工具和中间件——网络爬虫,目标:ZOL壁纸
目录
一、前言
二、python网络爬虫
2.1 页面分析
2.2 核心代码
三、Java网络爬虫
3.1 页面分析
3.2核心代码(普通工程)
3.3核心代码(maven工程)
四、小结
一、前言
日常工作中,我们总是喜欢精美的壁纸,ZOL官网为我们提供了精美壁纸,只要选中好看的设置桌面壁纸即可。可是呢,人总是这么贪婪,主观观念上总是想把ZOL官网上的所有都下载下来,然后存在自己的磁盘了,满满的得意感。怎么办呢,网路爬虫爬下来呗,本文以ZOL壁纸为例,使用Python和Java两种方式爬取ZOL壁纸,文末给出源代码和壁纸资源。
二、python网络爬虫
2.1 页面分析
我们首先要对爬取的zol壁纸的html页面元素分析,为什么呢?因为我们要爬取的不是一张两张图片,而是一大批图片,ZOL壁纸官网实际上已经对其上的图片进行过分门别类,如风景图片、美女图片、游戏图片,我们可以将这些分类的标签文本拿下来,作为我们本地磁盘目录文件夹名称,然后爬取的图片放在对应的文件夹里面去,保证爬下来的图片有条不紊。
得到第一层目录:
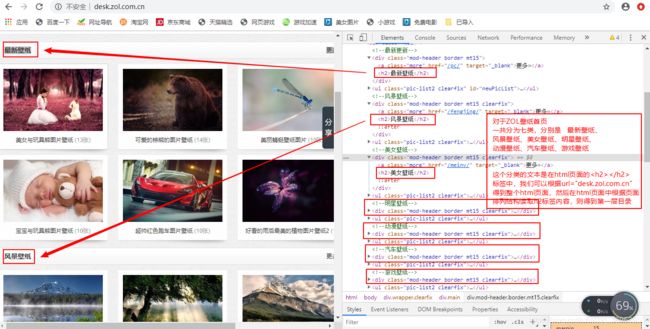
得到第二层目录:
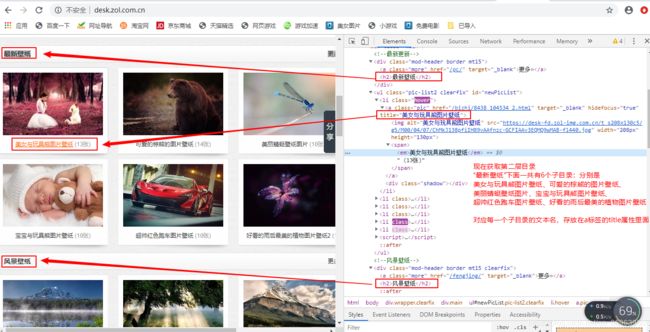
第三层目录(实际上第三层目录不叫目录,得到第二层目录后点击进去就有该目录下的所有图片,但是遇到一个问题,每一张图片都有不同的分辨率,爬取的时候我们到底爬取哪个分辨率的图片呢?)
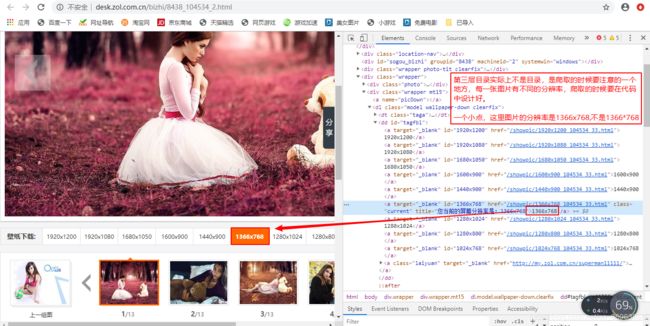
关于图片的分辨率要注意两点:
第一,同一图片有不同分辨率,要爬取的是什么分辨率的图片,在代码中要设计好;
第二,图片分辨率的表示要记住,这里的表示是1920x1080,不是1920*1080,程序员一定要看清楚。
图片地址

2.2 核心代码
2.2.1 新建ZOL文件夹
# 相对路径下创建文件夹 如果没有就新建一个ZOL文件夹
if not os.path.exists("ZOL"):
os.mkdir("ZOL")2.2.2 从url_zol根地址得到url_html根html页面,并从根html页面中获取第一层目录(7个)第二层目录(42个=6*7),获取其文本以便存放的时候新建本地文件夹之用
(1)从url_zol根地址得到url_html根html页面
# 运用爬虫寻找图库入口 url_zol是zol首页,根地址 html_zol是zol首页的html
url_zol = 'http://desk.zol.com.cn/'
html_zol = requests.get(url_zol).text # 请求到页面内容html(2)从根html页面中获取第一层目录(7个)第二层目录(42个=6*7),获取其文本以便存放的时候新建本地文件夹之用
# url re.findall 参数为:匹配的正则表达式pattern 要匹配的字符串string 标志位flag=0 返回为匹配的url列表 元素个数42个
pic_url = re.findall('a class="pic" href="/bizhi/(.*?)" ', html_zol, re.S)
# name 第二层目录 参数为:匹配的正则表达式pattern 要匹配的字符串string 标志位flag=0 返回为匹配的name列表 是pic_leixin下面的子文件夹
# 元素个数42个 pic_name一个42个文件夹
# 因为pic_name在pic_leixin下面,所有每一个pic_leixin有6个pic_name
pic_name = re.findall('.html" target="_blank" hidefocus="true" title="(.*?)"', html_zol, re.S)
# 类型/第一层目录 标签文本作为文件夹 参数为:匹配的正则表达式pattern 要匹配的字符串string 标志位flag=0 返回为匹配的类型列表 元素个数7个 pic_leixin一共7个文件夹
pic_leixin = re.findall('(.*?)
', html_zol, re.S)
2.2.3 从url_zol得到url_Tuku,再从url_Tuku得到html_Tuku,打开第二层目录实现图片预览,获取图片的imgsrc属性,以便下载之用
(1)从url_zol得到url_Tuku
url_Tuku = 'http://desk.zol.com.cn/bizhi/' + each # 拼接 每一个html页面都是一个图库 一共42个html页面,则一共42个图库(2)从url_Tuku得到html_Tuku,打开第二层目录实现图片预览,获取图片的imgsrc属性,以便下载之用
html_Tuku = requests.get(url_Tuku).text
pic_url2 = re.findall('"imgsrc":"(.*?)"}', html_Tuku, re.S) # html_Tuku图库页面中各个图的url地址列表2.2.4 图片分辨率(这里使用最常用的1920x1080)
# 1920*1080c5 错误 1920x1080c5 注意 对应每一个图 取出其size为1920x1080的图片
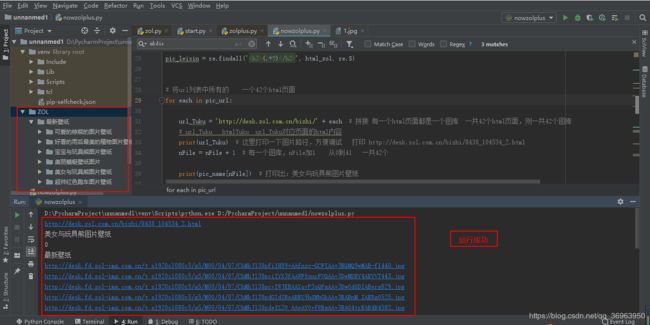
pic_realurl = pic_realurl.replace('##SIZE##', '1920x1080c5')2.2.5 运行成功
三、Java网络爬虫
3.1 页面分析
略,上面有了,无非就是两层目录+图片分辨率(三层目录)+图片地址
3.2核心代码(普通工程)
(java代码有两份,一份是java普通工程,从给定url获取html使用自定义方法,一份是maven工程,从给定url获取html使用Jsonp依赖,3.2展示java普通工程,3.3展示maven工程)
3.2.1 工具方法:从给定url获取html使用自定义方法
如下:使用字节输入流获取指定url内容,使用byte数组和Buffer流同时加速
public static String getHtml(String string) throws Exception{
URL url = new URL(string);
String result="";
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
//获得字节流
InputStream inputStream = connection.getInputStream();
//获得字节缓冲流
BufferedInputStream bufferedInputStream = new BufferedInputStream(inputStream);
byte[] bytes = new byte[255];
int total_number;
while((total_number = bufferedInputStream.read(bytes)) != -1) {
//控制台输出
result+=new String(bytes,"gb2312"); //因为zol壁纸首页使用gb2312编码
}
return result;
}3.2.2 工具方法:正则表示式获取给定规则匹配的内容
参数列表pattern是匹配规则,content是需要匹配的字符串,返回是一个List
注意:这里必须是m.group(1),因为只有这样实现只保留html里面的内容
public static List getRegrex(String pattern,String content){
//创建Pattern对象
Pattern p=Pattern.compile(pattern);
//创建Matcher对象
Matcher m=p.matcher(content);
List list = new ArrayList<>();
while (m.find()) {
list.add(m.group(1)); //group(1)才可以提纯
}
return list;
} 3.2.3 工具方法:将图片保存至本地
因为图片是二进制文件,所有用字节数据输出流ByteArrayOutputStream.
public static void OutputFunction(String string,InputStream dataInputStream) throws Exception{
FileOutputStream fileOutputStream=new FileOutputStream(string);
ByteArrayOutputStream output = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
int length;
while ((length = dataInputStream.read(buffer)) > 0) {
output.write(buffer, 0, length);
}
byte[] context=output.toByteArray();
fileOutputStream.write(output.toByteArray());
dataInputStream.close();
fileOutputStream.close();
}3.2.4 最后一个注意的地方(网址中的\/符号替换为/)
如下:
String pic_realurl = each2.replace("\\/", "/");这句读者在源代码中很容易就可以找到,目的是替换图片地址网址中的\/为/。
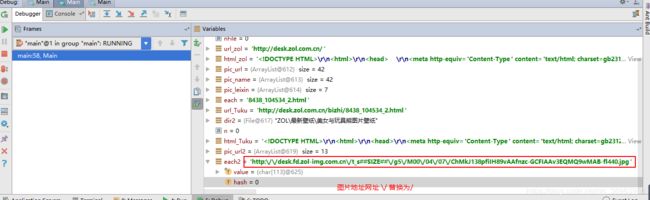
但是,java和python不同,python是replace('\/','/'),java则是replace("\\/","/"),因为java要加上一个转义字符。
3.3核心代码(maven工程)
maven工程和普通java工程唯一不同的地方,
普通工程:从给定url获取html使用自定义方法,maven工程:从给定url获取html使用Jsonp依赖。
如下:
org.jsoup
jsoup
1.10.2
//提取html源代码
String html_zol= Jsoup.parse(new URL(url_zol),1000)+""; String html_Tuku=Jsoup.parse(new URL(url_Tuku),1000)+"";仅此一个改变,读者阅读源码注意即可。
3.4运行成功:

四、小结
ZOL所有的壁纸当然是没办法都爬下来的啦,而且也不用了那么多,不过还是爬了很多的,毕竟忙活了一晚上。
看看吧:

Python工程源代码:https://download.csdn.net/download/qq_36963950/12046437
Java普通工程源代码:https://download.csdn.net/download/qq_36963950/12046435
JavaMaven工程源代码:https://download.csdn.net/download/qq_36963950/12046443
全部图片(244MB):https://download.csdn.net/download/qq_36963950/12046445
天天打码,天天进步!
