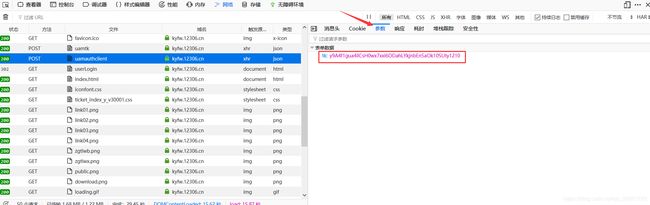
请求url需要什么?最基本的url吧,请求的类型吧,如果需要传参还需要参数等等。点开uamauthclient这个请求,请求网址和请求方法在看到了。
 再看一下参数。妈耶,我们不是通过请求这个地址获取tk这个cookie吗?为什么请求这个地址喊我们传参数就要tk?这就是我在上面说的:一个请求的参数可能是之前请求的响应。我们刚才看umatk这个请求的时候还没有看它的响应是什么,万一里面就有tk呢?
再看一下参数。妈耶,我们不是通过请求这个地址获取tk这个cookie吗?为什么请求这个地址喊我们传参数就要tk?这就是我在上面说的:一个请求的参数可能是之前请求的响应。我们刚才看umatk这个请求的时候还没有看它的响应是什么,万一里面就有tk呢?
uamauthclient请求:
打开uamtk请求看一下响应,好像这个请求是在进行什么验证,不管,我们找我们要的tk,好像没有啊。细心的小伙伴已经发现了,newapptk就是tk,只是一个叫tk一个叫newapptk而已。
uamtk请求:
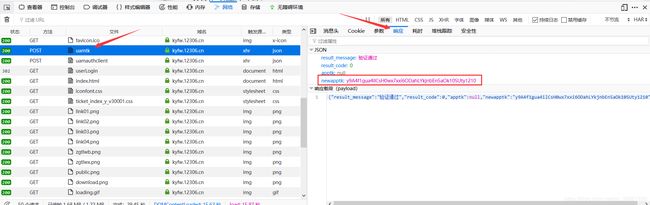
现在我们需要的JSESSIONID和tk都已经找到了。理一下思路:我们要去请求initMy12306Api名字的请求,看有不有自己的名字,而这个请求需要JSESSIONID和tk,JSESSIONID可以通过userLogin获得。(在写代码时可以请求uamauthclient也可以获得,所以请求uamauthclient既可以获得JSESSIONID也可以获得tk,我们就只请求uamauthclient就好了)。tk通过uamauthclient获得,而uamauthclient需要一个参数,这个参数在uamtk的响应中。它们cookie
那么我们的请求顺序应该是:uamtk >>> uamauthclient >>> initMy12306Api。
下面就贴账号密码登录的代码,验证码部分的代码的需要自己加上。
# 登录
def login():
url = 'https://kyfw.12306.cn/passport/web/login'
data = {
'username': '你的账号',
'password': '你的密码',
'appid': 'otn',
# 'answer': '43,115,258,107' # 这里可以不用写这个参数,以前版本的12306也没有这个参数,允也许现在没有对它进行验证吧
}
res = requests.post(url, data=data, cookies=cookies) # 这里也要加上全局的cookies
print('登录:', res.text)
print('登录cookie:', res.cookies)
url = 'https://kyfw.12306.cn/passport/web/auth/uamtk'
data = {
'appid': 'otn'
}
res = requests.post(url, data=data, cookies=res.cookies) # 不管三七二十一,把上一个响应cookies作为这一次请求cookies
print('认证:', res.text)
print('认证cookie:', res.cookies)
url = 'https://kyfw.12306.cn/otn/uamauthclient'
data = {
'tk': res.json()['newapptk']
}
res = requests.post(url, data, cookies=res.cookies) # 注意:这个cookies又是认证cookies了
print('种植tk:', res.text)
print('种植tkcookie:', res.cookies)
init_my12306(res.cookies) # 把tk和JSESSIONID传给初始化的请求作为cookies
# 查看是否有自己的名字
def init_my12306(c):
url = 'https://kyfw.12306.cn/otn/index/initMy12306Api'
res = requests.get(url, cookies=c)
res.encoding = 'utf8'
print(res.text)
if __name__ == '__main__':
show_img()
captcha_check()
login()
登录成功,打印的结果:

登录部分已经完成了,当看到自己的名字的时候是不是感觉自己很牛逼啊。

我们是全手动把上一个请求响应的cookie加到下一个请求的请求头里(还好这个上一个响应cookie就是下一个请求cookie,是连续的),其实requests有一个对象,会把你的请求当成一个会话,这样就不用每次自己都需要添加cookie了。
我们这些方法写在一个类里面,以下是登录部分的全部代码,在控制台打印的结果和上面的一样:
import requests
import base64
import numpy as np
from matplotlib import pyplot as plt
from PIL import Image
import io
class Spider:
def __init__(self):
self.session = requests.session() # 获取会话这个对象, 只需要在请求时把requests换成self.session就可以了
self.points = [] # 储存点击点的坐标
# 获取一张验证码图片
def get_captcha(self):
url = 'https://kyfw.12306.cn/passport/captcha/captcha-image64' # 我发现后面的参数不写也能够获取,那我们就不写吧
res = self.session.get(url) # 换成self.session,下面的也一样
return io.BytesIO(base64.b64decode(res.json()['image'])) # BytesIO把图片字节存入内存,使Image.open可以像文件一样操作它
# 显示验证码图片
def show_img(self):
o_img = Image.open(self.get_captcha())
np_img = np.array(o_img) # 把这个图片GRB转为矩阵(和多维列表差不多)
plt.imshow(np_img)
plt.gcf().canvas.mpl_connect('button_press_event', self.mouse_press)
plt.show()
# 鼠标按下
def mouse_press(self, event):
x = event.xdata # 在图片中点击的x坐标
y = event.ydata # 在图片中大奖的y坐标
if y < 40: # 如果点击图片上面的提示部分就直接返回
return
self.points.append([int(x), int(y)]) # 添加到全局的变量中
plt.scatter([x for x, y in self.points], [y for x, y in self.points], c='r', s=100, marker=(5, 1, 0)) # 画散点图,第一个参数是横坐标,第二个是纵坐标,c是颜色,s是大小,marker是形状
plt.gcf().canvas.draw() # 重新绘制
# 检测验证码图片
def captcha_check(self):
url = 'https://kyfw.12306.cn/passport/captcha/captcha-check'
answer = ','.join([str(x) + ',' + str(y - 40) for x, y in self.points]) # 转为需要传递的参数格式
params = {
# 'callback': 'jQuery19104534505650716114_1545106279315',
'answer': answer,
'rand': 'sjrand',
'login_site': 'E',
'_': '1545106279318'
}
res = self.session.get(url, params=params) # 在请求检测验证码图片时,给请求头加上全局变量中的cookies
print(res.text)
# 登录
def login(self):
url = 'https://kyfw.12306.cn/passport/web/login'
data = {
'username': '你的账号',
'password': '你的密码',
'appid': 'otn',
# 'answer': '43,115,258,107' # 这里可以不用写这个参数,以前版本的12306也没有这个参数,允也许现在没有对它进行验证吧
}
res = self.session.post(url, data=data)
print('登录:', res.text)
url = 'https://kyfw.12306.cn/passport/web/auth/uamtk'
data = {
'appid': 'otn'
}
res = self.session.post(url, data=data)
print('认证:', res.text)
url = 'https://kyfw.12306.cn/otn/uamauthclient'
data = {
'tk': res.json()['newapptk']
}
res = self.session.post(url, data)
print('种植tk:', res.text)
self.init_my12306()
# 查看是否有自己的名字
def init_my12306(self):
url = 'https://kyfw.12306.cn/otn/index/initMy12306Api'
res = self.session.get(url)
print(res.text)
if __name__ == '__main__':
spider = Spider() # 实例化一个对象
spider.show_img()
spider.captcha_check()
spider.login()
二、查询车票信息部分
如果你要买票,肯定先要查询自己车票,然后选择自己想要乘坐的车次。所以登录成功了就开始查询车票吧。不登录也可以查询车票,可以自己去试一下。
查询车票信息
先进入车票查询的界面,同样打开开发者工具,选择自己的出发站、到达站、出发日期,点击查询。比如下面是我查询的车票:

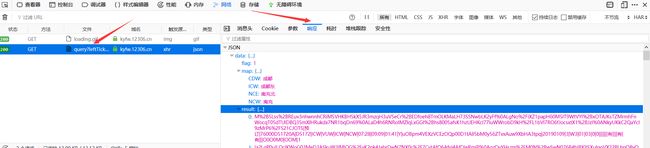
点击一看这个请求:query?leftTicketDTO.train_date…肯定就是查询车票的请求,点开这个请求,查看给我们的响应信息。这个结果是以JSON的形式返回,在里面可以看到有我们输入的出发站、到达站,result里面就是你查询出来的车票信息。这些响应的信息的顺序和浏览器显示出来的车次顺序是一致的,把这些信息和浏览器显示的进行对比,发现每一个信息都是以:|符号进行分割的,所以我们待会处理的时候也以这个符号作为分割。再查看一下请求参数,也是我们选择的站点、时间等信息,只不过用一些车站名称的代号来表示这些车站名称。(后面我们也会获取这些车站名称对应什么代号)。
查询车票响应结果:
请求参数:

我们在Python中也进行这个请求,看能不能获取车票信息。
# 查询车票
def query_ticket(self):
url = 'https://kyfw.12306.cn/otn/leftTicket/queryX' # 注意:这里有可能最后的X会是A,根据自己的实际请求地址改就行了
params = {
'leftTicketDTO.train_date': '2019-01-09',
'leftTicketDTO.from_station': 'CDW',
'leftTicketDTO.to_station': 'NCW',
'purpose_codes': 'ADULT'
}
res = self.session.get(url, params=params)
print(res.text)
if __name__ == '__main__':
spider = Spider()
spider.show_img() # 获取并显示验证码图片
spider.captcha_check() # 检测验证码
spider.login() # 账号密码登录
spider.query_ticket() # 查询车票
运行代码,从打印结果可以看出我们可以成功查询到车票信息,只是需要把这些车票信息进行处理。
处理并显示车票信息
在网页中找几个关键的车次信息,比如我找有一个车次的一等座有12张票,和响应的车次信息对比,可以看到车次的信息就是从这些响应里面取出来的。
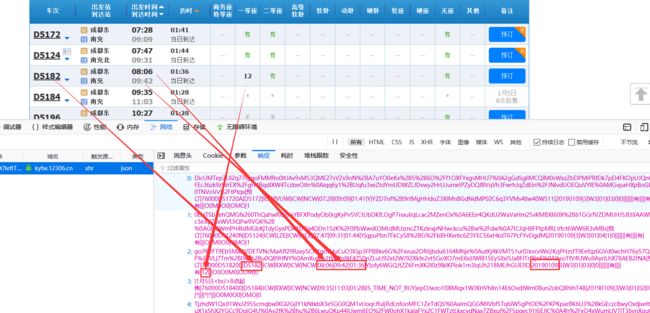
这些信息以‘|’作为分割,并且车次的信息都是在相同的位置。我们用Python的split分割,得到一个列表,比如车次:D5124这个是在列表中索引为4的位置,那么其他车次的名字也是在这个索引位置。下面是我分析出来的部分索引位置和对应的车次信息 ,25和32好像都表示商务座特等座,你们可以再找一下。(有可能我找错了,因为我没有全部进行实验):

接下来我们就通过Python来打印查询出来的车次信息:
# 查询车票
def query_ticket(self):
url = 'https://kyfw.12306.cn/otn/leftTicket/queryX'
params = {
'leftTicketDTO.train_date': '2019-01-09',
'leftTicketDTO.from_station': 'CDW',
'leftTicketDTO.to_station': 'NCW',
'purpose_codes': 'ADULT'
}
res = self.session.get(url, params=params)
# 打印我们需要的信息
for train in res.json()['data']['result']:
train_items = train.split('|')
print(train_items[3], train_items[6] + train_items[7], train_items[8] + train_items[9],
train_items[10], train_items[25] or train_items[32], train_items[31], train_items[30], # 25和32好像都表示特等座,所以我们都写上去
train_items[21], train_items[23], train_items[27], train_items[28],
train_items[24], train_items[29], train_items[26], train_items[22],
train_items[1])
部分打印结果:
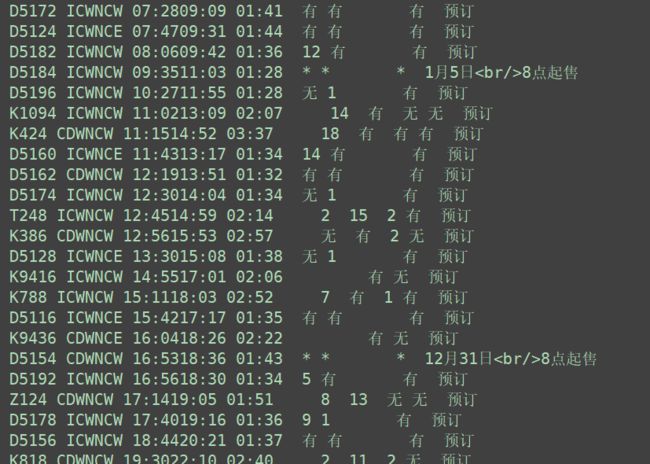
可以看到打印出屋面需要的信息了,但是格式不好看啊。你可以自己使用format进行调整,我这里使用第三方库:prettytable和colorama来显示查询结果,安装就不用说了吧,Python安装第三方库就那几种方法。如果有大佬能做出UI界面来显示也可以,我用Python的tkinter做过,发现tkinter的界面效果是真的差,做了一部分就放弃了。
首先我们先创建一个格式化的类,方便调用。
# 格式打印类
class FormatPrint:
def __init__(self):
colorama.init() # 初始化
@staticmethod
def red(s):
return colorama.Fore.RED + s + colorama.Fore.RESET # Fore.RED把打印的内容颜色设为红色,Fore.RESET:清空颜色设置
@staticmethod
def green(s):
return colorama.Fore.GREEN + s + colorama.Fore.RESET
@staticmethod
def print(columns_name, rows):
"""
:param rows: 需要打印的所有列名
:param columns_name: 需要打印的所有行,以二维列表形式传入
"""
table = PrettyTable(columns_name) # 用存储了列的名字的列表创建一个PrettyTable对象
for row in rows:
table.add_row(row) # 向PrettyTable对象中添加行
print(table) # 打印PrettyTable
然后更改query_ticket方法里面打印的代码,用我们创建的格式化打印类来打印我们查询出来的车票信息。
def __init__(self):
self.session = requests.session() # 获取会话这个对象, 只需要在请求时把requests换成self.session就可以了
self.points = [] # 储存点击点的坐标
# 我们需要打印车次信息的列名
self.train_column_name = ['序号', '车次', '出发/到达站', '出发/到达时间', '历时', '商务座/特等座', '一等座', '二等座', '高级软卧', '软卧', '动卧',
'硬卧', '软座', '硬座', '无座', '其他', '备注']
# 查询车票
def query_ticket(self):
url = 'https://kyfw.12306.cn/otn/leftTicket/queryX'
params = {
'leftTicketDTO.train_date': '2019-01-09',
'leftTicketDTO.from_station': 'CDW',
'leftTicketDTO.to_station': 'NCW',
'purpose_codes': 'ADULT'
}
res = self.session.get(url, params=params)
train_list = [['--' if item == '' else item for item in train.split('|')] for train in
res.json()['data']['result']] # 列表生成式(可以用for循环写),分割车次信息以及把空的信息换成--
# 打印我们需要的信息
format_print = FormatPrint() # 实例一个我们写的格式化打印类
rows = [] # 存储打印的所有行
for train in train_list: # 添加行
rows.append([train_list.index(train) + 1, train[3],
format_print.green(train[6]) + '\n' + format_print.red(train[7]),
format_print.green(train[8]) + '\n' + format_print.red(train[9]), train[10],
train[25] or train[32], # 25和32好像都表示特等座,所以我们都写上去
train[31], train[30], train[21], train[23], train[27], train[28],
train[24], train[29], train[26], train[22],
format_print.green(train[1]) if train[1] == '预订' else format_print.green(train[1])])
format_print.print(self.train_column_name, rows) # 调用FormatPrint对象中的方法打印
if __name__ == '__main__':
spider = Spider()
spider.show_img() # 获取并显示验证码图片
spider.captcha_check() # 检测验证码
spider.login() # 账号密码登录
spider.query_ticket() # 查询车票
打印的部分结果(最好在命令行里面运行这个py文件,我用pycharm打印出的表格有点对不齐,可能是中文字符的原因):
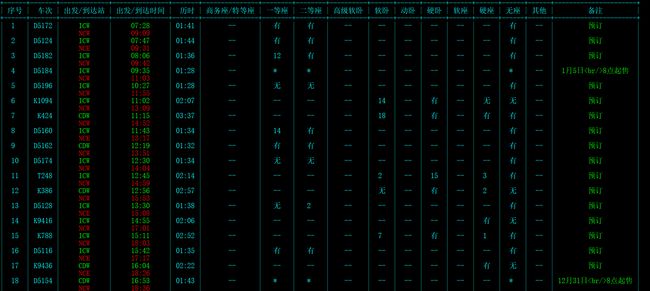
获取车站名信息及处理车站代号
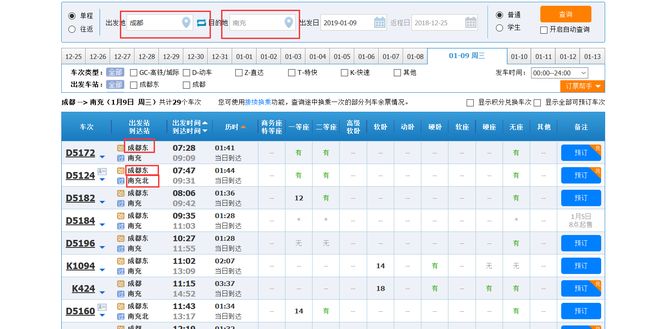
是不是比我们直接打印的好看很多?但是还有一个问题,就是出发站和到达站是以代号形式打印的,你可以直接换成你输入的出发站、到达站,但是从浏览器上可以看到实际的出发站和到达站是具体的车站名。并且在上面我们提到的查询车票时没有输入你需要查询的出发站和到达站,因为查询车票的请求参数也是以代号形式进行传递的。所以接下来我们就把车站代号换成车站的具体名称。
储存车站名字信息的这个请求在这里(在资源文件中是一个js文件,里面定义的一个变量):
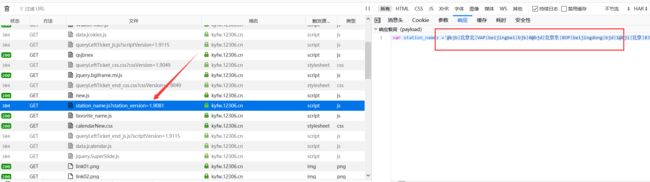
这里的车站名字是以‘@’进行分割,然后是以‘|’进行对每个车站名称的拼音首字母、中文名、代号、全拼等进行分割。
下面的方法是进行获取并处理车站名称,需要导入re模块。
def __init__(self):
self.session = requests.session() # 获取会话这个对象, 只需要在请求时把requests换成self.session就可以了
self.points = [] # 储存点击点的坐标
self.train_column_name = ['序号', '车次', '出发/到达站', '出发/到达时间', '历时', '商务座/特等座', '一等座', '二等座', '高级软卧', '软卧', '动卧',
'硬卧', '软座', '硬座', '无座', '其他', '备注']
self.chinese_code_swop = {} # 储存车站名和代号
self.train_list = [] # 存储查询出来了的车次
# 获取车站名称代号
def get_station_name(self):
url = 'https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.9081'
stations_name = self.session.get(url).text
result = re.findall(r'([\u4e00-\u9fa5]+)\|([A-Z]+)', stations_name) # 正则进行匹配,[\u4e00-\u9fa5]表示汉字
# 存入字典中
for chinese, code in result:
self.chinese_code_swop[chinese] = code # 把中文作为键,代号作为值
self.chinese_code_swop[code] = chinese # 把代号作为键,作为中文值
# 查询车票
def query_ticket(self):
from_station = input('输入出发站:')
to_station = input('输入到达站:')
train_date = input('输入出发日期(格式如:2019-01-09):')
url = 'https://kyfw.12306.cn/otn/leftTicket/queryX'
params = {
'leftTicketDTO.train_date': train_date,
'leftTicketDTO.from_station': self.chinese_code_swop[from_station],
'leftTicketDTO.to_station': self.chinese_code_swop[to_station],
'purpose_codes': 'ADULT'
}
res = self.session.get(url, params=params)
self.train_list = [['--' if item == '' else item for item in train.split('|')] for train in
res.json()['data']['result']] # 列表生成式(可以用for循环写),分割车次信息以及把空的信息换成--
# 打印我们需要的信息
format_print = FormatPrint() # 实例一个我们写的格式化打印类
rows = [] # 存储打印的所有行
for train in self.train_list: # 添加行
rows.append([self.train_list.index(train) + 1, train[3],
format_print.green(self.chinese_code_swop[train[6]]) + '\n' +
format_print.red(self.chinese_code_swop[train[7]]),
format_print.green(train[8]) + '\n' + format_print.red(train[9]), train[10],
train[25] or train[32], # 25和32好像都表示特等座,所以我们都写上去
train[31], train[30], train[21], train[23], train[27], train[28],
train[24], train[29], train[26], train[22],
format_print.green(train[1]) if train[1] == '预订' else format_print.red(train[1])])
format_print.print(self.train_column_name, rows) # 调用FormatPrint对象中的方法打印
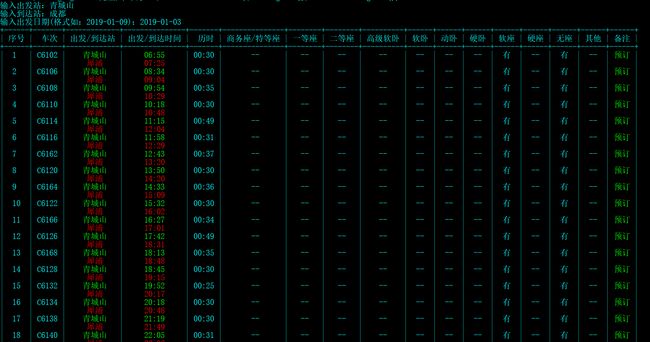
现在我们可以通过输入中文的车站名来查询车票信息了:
查询车票部分结束,贴出这部分的全部代码:
import requests
import base64
import numpy as np
from matplotlib import pyplot as plt
from PIL import Image
import io
import re
from prettytable import PrettyTable
import colorama
# 格式打印
class FormatPrint:
def __init__(self):
colorama.init() # 初始化
@staticmethod
def red(s):
return colorama.Fore.RED + s + colorama.Fore.RESET # Fore.RED把打印的内容颜色设为红色,Fore.RESET:清空颜色设置
@staticmethod
def green(s):
return colorama.Fore.GREEN + s + colorama.Fore.RESET
@staticmethod
def print(columns_name, rows):
"""
:param rows: 需要打印的所有列名
:param columns_name: 需要打印的所有行,以二维列表形式传入
"""
table = PrettyTable(columns_name)
for row in rows:
table.add_row(row)
print(table)
class Spider:
def __init__(self):
self.session = requests.session() # 获取会话这个对象, 只需要在请求时把requests换成self.session就可以了
self.points = [] # 储存点击点的坐标
self.train_column_name = ['序号', '车次', '出发/到达站', '出发/到达时间', '历时', '商务座/特等座', '一等座', '二等座', '高级软卧', '软卧', '动卧',
'硬卧', '软座', '硬座', '无座', '其他', '备注']
self.chinese_code_swop = {} # 储存车站名和代号
self.train_list = [] # 存储查询出来了的车次
# self.train_rows = [] # 储存打印车次表全部行信息
# self.passenger_column_name = ['序号', '姓名', '身份证', '证件类型', '乘客类型', '电话号码']
# 获取一张验证码图片
def get_captcha(self):
url = 'https://kyfw.12306.cn/passport/captcha/captcha-image64' # 我发现后面的参数不写也能够获取,那我们就不写吧
res = self.session.get(url) # 换成self.session,下面的也一样
return io.BytesIO(base64.b64decode(res.json()['image'])) # BytesIO把图片字节存入内存,使Image.open可以像文件一样操作它
# 显示验证码图片
def show_img(self):
o_img = Image.open(self.get_captcha())
np_img = np.array(o_img) # 把这个图片GRB转为矩阵(和多维列表差不多)
plt.imshow(np_img)
plt.gcf().canvas.mpl_connect('button_press_event', self.mouse_press)
plt.show()
# 鼠标按下
def mouse_press(self, event):
x = event.xdata # 在图片中点击的x坐标
y = event.ydata # 在图片中大奖的y坐标
if y < 40: # 如果点击图片上面的提示部分就直接返回
return
self.points.append([int(x), int(y)]) # 添加到全局的变量中
plt.scatter([x for x, y in self.points], [y for x, y in self.points], c='r', s=100,
marker=(5, 1, 0)) # 画散点图,第一个参数是横坐标,第二个是纵坐标,c是颜色,s是大小,marker是形状
plt.gcf().canvas.draw() # 重新绘制
# 检测验证码图片
def captcha_check(self):
url = 'https://kyfw.12306.cn/passport/captcha/captcha-check'
answer = ','.join([str(x) + ',' + str(y - 40) for x, y in self.points]) # 转为需要传递的参数格式(y-40是把提示部分的高度减掉)
params = {
# 'callback': 'jQuery19104534505650716114_1545106279315',
'answer': answer,
'rand': 'sjrand',
'login_site': 'E',
'_': '1545106279318'
}
res = self.session.get(url, params=params) # 在请求检测验证码图片时,给请求头加上全局变量中的cookies
print(res.text)
# 登录
def login(self):
url = 'https://kyfw.12306.cn/passport/web/login'
data = {
'username': '你的账号',
'password': '你的密码',
'appid': 'otn',
# 'answer': '43,115,258,107' # 这里可以不用写这个参数,以前版本的12306也没有这个参数,允也许现在没有对它进行验证吧
}
res = self.session.post(url, data=data)
print('登录:', res.text)
url = 'https://kyfw.12306.cn/passport/web/auth/uamtk'
data = {
'appid': 'otn'
}
res = self.session.post(url, data=data)
print('认证:', res.text)
url = 'https://kyfw.12306.cn/otn/uamauthclient'
data = {
'tk': res.json()['newapptk']
}
res = self.session.post(url, data)
print('种植tk:', res.text)
self.init_my12306()
# 查看是否有自己的名字
def init_my12306(self):
url = 'https://kyfw.12306.cn/otn/index/initMy12306Api'
res = self.session.get(url)
print(res.text)
# 获取车站名称代号
def get_station_name(self):
url = 'https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.9081'
stations_name = self.session.get(url).text
result = re.findall(r'([\u4e00-\u9fa5]+)\|([A-Z]+)', stations_name) # 正则进行匹配,[\u4e00-\u9fa5]表示汉字
# 存入字典中
for chinese, code in result:
self.chinese_code_swop[chinese] = code # 把中文作为键,代号作为值
self.chinese_code_swop[code] = chinese # 把代号作为键,作为中文值
# 查询车票
def query_ticket(self):
from_station = input('输入出发站:')
to_station = input('输入到达站:')
train_date = input('输入出发日期(格式如:2019-01-09):')
url = 'https://kyfw.12306.cn/otn/leftTicket/queryX'
params = {
'leftTicketDTO.train_date': train_date,
'leftTicketDTO.from_station': self.chinese_code_swop[from_station],
'leftTicketDTO.to_station': self.chinese_code_swop[to_station],
'purpose_codes': 'ADULT'
}
res = self.session.get(url, params=params)
self.train_list = [['--' if item == '' else item for item in train.split('|')] for train in
res.json()['data']['result']] # 列表生成式(可以用for循环写),分割车次信息以及把空的信息换成--
# 打印我们需要的信息
format_print = FormatPrint() # 实例一个我们写的格式化打印类
rows = [] # 存储打印的所有行
for train in self.train_list: # 添加行
rows.append([self.train_list.index(train) + 1, train[3],
format_print.green(self.chinese_code_swop[train[6]]) + '\n' +
format_print.red(self.chinese_code_swop[train[7]]),
format_print.green(train[8]) + '\n' + format_print.red(train[9]), train[10],
train[25] or train[32], # 25和32好像都表示特等座,所以我们都写上去
train[31], train[30], train[21], train[23], train[27], train[28],
train[24], train[29], train[26], train[22],
format_print.green(train[1]) if train[1] == '预订' else format_print.red(train[1])])
format_print.print(self.train_column_name, rows) # 调用FormatPrint对象中的方法打印
if __name__ == '__main__':
spider = Spider()
spider.show_img() # 获取并显示验证码图片
spider.captcha_check() # 检测验证码
spider.login() # 账号密码登录
spider.get_station_name() # 获取车站名称信息
spider.query_ticket() # 查询车票
三、下单部分
终于来到了最重要的环节了,能看我吹到这里来的人应该没几个了吧。

选择需要购买的车次
我们已经查询出自己想要买的出发站、到达站等车次信息了,然后就是按照在浏览器上购票的步骤,选择一个自己要乘坐的车次,点击预定。
下面的方法就是选择车次的,很简单,就是输入一个序号,打印出来就可以了。
# 选择车次
def select_train(self):
num = int(input('请输入预订车次序号:'))
self.book_train = self.train_list[num - 1]
print('你选择的是:')
format_print = FormatPrint() # 实例一个我们写的格式化打印类
select_row = [num, self.book_train[3],
format_print.green(self.chinese_code_swop[self.book_train[6]]) + '\n' +
format_print.red(self.chinese_code_swop[self.book_train[7]]),
format_print.green(self.book_train[8]) + '\n' + format_print.red(self.book_train[9]),
self.book_train[10], self.book_train[25] or self.book_train[32],
self.book_train[31], self.book_train[30], self.book_train[21],
self.book_train[23], self.book_train[27], self.book_train[28],
self.book_train[24], self.book_train[29], self.book_train[26],
self.book_train[22],
format_print.green(self.book_train[1]) if self.book_train[1] == '预订'
else format_print.red(self.book_train[1])]
format_print.print(self.train_column_name, [select_row]) # 注意行信息是传入二维列表
打印结果:

检测用户是否登录及检测是否有未完成订单
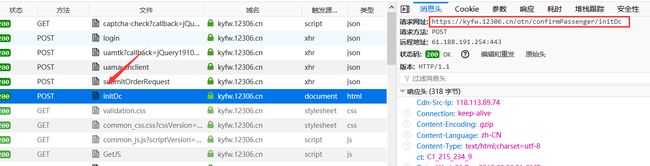
打开开发者工具,点击预定按钮,来到选择乘客信息和座位等信息。查看捕获的请求,在发送初始化界面请求:https://kyfw.12306.cn/otn/confirmPassenger/initDc,之前还有两个请求,checkUser:是检测用户是否登录,submitOrderRequest:检测是否含有未完成订单。所以在进入填写乘客信息等页面之前,要先请求这两个请求。
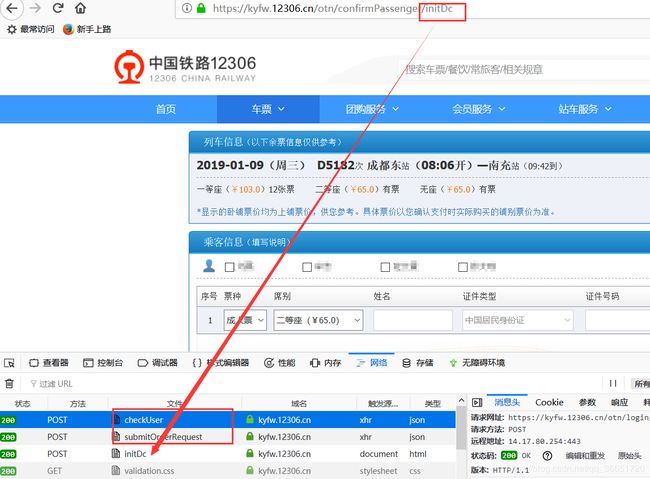
检测用户是否登录:
# 检测用户是否登录
def check_user(self):
url = 'https://kyfw.12306.cn/otn/login/checkUser'
data = {
'_json_att': ''
}
res = self.session.post(url, data)
print(res.text)
提交预定车次的信息,这里第一个参数secretStr是我们上面查询车票的第一个我把它叫成密文的那个参数,但是它是进行过url编码的,就是把‘+’、‘/’等进行了编码,在请求时不需要编码的,所以需要把它们换成原来的,你可以用replace、正则等进行替换,或者导入urllib中的parse模块。还有就是需要出发站、到达站、出发日期,我在__init__方法中定义了这几个属性,我就不在下面代码中写了。
# 提交预定的车次信息
def submit_order(self):
url = 'https://kyfw.12306.cn/otn/leftTicket/submitOrderRequest'
data = {
# 使用replace替换
# 'secretStr': self.__book_train[0].replace('%2B', '+').replace('%2F', '/').replace('%0A', '\n'),
'secretStr': parse.unquote(self.book_train[0]), # 直接进行解码
'train_date': self.train_date,
'back_train_date': self.train_date, # 返程日期不重要,我们购买的是单程车票
'tour_flag': 'dc', # 单程
'purpose_codes': 'ADULT',
'query_from_station_name': self.from_station,
'query_to_station_name': self.to_station,
'undefined': ''
}
res = self.session.post(url, data)
print(res.text)
运行结果,从里面对比官网的请求结果,如果是一样的应该就是成功了的。
 如果你还有未完成的订单,打印的结果会是下面这种。
如果你还有未完成的订单,打印的结果会是下面这种。
![]()
填写购票信息
上面两个请求之后就是进入填写购票信息的界面,爬虫是什么?就是模拟请求啊。在这个界面中进行了乘车人、票种、座位类型等进行了选择,我们主要进行乘车人和座位类型进行选择,票种我就选择成人票。如果需要对进行票种选择的,也可以在购票时把票种的类型改为对应的票种,但是票种也用的代号表示,代号在passengerInfo_js.js源文件中定义的变量,需要的话就去找一下。我截出了部分名称映射关系,在后面的检测订单请求中也可以参考一下。

下面是证件和对应的代号,在initDc中定义的一个json字符串,下面是用json格式化工具格式化了的,只截取了两个,我们一般就是用身份证买票的,需要的话可以去找,我就不细说了。(不会找的评论给我吧,有机会再写一篇通过分析js源代码来爬12306的,现在时间不多了,要到交作业的时间了,写这个博客写了十几天了)。


选择乘客
要选择乘车人,就要获取乘车人信息。如果打印了该界面的响应可以进行搜索你的乘车人的名字,可以发现是搜索不到的,还是和上面进入个人中心的一样,是用的ajax请求。这个请求的地址在请求列表中可以看到。
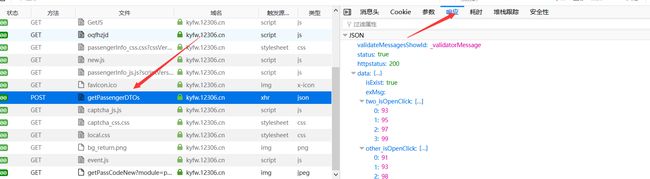
在python中请求这个网址:https://kyfw.12306.cn/otn/confirmPassenger/getPassengerDTOs,然后把响应的结果进行处理,格式化打印出所有的乘客信息,进行选择。下面代码需要的一些属性我也在__init__方法里面定义了,__init__部分的代码就不贴出来了,应该都会吧,不会的可以参考最后面的全部代码。
# 获取全部的乘客信息
def get_passengers(self):
url = 'https://kyfw.12306.cn/otn/confirmPassenger/getPassengerDTOs'
res = self.session.post(url)
self.passenger_list = res.json()['data']['normal_passengers']
format_print = FormatPrint()
passenger_rows = []
for passenger in self.passenger_list:
passenger_rows.append([passenger['code'], passenger['passenger_name'],
passenger['passenger_id_type_name'], passenger['passenger_id_no'],
passenger['passenger_type_name'], passenger['mobile_no']])
format_print.print(self.passenger_column_name, passenger_rows)
# 选择乘车乘客
def select_passenger(self):
num = int(input('输入序号,选择乘车人:'))
self.selected_passenger = self.passenger_list[num - 1]
# 和选择的车次一样,也进行打印一下选择的乘客信息
format_print = FormatPrint()
passenger_rows = [self.selected_passenger['code'], self.selected_passenger['passenger_name'],
self.selected_passenger['passenger_id_type_name'],
self.selected_passenger['passenger_id_no'],
self.selected_passenger['passenger_type_name'],
self.selected_passenger['mobile_no']]
print('你选择的乘客信息:')
format_print.print(self.passenger_column_name, [passenger_rows])
if __name__ == '__main__':
spider = Spider()
spider.show_img() # 获取并显示验证码图片
spider.captcha_check() # 检测验证码
spider.login() # 账号密码登录
spider.get_station_name() # 获取车站名称信息
spider.query_ticket() # 查询车票
spider.select_train() # 选择需要预定的车次
spider.check_user() # 检测用户是否登录
spider.submit_order() # 提交预定的车次信息
spider.get_passengers() # 获取该账户的全部乘客
spider.select_passenger() # 选择乘车乘客
部分打印结果:

选择座位
乘车人选择好了下面就是选择座位类型,我就直接把选择的车次信息打印出来,如果显示为:–的就表示该车次没有这类型的座位或者该类型的座位已经没有余票了。当然,需要完善的可以把还有余票的座位类型筛选出了,让使用者进行选择。
# 选择座位类型
def select_seat(self):
format_print = FormatPrint() # 实例一个我们写的格式化打印类
select_row = [self.train_list.index(self.selected_train), self.selected_train[3],
format_print.green(self.chinese_code_swop[self.selected_train[6]]) + '\n' +
format_print.red(self.chinese_code_swop[self.selected_train[7]]),
format_print.green(self.selected_train[8]) + '\n' + format_print.red(self.selected_train[9]),
self.selected_train[10], self.selected_train[25] or self.selected_train[32],
self.selected_train[31], self.selected_train[30], self.selected_train[21],
self.selected_train[23], self.selected_train[27], self.selected_train[28],
self.selected_train[24], self.selected_train[29], self.selected_train[26],
self.selected_train[22],
format_print.green(self.selected_train[1]) if self.selected_train[1] == '预订'
else format_print.red(self.selected_train[1])]
format_print.print(self.train_column_name, [select_row]) # 注意行信息是传入二维列表
self.selected_seat = self.seat_dict[input('请输入还有余票的车座类型:')]
提交订单
终于!终于来到了爬取12306的最后步骤了——提交订单!
在浏览器上我们,选择了乘车人和座位类型等信息,就可以点击提交订单了。记住一定一定要打开开发者工具,因为12306,每天只能取消三次订单,晚上11点也不能进行登录购票,也许这两个也是阻止我爬取12306的进度的原因吧,因为分析一些不知道的请求参数要进行多次不同的请求进行对比来发现这些参数代表什么。废话不多说,下面开始进入最后的步骤——提交订单。
再次提示:记住打开开发者工具,点击提交订单按钮,弹出一个核对订单信息及选座的小弹框,我们也不进行选座了,需要的自己实现吧。可以看到有两个主要的请求,checkOrderInfo:检测订单信息以及getQueueCount:获取余票信息。
我们只进行检测订单信息,获取余票的请求只是请求这个车次的已有的座位类型还剩余多少票,如果要获取余票的也可以自己获取(时间真的不多了,要交作业了)。

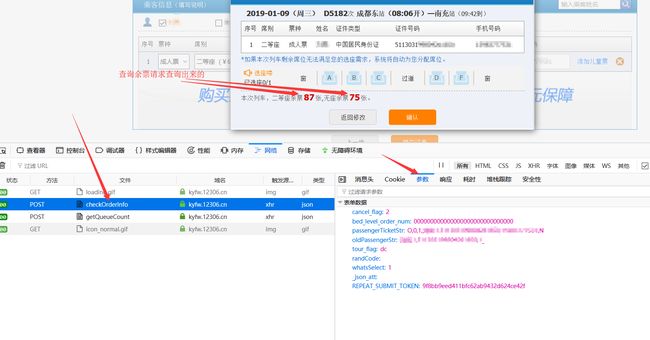
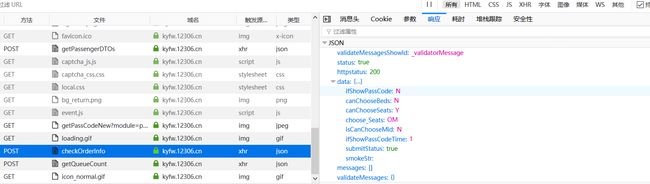
检测订单信息
下面我们分析检测订单请求:
检测订单请求中的参数主要是:passengerTicketStr、oldPassengerStr、tour_flag、REPEAT_SUBMIT_TOKEN,其他几个参数基本上是不变的,能看懂js的找到passengerInfo_js.js文件,在1493行插入断点,进行调试可以看出参数是怎么来的。这里我把这个请求的js源代码中截图了,不会的也不要紧,我后面会解释参数大概由什么组成。
会一点js的看下面的图:
下面图片中的说的函数也能在源代码中找到:
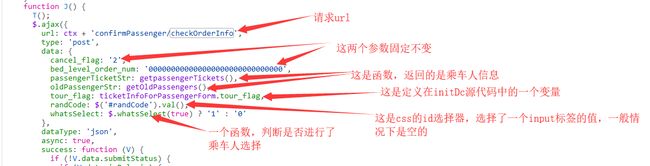 ranCode的值是空的:
ranCode的值是空的:

不会的看我给你们吹说:
passengerTicketStr:车座类型代号 + ',0,' + 车票类型代号(一般都是成人票:1) + ',' + 乘客姓名 + ',' + 证件类型代号 + ',' + 证件号 + ',' + 如果有电话号码这就是电话号码 + ',' + 是否保存的意思(一般为N)。
上面就是买单张票的参数组成,多人的加一个:‘__’ 下划线作为分割,后面再接上其他乘车人的信息就是了,我这里就不具体操作了,因为我们买的就是单张的票。
oldPassengerStr:乘客姓名+ ',' + 证件类型代号 + ',' + 证件号 + ',' + 乘客类型(成人、儿童什么的)。
tour_flag:在initDc这个响应里面的一个变量中的值,如果不知道可以直接写:dc,代表单程。

REPEAT_SUBMIT_TOKEN:也是initDc中定义的一个变量。
![]()
上面参数如果看不懂没关系,先跟着把代码写好,成功买一张票之后再来仔细分析,如果吧啦吧啦告诉你一大堆乱七八糟的东西,最后还买不了票肯定就想砸电脑了。
首先我们先来获取REPEAT_SUBMIT_TOKEN这个参数,你直接在initDc响应中的第12行就可以看到。
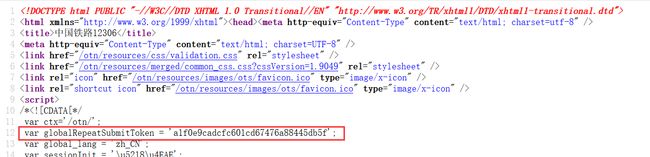
以及在后面买票的请求中的key_check_isChange参数我们也一并获取了吧,它是和其他信息存入一个json字符串中的,我们就不获取这个json字符串再把它转为json对象了,直接用正则匹配出这个参数就可以了。(其实里面还有leftTicketStr、train_location、tour_flag等参数,但是这些参数可以从我们在查询车票的那一串以‘|’分割的字符串就有)。
接下来就请求填写乘车人信息的这个界面的源代码。https://kyfw.12306.cn/otn/confirmPassenger/initDc
self.token、self.key以及下面的self.oldPassengerStr、self.passengerTicketStr都是定义在__init__中的空字符串,相信大佬们都应该猜得到吧,就是为了方便在不同地方使用这些变量。
下面是获取这两个参数的代码:
# 获取REPEAT_SUBMIT_TOKEN和key_check_isChange
def get_token_key(self):
url = 'https://kyfw.12306.cn/otn/confirmPassenger/initDc'
data = {
'_json_att': ''
}
res = self.session.post(url, data)
result = re.search(r"globalRepeatSubmitToken = '(.+?)'.*?key_check_isChange':'(.+?)'", res.text, re.S)
self.token = result.group(1)
self.key = result.group(2)
print(self.token, self.key)
还有就是oldPassengerStr和passengerTicketStr两个参数了,这两个参数就是一些乘车人信息和车票信息拼接的,所以我们直接在检测订单请求的代码中进行拼接就可以了。
# 检测订单
def check_order(self):
# 下面这两个没什么好说的,就是拼接字符串,以‘,’隔开
self.oldPassengerStr = ','.join([self.selected_passenger['passenger_name'],
self.selected_passenger['passenger_id_type_code'] +
self.selected_passenger['passenger_id_no'],
self.selected_passenger['passenger_type'] + "_"]) # 直接用乘车人信息进行拼接
self.passengerTicketStr = ','.join((self.seat_map[self.selected_seat_name], '0', '1',
self.selected_passenger['passenger_name'],
self.selected_passenger['passenger_id_type_code'],
self.selected_passenger['passenger_id_no'],
self.selected_passenger['mobile_no'], 'N')) # 0是固定不变的,我们就买成人票,所以有一个1,代表成人票,如果不要成人票可以去上面我截了部分名称和代号映射关系进行改写,或者就用乘车人类型也可以,因为它们的对应的代号都是一样的,最后一个是保存状态:N
url = 'https://kyfw.12306.cn/otn/confirmPassenger/checkOrderInfo'
data = {
'_json_att': '', # 空的
'bed_level_order_num': '000000000000000000000000000000', # 不变的
'cancel_flag': '2', # 不变的
'oldPassengerStr': self.oldPassengerStr,
'passengerTicketStr': self.passengerTicketStr,
'randCode': '', # 空的
'REPEAT_SUBMIT_TOKEN': self.token, # 在initDc响应中
'tour_flag': 'dc', # 我们这里就直接写dc,可以从initDc中获取
'whatsSelect': '1', # 是否选择了乘车人
}
res = self.session.post(url, data)
print(res.text)
把打印的结果和浏览器中响应的进行对比,如果一样说明你成功了,如果有问题就检查一下参数是否正确吧。
请求火车票
最后一个请求了!
我这里就直接告诉请求火车票的地址了,避免浪费一次取消订单的机会,https://kyfw.12306.cn/otn/confirmPassenger/confirmSingleForQueue,也可以自己提交一次订单,就可以找到这个地址了。
打开这个请求,找到请求参数(你自己打开吧,我就不截图了,前面都查看这么多次请求了,都最后一个请求了,都会找了吧),它的参数在源代码中是这样的,和上面检测订单请求的参数基本上都是差不多的,有几个一般也是固定的,我在代码中就写出基本上不会变的,其他的都可以从选择的车次(self.selected_train)信息中找到。

# 确认订单,请求车票
def confirm_order(self):
url = 'https://kyfw.12306.cn/otn/confirmPassenger/confirmSingleForQueue'
data = {
'_json_att': '',
'choose_seats': '',
'dwAll': 'N',
'key_check_isChange': self.key,
'leftTicketStr': self.selected_train[12],
'oldPassengerStr': self.oldPassengerStr,
'passengerTicketStr': self.passengerTicketStr,
'purpose_codes': '00',
'randCode': '',
'REPEAT_SUBMIT_TOKEN': self.token,
'roomType': '00',
'seatDetailType': '000',
'train_location': self.selected_train[15],
'whatsSelect': '1'
}
res = self.session.post(url, data)
print(res.text)
开始运行,如果这个请求响应的结果和下面打印一样,那么恭喜你看这个博客大概看了35000个字
恭喜你,订票成功,现在只需要在30分钟内去订单界面进行付款就行。
![]()
这个博客到这就差不多写完了,也是我的第一篇博客,怎么样?看完了是不是脑壳有点痛?当然,如果能顺利的预订车票,还是很开心的。我只写了能实现预订车票功能的代码,相信跟着写的人已经看出了有很多需要改进的地方,比如没有进行异常处理啊、在获取验证码图片失败时没有进行再次获取或者提示信息啊、在输入出发站、到达站等必须一次性输入正确啊、如果查询处理的车票信息为空应该显示该车次为空等等问题。如果仔细看了的,就可以发现我越到后面写得越简略,因为到了要交作业的时间了。期末了,每个老师都喊写各种项目,忙不过来了(你猜这是不是借口)。以后想起再改进吧,到时候又是猴年马月的事了,哈哈哈。还有抢票功能我还没有实验过,所以就不写了,思路很简单,就是不断进行查票请求,如果你想要买的车票从没有变为了有就立即下单就行了。如果这篇有一些写错了的希望大佬们指出;如果看完这篇博客觉得头痛欲裂的想打我的,我还是那句话:顺着网线来啊!
全部代码
import requests
import base64
import numpy as np
from matplotlib import pyplot as plt
from PIL import Image
import io
import re
from prettytable import PrettyTable
import colorama
from urllib import parse
# 格式打印
class FormatPrint:
def __init__(self):
colorama.init() # 初始化
@staticmethod
def red(s):
return colorama.Fore.RED + s + colorama.Fore.RESET # Fore.RED把打印的内容颜色设为红色,Fore.RESET:清空颜色设置
@staticmethod
def green(s):
return colorama.Fore.GREEN + s + colorama.Fore.RESET
@staticmethod
def yellow(s):
return colorama.Fore.YELLOW + s + colorama.Fore.RESET
@staticmethod
def print(columns_name, rows):
"""
:param rows: 需要打印的所有列名
:param columns_name: 需要打印的所有行,以二维列表形式传入
"""
table = PrettyTable(columns_name)
for row in rows:
table.add_row(row)
print(table)
class Spider:
def __init__(self):
self.session = requests.session() # 获取会话这个对象, 只需要在请求时把requests换成self.session就可以了
self.points = [] # 储存点击点的坐标
self.from_station = None # 出发站
self.to_station = None # 到达站
self.train_date = None # 出发日期
self.train_column_name = ['序号', '车次', '出发/到达站', '出发/到达时间', '历时', '商务座/特等座',
'一等座', '二等座', '高级软卧', '软卧', '动卧', '硬卧', '软座', '硬座',
'无座', '其他', '备注']
self.chinese_code_swop = {} # 储存车站名和代号
self.train_list = [] # 存储查询出来了的车次
self.passenger_list = [] # 存储获得出来的全部乘客
self.selected_train = None # 准备预定车票的车次
self.selected_passenger = None # 选择的乘车乘客
self.selected_seat_name = None # 选择的座位类型
self.token = '' # 在检测订单时需要的参数
self.key = '' # 在下单时需要的参数
self.oldPassengerStr = '' # 储存乘客信息
self.passengerTicketStr = ''
# 座位类型所对应的代号
self.seat_map = {
'商务座': '9',
'一等座': 'M',
'二等座': 'O',
'高级软卧': '6',
'软卧': '4',
'硬卧': '3',
'软座': '2',
'硬座': '1',
'动卧': 'F'
}
self.passenger_column_name = ['序号', '姓名', '身份证', '证件类型', '乘客类型', '电话号码']
# 获取一张验证码图片
def get_captcha(self):
url = 'https://kyfw.12306.cn/passport/captcha/captcha-image64' # 我发现后面的参数不写也能够获取,那我们就不写吧
res = self.session.get(url) # 换成self.session,下面的也一样
return io.BytesIO(base64.b64decode(res.json()['image'])) # BytesIO把图片字节存入内存,使Image.open可以像文件一样操作它
# 显示验证码图片
def show_img(self):
o_img = Image.open(self.get_captcha())
np_img = np.array(o_img) # 把这个图片GRB转为矩阵(和多维列表差不多)
plt.imshow(np_img)
plt.gcf().canvas.mpl_connect('button_press_event', self.mouse_press)
plt.show()
# 鼠标按下
def mouse_press(self, event):
x = event.xdata # 在图片中点击的x坐标
y = event.ydata # 在图片中大奖的y坐标
if y < 40: # 如果点击图片上面的提示部分就直接返回
return
self.points.append([int(x), int(y)]) # 添加到全局的变量中
plt.scatter([x for x, y in self.points], [y for x, y in self.points], c='r', s=100,
marker=(5, 1, 0)) # 画散点图,第一个参数是横坐标,第二个是纵坐标,c是颜色,s是大小,marker是形状
plt.gcf().canvas.draw() # 重新绘制
# 检测验证码图片
def captcha_check(self):
url = 'https://kyfw.12306.cn/passport/captcha/captcha-check'
answer = ','.join([str(x) + ',' + str(y - 40) for x, y in self.points]) # 转为需要传递的参数格式(y-40是把提示部分的高度减掉)
params = {
# 'callback': 'jQuery19104534505650716114_1545106279315',
'answer': answer,
'rand': 'sjrand',
'login_site': 'E',
'_': '1545106279318'
}
res = self.session.get(url, params=params) # 在请求检测验证码图片时,给请求头加上全局变量中的cookies
print(res.text)
# 登录
def login(self):
url = 'https://kyfw.12306.cn/passport/web/login'
data = {
'username': '你的账号',
'password': '你的密码',
'appid': 'otn',
# 'answer': '43,115,258,107' # 这里可以不用写这个参数,以前版本的12306也没有这个参数,允也许现在没有对它进行验证吧
}
res = self.session.post(url, data=data)
print('登录:', res.text)
url = 'https://kyfw.12306.cn/passport/web/auth/uamtk'
data = {
'appid': 'otn'
}
res = self.session.post(url, data=data)
print('认证:', res.text)
url = 'https://kyfw.12306.cn/otn/uamauthclient'
data = {
'tk': res.json()['newapptk']
}
res = self.session.post(url, data)
print('种植tk:', res.text)
self.init_my12306()
# 查看是否有自己的名字
def init_my12306(self):
url = 'https://kyfw.12306.cn/otn/index/initMy12306Api'
res = self.session.get(url)
print(res.text)
# 获取车站名称代号
def get_station_name(self):
url = 'https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.9081'
stations_name = self.session.get(url).text
result = re.findall(r'([\u4e00-\u9fa5]+)\|([A-Z]+)', stations_name) # 正则进行匹配,[\u4e00-\u9fa5]表示汉字
# 存入字典中
for chinese, code in result:
self.chinese_code_swop[chinese] = code # 把中文作为键,代号作为值
self.chinese_code_swop[code] = chinese # 把代号作为键,作为中文值
# 查询车票
def query_ticket(self):
self.from_station = input('输入出发站:')
self.to_station = input('输入到达站:')
self.train_date = input('输入出发日期(格式如:2019-01-09):')
url = 'https://kyfw.12306.cn/otn/leftTicket/queryA'
params = {
'leftTicketDTO.train_date': self.train_date,
'leftTicketDTO.from_station': self.chinese_code_swop[self.from_station],
'leftTicketDTO.to_station': self.chinese_code_swop[self.to_station],
'purpose_codes': 'ADULT'
}
res = self.session.get(url, params=params)
print(res.text)
self.train_list = [['--' if item == '' else item for item in train.split('|')] for train in
res.json()['data']['result']] # 列表生成式(可以用for循环写),分割车次信息以及把空的信息换成--
# 打印我们需要的信息
format_print = FormatPrint() # 实例一个我们写的格式化打印类
rows = [] # 存储打印的所有行
for train in self.train_list: # 添加行
rows.append([self.train_list.index(train) + 1, train[3],
format_print.green(self.chinese_code_swop[train[6]]) + '\n' +
format_print.red(self.chinese_code_swop[train[7]]),
format_print.green(train[8]) + '\n' + format_print.red(train[9]), train[10],
train[25] or train[32], # 25和32好像都表示特等座,所以我们都写上去
train[31], train[30], train[21], train[23], train[27], train[28],
train[24], train[29], train[26], train[22],
format_print.green(train[1]) if train[1] == '预订' else format_print.red(train[1])])
format_print.print(self.train_column_name, rows) # 调用FormatPrint对象中的方法打印
# 选择车次
def select_train(self):
format_print = FormatPrint() # 实例一个我们写的格式化打印类
num = int(input('请输入预订车次序号:'))
self.selected_train = self.train_list[num - 1]
select_row = [num, self.selected_train[3],
format_print.green(self.chinese_code_swop[self.selected_train[6]]) + '\n' +
format_print.red(self.chinese_code_swop[self.selected_train[7]]),
format_print.green(self.selected_train[8]) + '\n' + format_print.red(self.selected_train[9]),
self.selected_train[10], self.selected_train[25] or self.selected_train[32],
self.selected_train[31], self.selected_train[30], self.selected_train[21],
self.selected_train[23], self.selected_train[27], self.selected_train[28],
self.selected_train[24], self.selected_train[29], self.selected_train[26],
self.selected_train[22],
format_print.green(self.selected_train[1]) if self.selected_train[1] == '预订'
else format_print.red(self.selected_train[1])]
print('你选择的是车次信息:')
format_print.print(self.train_column_name, [select_row]) # 注意行信息是传入二维列表
# 检测用户是否登录
def check_user(self):
url = 'https://kyfw.12306.cn/otn/login/checkUser'
data = {
'_json_att': ''
}
res = self.session.post(url, data)
print(res.text)
# 检测是否还有未完成订单
def submit_order(self):
url = 'https://kyfw.12306.cn/otn/leftTicket/submitOrderRequest'
data = {
# 使用replace替换
# 'secretStr': self.__selected_train[0].replace('%2B', '+').replace('%2F', '/').replace('%0A', '\n'),
'secretStr': parse.unquote(self.selected_train[0]), # 直接进行解码
'train_date': self.train_date,
'back_train_date': self.train_date, # 返程日期不重要,我们购买的是单程车票
'tour_flag': 'dc',
'purpose_codes': 'ADULT',
'query_from_station_name': self.from_station,
'query_to_station_name': self.to_station,
'undefined': ''
}
res = self.session.post(url, data)
print(res.text)
# 获取全部的乘客信息
def get_passengers(self):
url = 'https://kyfw.12306.cn/otn/confirmPassenger/getPassengerDTOs'
res = self.session.post(url)
self.passenger_list = res.json()['data']['normal_passengers']
format_print = FormatPrint()
passenger_rows = []
for passenger in self.passenger_list:
passenger_rows.append([passenger['code'], passenger['passenger_name'],
passenger['passenger_id_type_name'], passenger['passenger_id_no'],
passenger['passenger_type_name'], passenger['mobile_no']])
format_print.print(self.passenger_column_name, passenger_rows)
# 选择乘车乘客
def select_passenger(self):
num = int(input('输入序号,选择乘车人:'))
self.selected_passenger = self.passenger_list[num - 1]
# 和选择的车次一样,也进行打印一下选择的乘客信息
format_print = FormatPrint()
passenger_rows = [self.selected_passenger['code'], self.selected_passenger['passenger_name'],
self.selected_passenger['passenger_id_type_name'],
self.selected_passenger['passenger_id_no'],
self.selected_passenger['passenger_type_name'],
self.selected_passenger['mobile_no']]
print('你选择的乘客信息:')
format_print.print(self.passenger_column_name, [passenger_rows])
# 选择座位类型
def select_seat(self):
format_print = FormatPrint() # 实例一个我们写的格式化打印类
select_row = [self.train_list.index(self.selected_train), self.selected_train[3],
format_print.green(self.chinese_code_swop[self.selected_train[6]]) + '\n' +
format_print.red(self.chinese_code_swop[self.selected_train[7]]),
format_print.green(self.selected_train[8]) + '\n' + format_print.red(self.selected_train[9]),
self.selected_train[10], self.selected_train[25] or self.selected_train[32],
self.selected_train[31], self.selected_train[30], self.selected_train[21],
self.selected_train[23], self.selected_train[27], self.selected_train[28],
self.selected_train[24], self.selected_train[29], self.selected_train[26],
self.selected_train[22],
format_print.green(self.selected_train[1]) if self.selected_train[1] == '预订'
else format_print.red(self.selected_train[1])]
format_print.print(self.train_column_name, [select_row]) # 注意行信息是传入二维列表
self.selected_seat_name = input('请输入还有余票的车座类型:')
print('你选择的座位类型是:', self.selected_seat_name)
# 获取REPEAT_SUBMIT_TOKEN和key_check_isChange
def get_token_key(self):
url = 'https://kyfw.12306.cn/otn/confirmPassenger/initDc'
data = {
'_json_att': ''
}
res = self.session.post(url, data)
result = re.search(r"globalRepeatSubmitToken = '(.+?)'.*?key_check_isChange':'(.+?)'", res.text, re.S)
self.token = result.group(1)
self.key = result.group(2)
print(self.token, self.key)
# 检测订单
def check_order(self):
# 下面这两个没什么好说的,就是拼接字符串,以‘,’隔开
self.oldPassengerStr = ','.join([self.selected_passenger['passenger_name'],
self.selected_passenger['passenger_id_type_code'] +
self.selected_passenger['passenger_id_no'],
self.selected_passenger['passenger_type'] + "_"])
self.passengerTicketStr = ','.join([self.seat_map[self.selected_seat_name], '0', '1',
self.selected_passenger['passenger_name'],
self.selected_passenger['passenger_id_type_code'],
self.selected_passenger['passenger_id_no'],
self.selected_passenger['mobile_no'], 'N'])
url = 'https://kyfw.12306.cn/otn/confirmPassenger/checkOrderInfo'
data = {
'_json_att': '', # 空的
'bed_level_order_num': '000000000000000000000000000000', # 不变的
'cancel_flag': '2', # 不变的
'oldPassengerStr': self.oldPassengerStr,
'passengerTicketStr': self.passengerTicketStr,
'randCode': '', # 空的
'REPEAT_SUBMIT_TOKEN': self.token, # 在initDc响应中
'tour_flag': 'dc', # 我们这里就直接写dc,可以从initDc中获取
'whatsSelect': '1', # 是否选择了乘车人
}
res = self.session.post(url, data)
print('检查订单:', res.text)
# 确认订单,请求车票
def confirm_order(self):
url = 'https://kyfw.12306.cn/otn/confirmPassenger/confirmSingleForQueue'
data = {
'_json_att': '',
'choose_seats': '',
'dwAll': 'N',
'key_check_isChange': self.key,
'leftTicketStr': self.selected_train[12],
'oldPassengerStr': self.oldPassengerStr,
'passengerTicketStr': self.passengerTicketStr,
'purpose_codes': '00', # 这个参数是
'randCode': '',
'REPEAT_SUBMIT_TOKEN': self.token,
'roomType': '00',
'seatDetailType': '000',
'train_location': self.selected_train[15],
'whatsSelect': '1'
}
res = self.session.post(url, data)
print(res.text)
if __name__ == '__main__':
spider = Spider()
spider.show_img() # 获取并显示验证码图片
spider.captcha_check() # 检测验证码
spider.login() # 账号密码登录
spider.get_station_name() # 获取车站名称信息
spider.query_ticket() # 查询车票
spider.select_train() # 选择需要预定的车次
spider.check_user() # 检测用户是否登录
spider.submit_order() # # 检测是否还有未完成订单
spider.get_passengers() # 获取该账户的全部乘客
spider.select_passenger() # 选择乘车乘客
spider.select_seat() # 选择座位类型
spider.get_token_key() # 获取提交订单请求需要的参数
spider.check_order() # 检测订单信息
spider.confirm_order() # 确定订单