Spark大数据分布式处理实战笔记(一):快速开始
前言
Spark是一种大规模、快速计算的集群平台,本公众号试图通过学习Spark官网的实战演练笔记提升笔者实操能力以及展现Spark的精彩之处。有关框架介绍和环境配置可以参考以下内容:
1.大数据处理框架Hadoop、Spark介绍
2.linux下Hadoop安装与环境配置
3.linux下Spark安装与环境配置
本文的参考配置为:Deepin 15.11、Java 1.8.0_241、Hadoop 2.10.0、Spark 2.4.4、scala 2.11.12
本文的目录为:
一、开启服务
二、Spark基础操作
三、DataSet上的更多操作
四、缓存
五、应用程序
一、开启服务
首先开启Hadoop服务(包括HDFS和yarn服务),再开启Spark的主节点及从节点服务。
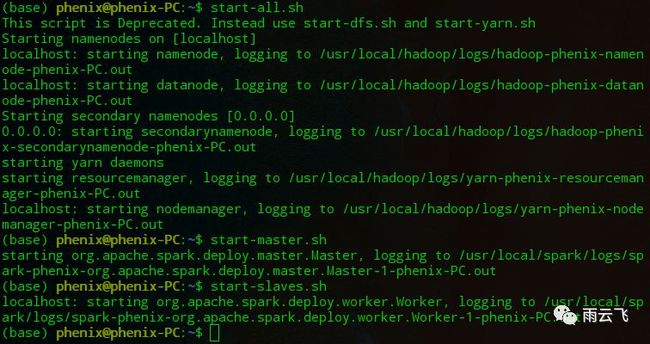
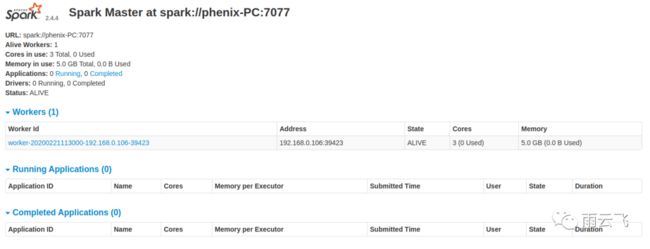
再通过spark-shell命令启用spark命令行模式:
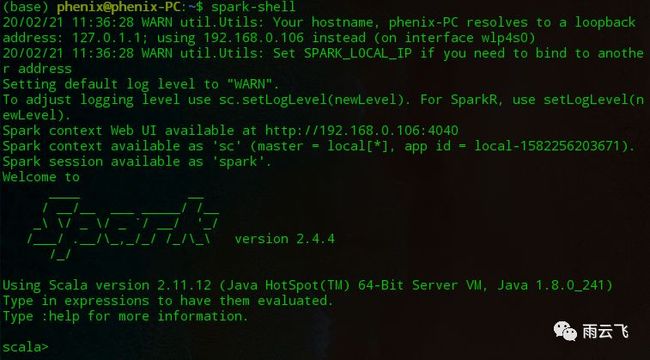
之后就可以通过链接进入spark的web界面:
二、Spark基础操作
Spark 的主要抽象是一个称为 Dataset 的分布式的 item 集合。Datasets 可以从 Hadoop 的 InputFormats(例如 HDFS文件)或者通过其它的 Datasets 转换来创建。我们先复制一段英文文本,并保存为test文件:
1.While there is life there is hope.
2.I am a slow walker,but I never walk backwards.
3.Never underestimate your power to change yourself!
4.Nothing is impossible!
5.Nothing for nothing.
6.The man who has made up his mind to win will never say "impossible".
7.I will greet this day with love in my heart.
8.Do what you say,say what you do
9.I can make it through the rain. I can stand up once again on my own.
10.All things come to those who wait.通过spark.read.textFile方法读取该文件并转换为Datesets。我们可以直接从 Dataset 中获取 values(值),通过调用一些 actions(动作),或者 transform(转换)Dataset 以获得一个新的。更多细节,请参阅Spark API。
scala> val textFile = spark.read.textFile("file:///home/phenix/Documents/spark/data/test")
textFile: org.apache.spark.sql.Dataset[String] = [value: string]
scala> textFile.count()
res0: Long = 10
scala> textFile.first()
res1: String = 1.While there is life there is hope.现在让我们 transform 这个 Dataset 以获得一个新的 。我们调用 filter 以返回一个新的 Dataset,它是文件中的 items 的一个子集。同样我们可以链式操作 transformation(转换)和 action(动作):
scala> val lineswithnever = textFile.filter(line => line.contains("never"))
lineswithnever: org.apache.spark.sql.Dataset[String] = [value: string]
scala> lineswithnever
res4: org.apache.spark.sql.Dataset[String] = [value: string]
scala> lineswithnever.collect()
res5: Array[String] = Array(2.I am a slow walker,but I never walk backwards., 6.The man who has made up his mind to win will never say "impossible".)// 链式操作
scala> lineswithnever.count()
res6: Long = 2三、Dataset上的更多操作
Dataset actions(操作)和 transformations(转换)可以用于更复杂的计算。例如,统计出现单词最多的行,结果为16。通过查看原始文件可知是第九行单词数最多为16个。
scala> textFile.map(line => line.split(" ").size).reduce((a, b) => if (a > b) a else b)
res0: Int = 16第一个 map 操作创建一个新的 Dataset,将一行数据 map 为一个整型值。在 Dataset 上调用 reduce 来找到最大的行计数。参数 map 与 reduce 是 Scala 函数(closures),并且可以使用 Scala/Java 库的任何语言特性。
一种常见的数据流模式是被 Hadoop 所推广的 MapReduce。Spark 可以很容易实现 MapReduce:
scala> val wordCounts = textFile.flatMap(line => line.split(" ")).groupByKey(identity).count()
wordCounts: org.apache.spark.sql.Dataset[(String, Long)] = [value: string, count(1): bigint
scala> wordCounts.collect()
res7: Array[(String, Long)] = Array((those,1), (slow,1), (rain.,1), (day,1), (7.I,1), (own.,1),...在这里,我们调用了 flatMap 以 transform 一个 lines 的 Dataset 为一个 words 的 Dataset,然后结合 groupByKey 和 count 来计算文件中每个单词的 counts 作为一个 (String, Long) 的 Dataset pairs。要在 shell 中,我们可以调用 collect来收集 word counts。
四、缓存
Spark 还支持 Pulling(拉取)数据集到一个群集范围的内存缓存中。例如当查询一个小的 “hot” 数据集或运行一个像 PageRANK 这样的迭代算法时,在数据被重复访问时是非常高效的。举一个简单的例子,让我们标记我们的 linesWithSpark 数据集到缓存中:
scala> lineswithnever.cache()
res2: lineswithnever.type = [value: string]
scala> lineswithnever.count()
res3: Long = 2
scala> lineswithnever.count()
res4: Long = 2五、应用程序
我们还可以使用 Spark API 来创建一个独立的应用程序。我们将在 Scala 中创建一个非常简单的 Spark 应用程序(应用程序打包支持Scala(SBT),Java(Maven),Python).首先我们创建SimpleApp.scala文件,该程序仅仅统计了之前文本文件中每一行包含 ‘a’ 的数量和包含 ‘b’ 的数量。
/* SimpleApp.scala */
import org.apache.spark.sql.SparkSession
object SimpleApp {
def main(args: Array[String]) {
val logFile = "file:///home/phenix/Documents/spark/data/test" // Should be some file on your system
val spark = SparkSession.builder.appName("Simple Application").getOrCreate()
val logData = spark.read.textFile(logFile).cache()
val numAs = logData.filter(line => line.contains("a")).count()
val numBs = logData.filter(line => line.contains("b")).count()
println(s"Lines with a: $numAs, Lines with b: $numBs")
spark.stop()
}
}
通过:load 命令加载scala文件并执行
scala> :load /home/phenix/Documents/spark/code/SimpleApp.scala
Loading /home/phenix/Documents/spark/code/SimpleApp.scala...
import org.apache.spark.sql.SparkSession
defined object SimpleApp
scala> SimpleApp.main(Array("test"))
20/02/21 13:28:28 WARN sql.SparkSession$Builder: Using an existing SparkSession; some configuration may not take effect.Lines with a: 7, Lines with b: 3 我们调用 SparkSession.builder 以构造一个 [[SparkSession]],然后设置 application name(应用名称),最终调用 getOrCreate 以获得 [[SparkSession]] 实例。
至此我们已经完成Spark的快速开始环节,下文将进一步讲解RDD、累加器及广播变量的概念及使用。
你可能错过了这些~
“高频面经”之数据分析篇
“高频面经”之数据结构与算法篇
“高频面经”之大数据研发篇
“高频面经”之机器学习篇
“高频面经”之深度学习篇
