
Spark分布式机器学习源码分析:模型评估指标
Spark是一个极为优秀的大数据框架,在大数据批处理上基本无人能敌,流处理上也有一席之地,机器学习则是当前正火热AI人工智能的驱动引擎,在大数据场景下如何发挥AI技术成为优秀的大数据挖掘工程师必备技能。本文结合机器学习思想与Spark框架代码结构来实现分布式机器学习过程,希望与大家一起学习进步~
本文采用的组件版本为:Ubuntu 19.10、Jdk 1.8.0_241、Scala 2.11.12、Hadoop 3.2.1、Spark 2.4.5,老规矩先开启一系列Hadoop、Spark服务与Spark-shell窗口:

spark.mllib附带了许多机器学习算法,可用于学习数据并进行数据预测。 将这些算法应用于构建机器学习模型时,需要根据某些标准评估模型的性能,具体取决于应用程序及其要求。spark.mllib还提供了一组度量标准,用于评估机器学习模型的性能。
特定的机器学习算法属于更广泛的机器学习应用程序类型,例如分类,回归,聚类等。这些类型中的每一种都有完善的性能评估指标,而此部分将详细介绍spark.mllib中当前可用的那些指标。
1
二分类
尽管分类算法有许多不同的类型,但是分类模型的评估都具有相似的原理。在监督分类问题中,每个数据点都存在真实输出和模型生成的预测输出。因此,可以将每个数据点的结果分配给以下四个类别之一:
真阳性(TP)-标签为阳性,预测也为阳性
真阴性(TN)-标签为负,预测也为负
假阳性(FP)-标签为负,但预测为正
假阴性(FN)-标签为阳性,但预测为阴性

这四个数字是大多数分类器评估指标的基础。考虑分类器评估时的基本要点是,单纯的准确性(即预测正确与否)通常不是一个好的指标。其原因是因为数据集可能高度不平衡。例如,如果模型被设计为从数据集中预测欺诈的模型,其中95%的数据点不是欺诈,而5%的数据点是欺诈,则无论输入如何,预测都不欺诈的朴素分类器将为95 %准确。因此,通常会使用诸如精度和召回率之类的指标,因为它们考虑到了错误的类型。在大多数应用中,精度和查全率之间存在一些理想的平衡,可以通过将两者合并为一个度量标准(称为F度量)来捕获。
2
二分类
二分类器用于将给定数据集的元素分为两个可能的组(例如欺诈或非欺诈)之一,这是多类分类的一种特殊情况。大多数二元分类指标可以概括为多类分类指标。
重要的是要理解,许多分类模型实际上为每个类别输出“分数”(通常是概率的乘积),其中较高的分数表示较高的可能性。在二元情况下,模型可以输出每个类别的概率:P(Y=1|X)和P(Y=0|X)。在某些情况下,可能需要调整模型,以便仅在概率很高的情况下预测类别(例如,如果模型预测欺诈概率> 90%,则阻止信用卡交易),而不是简单地采用较高的概率)。因此,存在一个预测阈值,该阈值可根据模型输出的概率来确定预测类别。
调整预测阈值将改变模型的精度和召回率,这是模型优化的重要组成部分。为了可视化精度,召回率和其他指标如何随阈值变化,通常的做法是将竞争指标相互绘制,并按阈值进行参数设置。P-R曲线绘制(精确度,召回率)点以表示不同阈值,而接收器工作特性曲线或ROC曲线绘制(召回率,误报率)点。

3
多分类
以下代码段说明了如何加载样本数据集,如何在数据上训练二分类算法以及如何通过几种二分类评估指标评估算法的性能。
import org.apache.spark.mllib.classification.LogisticRegressionWithLBFGS
import org.apache.spark.mllib.evaluation.BinaryClassificationMetrics
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark.mllib.util.MLUtils
// 加载libsvm格式的训练数据
val data = MLUtils.loadLibSVMFile(sc, "data/mllib/sample_binary_classification_data.txt")
// 将数据分为训练(60%)和测试(40%)
val Array(training, test) = data.randomSplit(Array(0.6, 0.4), seed = 11L)
training.cache()
// 运行训练算法以建立模型
val model = new LogisticRegressionWithLBFGS().setNumClasses(2).run(training)
// 清除预测阈值,以便模型返回概率
model.clearThreshold
// 计算测试集上的原始分数
val predictionAndLabels = test.map { case LabeledPoint(label, features) =>
val prediction = model.predict(features)
(prediction, label)
}
// 实例化指标对象
val metrics = new BinaryClassificationMetrics(predictionAndLabels)
// 通过阈值预测精度
val precision = metrics.precisionByThreshold
precision.foreach { case (t, p) =>
println(s"Threshold: $t, Precision: $p")
}
// 通过阈值预测召回率
val recall = metrics.recallByThreshold
recall.foreach { case (t, r) =>
println(s"Threshold: $t, Recall: $r")
}
// PR曲线
val PRC = metrics.pr
// F值
val f1Score = metrics.fMeasureByThreshold
f1Score.foreach { case (t, f) =>
println(s"Threshold: $t, F-score: $f, Beta = 1")
}
val beta = 0.5
val fScore = metrics.fMeasureByThreshold(beta)
f1Score.foreach { case (t, f) =>
println(s"Threshold: $t, F-score: $f, Beta = 0.5")
}
// AUPRC
val auPRC = metrics.areaUnderPR
println(s"Area under precision-recall curve = $auPRC")
// 计算在ROC和PR曲线中使用的阈值
val thresholds = precision.map(_._1)
// ROC曲线
val roc = metrics.roc
// AUROC
val auROC = metrics.areaUnderROC
println(s"Area under ROC = $auROC")
3
多分类
多分类描述了一个分类问题,其中每个数据点有M> 2个可能的标签(其中M = 2是二分类问题)。例如,将手写样本分类为具有10种可能类别的数字0到9。
对于多类别指标,肯定和否定的概念略有不同。预测和标签仍然可以是肯定的或否定的,但必须在特定类别的上下文中加以考虑。每个标签和预测采用多个类别之一的值,因此对于它们的特定类别而言,它们被认为是正的,而对于所有其他类别而言,它们都被认为是负的。因此,每当预测和标签匹配时,就会出现真阳性,而当预测和标签都不采用给定类的值时,就会出现真阴性。按照这种约定,给定的数据样本可能有多个真实的负数。从肯定标签和否定标签的先前定义中扩展假阴性和假阳性很简单。
与只有两个可能的标签的二分类相反,多类分类问题有很多可能的标签,因此引入了基于标签的度量的概念。 准确性衡量所有标签的准确性-通过数据点的数量对任何类别进行正确预测(正确肯定)的次数。 按标签的精度仅考虑一类,并根据标签出现在输出中的次数来衡量正确预测特定标签的时间。
定义类或标签,设置为![]() ,真实输出向量y由N个元素组成
,真实输出向量y由N个元素组成![]() ,多类预测算法生成N个元素的预测向量
,多类预测算法生成N个元素的预测向量![]() 。对于本节,修改后的增量函数δ^(x)将被证明是有用的
。对于本节,修改后的增量函数δ^(x)将被证明是有用的

4
多分类实例
以下代码段说明了如何加载样本数据集,如何在数据上训练多分类算法以及如何通过几种多类分类评估指标来评估算法的性能。
import org.apache.spark.mllib.classification.LogisticRegressionWithLBFGS
import org.apache.spark.mllib.evaluation.MulticlassMetrics
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark.mllib.util.MLUtils
val data = MLUtils.loadLibSVMFile(sc, "data/mllib/sample_multiclass_classification_data.txt")
val Array(training, test) = data.randomSplit(Array(0.6, 0.4), seed = 11L)
training.cache()
val model = new LogisticRegressionWithLBFGS().setNumClasses(3).run(training)
val predictionAndLabels = test.map { case LabeledPoint(label, features) =>
val prediction = model.predict(features)
(prediction, label)
}
val metrics = new MulticlassMetrics(predictionAndLabels)
// 混淆矩阵
println("Confusion matrix:")
println(metrics.confusionMatrix)
// 总体统计
val accuracy = metrics.accuracy
println("Summary Statistics")
println(s"Accuracy = $accuracy")
// 通过标签预测
val labels = metrics.labels
labels.foreach { l =>
println(s"Precision($l) = " + metrics.precision(l))
}
// 通过标签计算召回率
labels.foreach { l =>
println(s"Recall($l) = " + metrics.recall(l))
}
// 通过标签计算假阳性率
labels.foreach { l =>
println(s"FPR($l) = " + metrics.falsePositiveRate(l))
}
// 通过标签计算F1
labels.foreach { l =>
println(s"F1-Score($l) = " + metrics.fMeasure(l))
}
// 加权统计
println(s"Weighted precision: ${metrics.weightedPrecision}")
println(s"Weighted recall: ${metrics.weightedRecall}")
println(s"Weighted F1 score: ${metrics.weightedFMeasure}")
println(s"Weighted false positive rate: ${metrics.weightedFalsePositiveRate}")
5
多标签分类
多标签分类问题涉及将数据集中的每个样本映射到一组类标签。在这种类型的分类问题中,标签不是互斥的。例如,将一组新闻文章分类为主题时,一篇文章可能既是科学又是政治。
由于标签不是互斥的,因此预测和真实标签现在是标签集的向量,而不是标签的向量。因此,多标签度量将精度,召回率等基本概念扩展到集合操作上。例如,当给定类别的某个特定数据点存在于预测集中且该类别存在于真实标签集中时,则该类别为真阳性。
在这里,我们定义了N个文档的集合D:![]() ,将L0,L1,...,LN-1定义为标签集的族,并将P0,P1,...,PN-1定义为预测集的族,其中Li和Pi分别是标签集和预测集记录di。所有唯一标签的集合由
,将L0,L1,...,LN-1定义为标签集的族,并将P0,P1,...,PN-1定义为预测集的族,其中Li和Pi分别是标签集和预测集记录di。所有唯一标签的集合由

对集合A的指标函数IA(x)的以下定义将是必要的
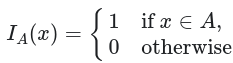

6
多标签分类实例
以下代码段说明了如何评估多标签分类器的性能。这些示例将伪造的预测和标签数据用于多标签分类。
import org.apache.spark.mllib.evaluation.MultilabelMetrics
import org.apache.spark.rdd.RDD
val scoreAndLabels: RDD[(Array[Double], Array[Double])] = sc.parallelize(
Seq((Array(0.0, 1.0), Array(0.0, 2.0)),
(Array(0.0, 2.0), Array(0.0, 1.0)),
(Array.empty[Double], Array(0.0)),
(Array(2.0), Array(2.0)),
(Array(2.0, 0.0), Array(2.0, 0.0)),
(Array(0.0, 1.0, 2.0), Array(0.0, 1.0)),
(Array(1.0), Array(1.0, 2.0))), 2)
val metrics = new MultilabelMetrics(scoreAndLabels)
println(s"Recall = ${metrics.recall}")
println(s"Precision = ${metrics.precision}")
println(s"F1 measure = ${metrics.f1Measure}")
println(s"Accuracy = ${metrics.accuracy}")
metrics.labels.foreach(label =>
println(s"Class $label precision = ${metrics.precision(label)}"))
metrics.labels.foreach(label => println(s"Class $label recall = ${metrics.recall(label)}"))
metrics.labels.foreach(label => println(s"Class $label F1-score = ${metrics.f1Measure(label)}"))
println(s"Micro recall = ${metrics.microRecall}")
println(s"Micro precision = ${metrics.microPrecision}")
println(s"Micro F1 measure = ${metrics.microF1Measure}")
println(s"Hamming loss = ${metrics.hammingLoss}")
println(s"Subset accuracy = ${metrics.subsetAccuracy}")
7
排序算法
排名算法(通常被认为是推荐系统)的作用是根据一些训练数据向用户返回一组相关项目或文档。相关性的定义可能会有所不同,并且通常是特定于应用程序的。排名系统指标旨在量化这些排名或建议在各种情况下的有效性。一些度量将一组推荐的文档与一组相关文档的真实性进行比较,而其他度量可能会明确包含数字等级。
排名系统通常处理一组M个用户
![]()
每个用户(ui)都有一组Ni真实情况相关文档
![]()
并列出齐推荐文件,以降序排列
![]()
排名系统的目标是为每个用户生成最相关的文档集。集合的相关性和算法的有效性可以使用下面列出的指标进行衡量。
有必要定义一个函数,该函数提供了一个推荐文档和一组与地面事实相关的文档,并返回了该推荐文档的相关性得分。


8
排序算法实例
以下代码段说明了如何加载样本数据集,如何在数据上训练交替的最小二乘推荐模型以及如何通过几个排名指标评估推荐器的性能。下面提供了该方法的简要概述。
此映射表示未观察到的条目通常介于“正常”和“相当差”之间。在这个非正数权重的扩展世界中,0的语义“与从未交互过的相同”。
import org.apache.spark.mllib.evaluation.{RankingMetrics, RegressionMetrics}
import org.apache.spark.mllib.recommendation.{ALS, Rating}
// 读取收视率数据
val ratings = spark.read.textFile("data/mllib/sample_movielens_data.txt").rdd.map { line =>
val fields = line.split("::")
Rating(fields(0).toInt, fields(1).toInt, fields(2).toDouble - 2.5)
}.cache()
// 将等级映射为1或0,其中1表示应该推荐的电影
val binarizedRatings = ratings.map(r => Rating(r.user, r.product,
if (r.rating > 0) 1.0 else 0.0)).cache()
// 汇总评分
val numRatings = ratings.count()
val numUsers = ratings.map(_.user).distinct().count()
val numMovies = ratings.map(_.product).distinct().count()
println(s"Got $numRatings ratings from $numUsers users on $numMovies movies.")
// 建立模型
val numIterations = 10
val rank = 10
val lambda = 0.01
val model = ALS.train(ratings, rank, numIterations, lambda)
// 定义一个函数以将等级从0缩放到1
def scaledRating(r: Rating): Rating = {
val scaledRating = math.max(math.min(r.rating, 1.0), 0.0)
Rating(r.user, r.product, scaledRating)
}
// 获取每个用户的排名前十的预测,然后从[0,1]开始缩放
val userRecommended = model.recommendProductsForUsers(10).map { case (user, recs) =>
(user, recs.map(scaledRating))
}
// 假设用户评分3或更高(对应于1)的任何电影都是相关文档
// 与最相关的十大文件进行比较
val userMovies = binarizedRatings.groupBy(_.user)
val relevantDocuments = userMovies.join(userRecommended).map { case (user, (actual,
predictions)) =>
(predictions.map(_.product), actual.filter(_.rating > 0.0).map(_.product).toArray)
}
// 实例化指标对象
val metrics = new RankingMetrics(relevantDocuments)
//精度
Array(1, 3, 5).foreach { k =>
println(s"Precision at $k = ${metrics.precisionAt(k)}")
}
// 平均平均精度
println(s"Mean average precision = ${metrics.meanAveragePrecision}")
// 归一化折现累计收益
Array(1, 3, 5).foreach { k =>
println(s"NDCG at $k = ${metrics.ndcgAt(k)}")
}
// 获取每个数据点的预测
val allPredictions = model.predict(ratings.map(r => (r.user, r.product))).map(r => ((r.user,
r.product), r.rating))
val allRatings = ratings.map(r => ((r.user, r.product), r.rating))
val predictionsAndLabels = allPredictions.join(allRatings).map { case ((user, product),
(predicted, actual)) =>
(predicted, actual)
}
// 使用回归指标获取RMSE
val regressionMetrics = new RegressionMetrics(predictionsAndLabels)
println(s"RMSE = ${regressionMetrics.rootMeanSquaredError}")
// 计算R方
println(s"R-squared = ${regressionMetrics.r2}")
9
回归算法评估
从多个自变量预测连续输出变量时,将使用回归分析。

以下代码段说明了如何加载样本数据集,在数据上训练线性回归算法以及如何通过多个回归指标评估算法的性能。
import org.apache.spark.mllib.evaluation.RegressionMetrics
import org.apache.spark.mllib.linalg.Vector
import org.apache.spark.mllib.regression.{LabeledPoint, LinearRegressionWithSGD}
// 加载数据
val data = spark
.read.format("libsvm").load("data/mllib/sample_linear_regression_data.txt")
.rdd.map(row => LabeledPoint(row.getDouble(0), row.get(1).asInstanceOf[Vector]))
.cache()
// 建立模型
val numIterations = 100
val model = LinearRegressionWithSGD.train(data, numIterations)
// 获取预测
val valuesAndPreds = data.map{ point =>
val prediction = model.predict(point.features)
(prediction, point.label)
}
// 实例化指标对象
val metrics = new RegressionMetrics(valuesAndPreds)
// Squared error
println(s"MSE = ${metrics.meanSquaredError}")
println(s"RMSE = ${metrics.rootMeanSquaredError}")
// R-squared
println(s"R-squared = ${metrics.r2}")
// Mean absolute error
println(s"MAE = ${metrics.meanAbsoluteError}")
// Explained variance
println(s"Explained variance = ${metrics.explainedVariance}")
Spark模型评估指标以及源码分析的全部内容至此结束,有关Spark的基础文章可参考前文:
Spark分布式机器学习源码分析:矩阵向量
Spark分布式机器学习源码分析:基本统计
Spark分布式机器学习源码分析:线性模型
Spark分布式机器学习源码分析:朴素贝叶斯
Spark分布式机器学习源码分析:决策树模型
Spark分布式机器学习源码分析:集成树模型
Spark分布式机器学习源码分析:协同过滤
Spark分布式机器学习源码分析:K-means
Spark分布式机器学习源码分析:隐式狄利克雷分布
Spark分布式机器学习源码分析:奇异值分解与主成分分析
Spark分布式机器学习源码分析:特征提取与转换
Spark分布式机器学习源码分析:频繁模式挖掘
参考链接:
http://spark.apache.org/docs/latest/mllib-evaluation-metrics.html

历史推荐
“高频面经”之数据分析篇
“高频面经”之数据结构与算法篇
“高频面经”之大数据研发篇
“高频面经”之机器学习篇
“高频面经”之深度学习篇
爬虫实战:Selenium爬取京东商品
爬虫实战:豆瓣电影top250爬取
爬虫实战:Scrapy框架爬取QQ音乐

数据分析与挖掘
数据结构与算法
机器学习与大数据组件
欢迎关注,感谢“在看”,随缘稀罕~

一个赞,晚餐加鸡腿