Self-Supervised Adversarial Hashing Networks for Cross-Modal Retrieval 整理笔记
Self-Supervised Adversarial Hashing Networks for Cross-Modal Retrieval
from CVPR 2018
abstract
本文采用2个对抗网络来影响不同模态之间的相关性,并将标签作为训练样本,放入生成器生成对应的语义来供其他网络学习。本文采用multi-label的形式来表述label与对象之间的关系(即一个对象可能有多个label)。
network and loss

本文为了说明结果,采用了图像模态和文本模态的双模态分类。网络结构如上图,其中包含了两个特征提取网络:图像特征提取网络ImgNet与文本特征提取网络TxtNet。以及用来将label用于语义生成的labNet,还有结合ImgNet与labNet输出的辨别器D1,和结合TxtNet输出与LabNet输出的辨别器D2。
network struct
网络结构采用了目前CMH常见的网络模型。
ImgNet采用CNN-F模型,将最后的全连接层改为hash输出层,结构如下
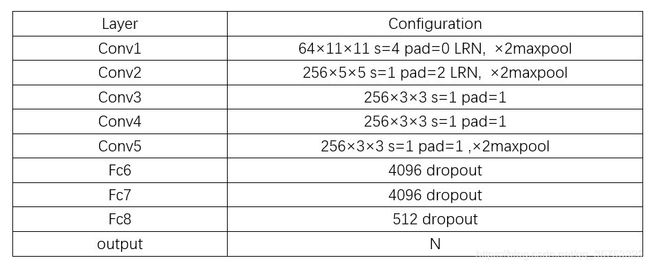
这里采用了其他论文中的描述,但与实际有些许不服,即最后fch8应为N,这里的N为hash code长度+分类标签个数,后续相同。
TxtNet使用了融合标签(MS),每一层MS由一个average pooling + 1×1的conv构成,结构如下
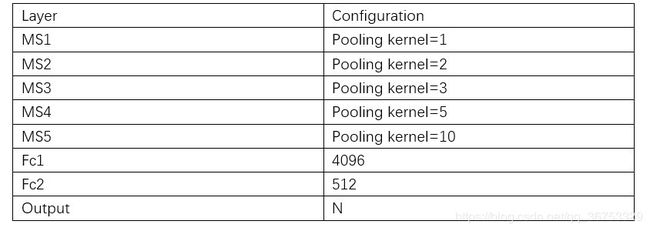
特征提取网络(ImgNet and TxtNet)均采用relu作为激活函数
LabNet采用全连接层的方式,即(label -> 4096 -> 512 -> N),采用sigmoid作为激活函数
对抗网络D(D1,D2相同)也是采用全连接层的方式,即(feature -> 4096 -> 4096 -> 1),采用tanh作为激活函数
loss
首先我们定义两个实例的相似度Si,j,由于是多标签情况,所以只要两个实例有一个共同的标签,即表示两个实例是相似的,Si,j=1,否之Si,j=0.
其次,labNet的输入标签我们称为inputLabel,输出的分类标签label,其中label的维度在1×N ,与inputLabel的表示含义及其维度不同
我 们 用 F l 表 示 L a b N e t 的 特 征 , F v 表 示 I m g N e t 输 出 的 特 征 , F t 表 示 T x t N e t 输 出 的 特 征 我们用F^l表示LabNet的特征,F^v表示ImgNet输出的特征,F^t表示TxtNet输出的特征 我们用Fl表示LabNet的特征,Fv表示ImgNet输出的特征,Ft表示TxtNet输出的特征
我 们 用 H l 表 示 L a b N e t 的 h a s h , H v 表 示 I m g N e t 输 出 的 h a s h , H t 表 示 T x t N e t 输 出 的 h a s h 我们用H^l表示LabNet的hash,H^v表示ImgNet输出的hash,H^t表示TxtNet输出的hash 我们用Hl表示LabNet的hash,Hv表示ImgNet输出的hash,Ht表示TxtNet输出的hash
对 于 h a s h 的 学 习 , 我 们 定 义 B v , t ∈ { − 1 , 1 } K , 这 里 K 为 h a s h 的 长 度 对于hash的学习,我们定义B^{v,t}\in\{-1, 1\}^K,这里K为hash的长度 对于hash的学习,我们定义Bv,t∈{−1,1}K,这里K为hash的长度
semantic generation loss

其 中 Δ i j l = 1 2 ( F ∗ i l ) T ( F ∗ j l ) , Γ i j l = 1 2 ( H ∗ i l ) T ( H ∗ j l ) , L ^ l 表 示 预 测 的 分 类 l a b e l 其中\Delta_{ij}^l=\frac{1}{2}(F_{*i}^l)^T(F_{*j}^l),\Gamma_{ij}^l=\frac{1}{2}(H_{*i}^l)^T(H_{*j}^l),\hat{L}^l表示预测的分类label 其中Δijl=21(F∗il)T(F∗jl),Γijl=21(H∗il)T(H∗jl),L^l表示预测的分类label
这 里 的 F l 为 l a b e l N e t 的 f c 2 层 的 输 出 结 果 , 即 F l ∈ R 1 × 512 这里的F^l为labelNet的fc2层的输出结果,即F^l\in R^{1\times 512} 这里的Fl为labelNet的fc2层的输出结果,即Fl∈R1×512
H l 为 l a b e l N e t 的 输 出 结 果 的 前 K 部 分 , 即 输 出 的 h a s h c o d e H^l为labelNet的输出结果的前K部分,即输出的hash~code Hl为labelNet的输出结果的前K部分,即输出的hash code
这里将该部分的loss分为4个部分,分别为J1相似实例间的语义loss,J2相似实例间的hashLoss,J3hash的学习loss,J4LabNet的分类loss。其中J1,J2为cross-modal的NLLloss定义。
feature loss
由于不同的模态采用不同的网络训练,所以我们用labNet生成的特征与两个网络中的特征进行相关联,这里并没有将输出进行融合,而是将接近输出层的全连接层的输出结果进行融合,这样既保证了特征的提取的有效性,又方便BP针对性的更新网络。

其 中 Δ i j l = 1 2 ( F ∗ i l ) T ( F ∗ j v ( t ) ) , Γ i j l = 1 2 ( H ∗ i l ) T ( H ∗ j v ( t ) ) , L ^ v ( t ) 表 示 特 征 网 络 预 测 的 分 类 l a b e l 其中\Delta_{ij}^l=\frac{1}{2}(F_{*i}^l)^T(F_{*j}^{v(t)}),\Gamma_{ij}^l=\frac{1}{2}(H_{*i}^l)^T(H_{*j}^{v(t)}),\hat{L}^{v(t)}表示特征网络预测的分类label 其中Δijl=21(F∗il)T(F∗jv(t)),Γijl=21(H∗il)T(H∗jv(t)),L^v(t)表示特征网络预测的分类label
这里的公式表示和上述相同,这里通过乘积将labNet的输出与特征提取网络的特征进行相关,利用labNet的自监督学习的结果作为可信的标签
adversarial loss
由于不同模态之间的间隔,我们通过labNet进行缩短间隔,那么用于缩短间隔的部分就是分辨网络D
我们定义两个实例的hash的Hamming距离为dis(bi,bj)=1/2(K-
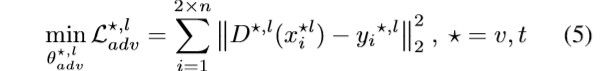 其 中 x i ⋆ , l 为 图 像 ( 文 本 ) 语 义 与 l a b N e t 语 义 的 共 同 语 义 特 征 其中x_i^{\star,l}为图像(文本)语义与labNet语义的共同语义特征 其中xi⋆,l为图像(文本)语义与labNet语义的共同语义特征
其 中 x i ⋆ , l 为 图 像 ( 文 本 ) 语 义 与 l a b N e t 语 义 的 共 同 语 义 特 征 其中x_i^{\star,l}为图像(文本)语义与labNet语义的共同语义特征 其中xi⋆,l为图像(文本)语义与labNet语义的共同语义特征
y i ⋆ , l = { 0 i f l a b e l s f o r i m a g e ( t e x t ) 1 i f l a b e l s f o r i n p u t L a b e l y_i^{\star,l}= \begin{cases}0 & if~labels~for~image(text) \\ 1 & if~labels ~ for ~inputLabel\end{cases} yi⋆,l={01if labels for image(text)if labels for inputLabel
这里对于每个D,使得D的输出接近于 真实的label的来源
optimization
本文中包含了3个hash code,但是为了训练,我们将三个hash code结合起来,称为B,定义如下
B = s i g n ( H v + H t + H l ) B = sign(H^v + H^t + H^l) B=sign(Hv+Ht+Hl)
于是类似于GAN的loss,我们定义我们的总体损失函数为 生成器的loss-辨别器的loss即
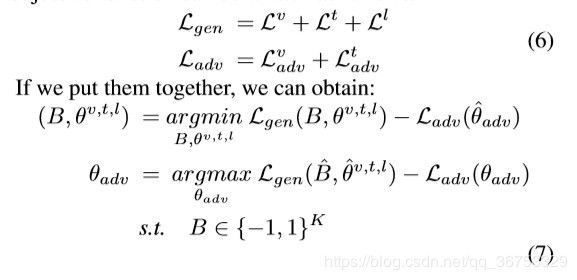
其 中 B ^ 表 示 B 的 单 位 向 量 其中\hat{B}表示B的单位向量 其中B^表示B的单位向量
由于参数B的非连续性,我们采用分部的方式进行参数优化

- 根据labNet的输出与分类的结果求取labNet的loss,对labNet的参数进行BP优化
- 此时我们固定labNet的参数,通过labNet的输出来同样采用BP优化ImgNet和TxtNet
- 最后我们固定labNet、imgNet、TxtNet的参数,利用他们的输出来更新俩个分辨器的参数
- 重复1-3步,直到训练完整个数据集
- 最后,当我们将所有的数据集训练后,我们根据训练后ImgNet、labNet、TxtNet的最终输出(hash code)来更新我们的B(binary code),然后进入下一次epoch重复上述1-4步
对于优化器的选择,本文选择了SGD(随机梯度下降)
training
hyperparameter
在训练中,作者对于生成器loss中的4个超参数进行测试,得出了最好的结果为
α = γ = 1 η = β = 1 0 − 4 l r = 1 0 − 4 t o 1 0 − 8 \alpha=\gamma=1~~~~~\eta=\beta=10^{-4}~~~lr=10^{-4}to10^{-8} α=γ=1 η=β=10−4 lr=10−4to10−8
performance

可以看出本文的SSAH结构比其他方法有明显改善,并且通过对于ImgNet的不同结构发现Vgg19的特征提取效果比CNN-F效果更好。
conclusion
本文将label作为输入之一,并且利用label的自监督学习生成的语义特征与其他模态的语义提取进行融合,利用对抗学习使得各模态与label的距离减小,利用label作为标准,拉近不同模态之间的距离。
缺点在于这里采用的mulit-label,该情况下的相似矩阵的设计过于简单,并且不能明显表明在有共同标签的对象间,标签数多的对象之间的相似性对比。
improvement
结合最近的DCMH方向的论文,本文可以对生成的hash code再次进行聚类,增加不同分类下hash code间的hamming距离
同时相似函数定义可以结合相关论文进行改进。
详细参看个人知乎文章https://zhuanlan.zhihu.com/p/61628792