java用pdfbox解析pdf文件中的表格
需要解析的pdf是一个发票

没有废话,先导入pdfbox的依赖
org.apache.pdfbox
pdfbox
2.0.16
我先是这样写的,pdf相关的对象都是org.apache.pdfbox包下的,就不写了
@Test
public void test1() throws Exception {
PDDocument pdDocument = PDDocument.load(new File("D:\\work\\file\\temp\\普通电子发票.pdf"));
if (pdDocument.isEncrypted()) {//加密
System.out.println("pdDocument.isEncrypted");
return;
}
PDPage page = pdDocument.getPage(0);//第一页
PDFTextStripperByArea pdfTextStripper = new PDFTextStripperByArea();//区域文本剥离器
pdfTextStripper.addRegion("region1", new Rectangle(0, 0, (int) page.getMediaBox().getWidth(), (int) page.getMediaBox().getHeight()));//区域大小
pdfTextStripper.extractRegions(page);//设置页
pdfTextStripper.setSortByPosition(true);//排序
String text = pdfTextStripper.getTextForRegion("region1");//剥离文本
System.out.println(text);
pdDocument.close();
}其中getMediaBox()方法是获取pdf文件的几个box之一,pdf文件有几个box,什么裁剪打印什么的,相当于不同的范围,有一些特有的信息,反正mediaBox是范围最大的那个。
虽然设置了排序,应该是按从上到下,从左到右排序的,但是输出之后发现文字的顺序是乱的,所以又换了下面这样
@Test
public void test2() throws Exception {
PDDocument pdDocument = PDDocument.load(new File("D:\\work\\file\\temp\\普通电子发票.pdf"));
PDFTextStripper pdfTextStripper = new PDFTextStripper();
pdfTextStripper.setSortByPosition(true);
pdfTextStripper.setStartPage(0);
pdfTextStripper.setEndPage(1);
String text = pdfTextStripper.getText(pdDocument);
System.out.println(text);
pdDocument.close();
}注意设置读取的起始页和结束页是不包含结束页的,我上面如果两个都设置0的话,是读取不到内容的。
这次都读到了数据,而且是按顺序排列的,如下
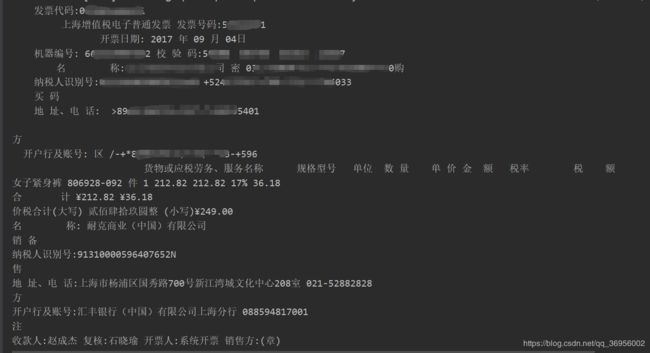
大致上是可读的,仔细对比一下的话能看出来是按坐标的从上到下,从左到右排序的,大概是这个亚子

基本上是按这个顺序读的,文本都能取到,之后只需要按照格式进行字符串的处理就可以了
搞了三天再来写一点。
开始想的是直接读取页面全部的文本,然后按行分隔,再按空格分隔,然后按“第几行应该是什么数据”这种思路去取。
但是!
看了许多发票,发现字段的key和value不一定是同一行,高度有可能会有一点偏差,但是不会跑到其他行。我看的第一个pdf刚好是在同一行的,你说巧不巧。
这就导致了直接全部读取出来的话,每一行的顺序不固定,比如名称一行,可能“名称”在上,也可能是名称的值在上。总之读出来的数据是乱的,没有办法按照“第几行应该是什么数据”这种思路去取。
所以读取的垂直范围必须得比文字大一点才行,需要计算每一行之间空白的高度,然后按区域读取文字的时候要把空白的这部分加上,就可以保证即使有一点偏差,也能将key和value在同一个区域读出来。
我这里是读取了所有文字的坐标,然后按从上到下,从左到右顺序排序,然后找每一行的关键字,去确定这一行的坐标。
比如先从上往下读,倒着读,读到第一个“码”字,就是“发票代码”这一行,读到第二个就是“发票号码”这一行,然后通过这两个字的坐标,再计算出这两行之间空白的高度,然后按坐标读取的时候加上空白的1/2,保证字段的值就算有一点偏差,也能读出来。
下面的字段也是用类似的方式,就是找到关键字,判断一个大致的范围,这种方式因为是按文字去确定的范围,所以对于明细区域的文字没法用,明细我是按行和空额分隔的,因为我读取的发票格式比较固定刚好可以用这种方法读。
确定每个文字的坐标的话需要继承PDFTextStripper类,覆盖processTextPosition方法,这个方法传入的TextPosition就有这个文字的坐标信息,下面那个方法是按从上到下,从左到右排序返回了这些信息。
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.text.PDFTextStripper;
import org.apache.pdfbox.text.TextPosition;
import java.awt.*;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class MyStripper extends PDFTextStripper {
List> rectangleList;
List allRectangle;
/**
* Instantiate a new PDFTextStripper object.
*
* @throws IOException If there is an error loading the properties.
*/
public MyStripper() throws IOException {
super();
}
@Override
protected void processTextPosition(TextPosition text) {
allRectangle.add(new Rectangle((int)text.getX(), (int)text.getY(), (int)text.getWidth(), (int)text.getHeight()));
}
public List> getTextRectangleList(PDDocument pdDocument) throws IOException {
rectangleList = new ArrayList<>();
allRectangle = new ArrayList<>();
setSortByPosition(true);
setStartPage(0);
setEndPage(1);
getText(pdDocument);
if(allRectangle.size() == 0){
return rectangleList;
}
allRectangle.sort((a, b) ->{
if(a.y == b.y){
if(a.x == b.x){
return 0;
}else if(a.x > b.x){
return 1;
}else {
return -1;
}
}else if(a.y > b.y){
return 1;
}else {
return -1;
}
});
List subRectangleList = new ArrayList<>();
int y = allRectangle.get(0).y;
for(Rectangle rectangle : allRectangle){
if(y != rectangle.y){
y = rectangle.y;
rectangleList.add(subRectangleList);
subRectangleList = new ArrayList<>();
}
subRectangleList.add(rectangle);
}
rectangleList.add(subRectangleList);
return rectangleList;
}
} 最好的方法还是定位表格线的坐标,然后把表格按线的坐标去划分成各个单元格,因为这个表格中单元格的大小可能会有偏差,但是样式是固定的,第几行第几列是什么就是什么。
但是搜了pdfbox和itext,只搜到了文本和图片的定位,没有线的定位,Python的倒是有可以定位线的方法。
要是哪位大佬知道java的方法,麻烦评论区告知,万分感谢!