用Keras和“直方图均衡”为深度学习实现“图像扩充”
原文链接
雷锋网按:本文由图普科技编译自《Image Augmentation for Deep Learning using Keras and Histogram Equalization》,雷锋网(公众号:雷锋网)独家首发。

在这篇文章中,我们将要讨论的内容是:
-
什么是“图像增强”?其重要性何在?
-
如何使用Keras实现基本的“图像增强”?
-
什么是“直方图均衡”?如何发挥其作用?
-
直方图均衡法——修改keras.preprocessing image.py文件的方式之一
-
什么是“图像增强”?其重要性何在?
深度神经网络,尤其是卷积神经网络(CNN),非常擅长于图像分类。事实证明,最先进的卷积神经网络在图像识别方面的性能已经超过了人类水平。

https://www.eff.org/ai/metrics
然而,正如我们在杨建先生的“Hot Dog, Not Hot Dog”App(在一个叫做“Silicon Valley”的热门电视节目中的食物识别App)中了解到的,将图像收集起来作为训练数据使用,是一项非常昂贵且耗时的工作。
如果你对“Silicon Valley”这个电视节目不太熟悉,请注意以下视频中的语言是NSFW:
我们通过扩充图像数据的方式,从一个已有的数据库中生成更多新的训练图像,以降低收集训练图像的成本。“图像扩充”其实就是从已有的训练数据集中取出一些图像,然后根据这些图像创建出许多修改版本的图像。这样做不仅能够获得更多的训练数据,还能让我们的分类器应对光照和色彩更加复杂的环境,从而使我们的分类器功能越来越强大。以下是来自imgaug的不同的图像扩充例子:

https://github.com/aleju/imgaug
-
用Keras实现基本的图像扩充
图像预处理的方法有很多。在本文中,我们将讨论一些常见的、富有创意的方法,这些方法也是Keras深度学习库为扩充图像数据所提供的。之后我们将讨论如何转换keras预处理图像文件,以启用直方图均衡法。我们将使用Keras附带的cifar10数据集,但是为了使任务小到能够顺利在CPU上执行,我们将只会使用其中的猫和狗的图像。
-
数据加载及数据格式化
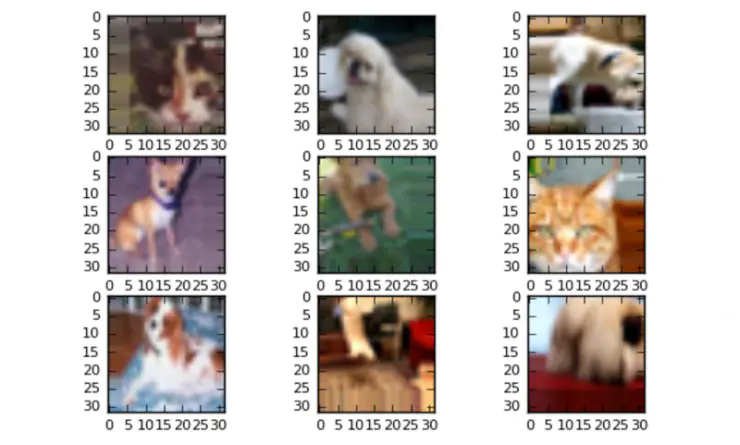
首先,我们需要加载cifar10数据集并格式化其中的图像,为卷积神经网络做好准备。我们还要检查一下部分图像,确保数据已经完成了正确的加载。
from __future__ import print_function
import keras
from keras.datasets import cifar10
from keras import backend as K
import matplotlib
from matplotlib import pyplot as plt
import numpy as np#Input image dimensions
img_rows, img_cols = 32, 32#The data, shuffled and split between train and test sets
(x_train, y_train), (x_test, y_test) = cifar10.load_data()#Only look at cats [=3] and dogs [=5]
train_picks = np.ravel(np.logical_or(y_train==3,y_train==5))
test_picks = np.ravel(np.logical_or(y_test==3,y_test==5))y_train = np.array(y_train[train_picks]==5,dtype=int)
y_test = np.array(y_test[test_picks]==5,dtype=int)x_train = x_train[train_picks]
x_test = x_test[test_picks]if K.image_data_format() == 'channels_first':
x_train = x_train.reshape(x_train.shape[0], 3, img_rows, img_cols)
x_test = x_test.reshape(x_test.shape[0], 3, img_rows, img_cols)
input_shape = (3, img_rows, img_cols)
else:
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 3)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 3)
input_shape = (img_rows, img_cols, 3)x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')#Convert class vectors to binary class matrices
y_train = keras.utils.to_categorical(np.ravel(y_train), num_classes)
y_test = keras.utils.to_categorical(np.ravel(y_test), num_classes)#Look at the first 9 images from the dataset
images = range(0,9)
for i in images:
plt.subplot(330 + 1 + i)
plt.imshow(x_train[i], cmap=pyplot.get_cmap('gray'))
#Show the plot
plt.show()

Cifar10数据集中的图像都是32x 32像素大小的,因此放大来看,它们都呈现出颗粒状。但是对卷积神经网络来说,它看到的不是颗粒,而是数据。
-
使用ImageDataGenerator函数创建一个图像生成器
用Keras进行图像数据的扩充是非常简单的,在这里,我们应该感谢Jason Brownlee,因为是他给我们提供了一个非常全面、到位的Keras图像扩充教程。图象扩充的过程如下:首先,我们需要使用 ImageDataGenerator()函数来创建一个图像生成器,并且输入一系列描述图像更改行为的参数;之后,我们将在这个图像生成器中执行fit()函数,它将会一批一批地对图像进行更改。在默认情况下,图像的更改是任意的,所以并不是所有图像每次都会被更改。你还可以用 keras.preprocessing 函数将扩充的图像导出到一个文件夹,以便建立一个更庞大的扩充图像数据集。
在本文中,我们将看一些更直观、有趣的扩充图像。你可以在Keras文件中查看所有的ImageDataGenerator参数,以及keras.preprocessing中的其他方法。
-
任意地旋转图像
# Rotate images by 90 degrees
datagen = ImageDataGenerator(rotation_range=90)# fit parameters from data
datagen.fit(x_train)# Configure batch size and retrieve one batch of images
for X_batch, y_batch in datagen.flow(x_train, y_train, batch_size=9):
# Show 9 images
for i in range(0, 9):
pyplot.subplot(330 + 1 + i)
pyplot.imshow(X_batch[i].reshape(img_rows, img_cols, 3))
# show the plot
pyplot.show()
break

-
垂直翻转图片
# Flip images vertically
datagen = ImageDataGenerator(vertical_flip=True)# fit parameters from data
datagen.fit(x_train)# Configure batch size and retrieve one batch of images
for X_batch, y_batch in datagen.flow(x_train, y_train, batch_size=9):
# Show 9 images
for i in range(0, 9):
pyplot.subplot(330 + 1 + i)
pyplot.imshow(X_batch[i].reshape(img_rows, img_cols, 3))
# show the plot
pyplot.show()
break

水平翻转图片同样是为分类器生成更多数据的一种经典方式。这么做非常简单,但是我在这里省略了代码和图像,是因为我们在没有看到原始图像的情况下,无法判断一张猫狗的图像是否被水平翻转了。
-
将图像垂直或水平移动20%
# Shift images vertically or horizontally
# Fill missing pixels with the color of the nearest pixel
datagen = ImageDataGenerator(width_shift_range=.2,
height_shift_range=.2,
fill_mode='nearest')# fit parameters from data
datagen.fit(x_train)# Configure batch size and retrieve one batch of images
for X_batch, y_batch in datagen.flow(x_train, y_train, batch_size=9):
# Show 9 images
for i in range(0, 9):
pyplot.subplot(330 + 1 + i)
pyplot.imshow(X_batch[i].reshape(img_rows, img_cols, 3))
# show the plot
pyplot.show()
-
break直方图均衡法
直方图均衡,即取一张低对比度图像,并提高图像中最亮和最暗部分之间的对比度,以找出阴影的细微差别,并创建一个更高对比度的图像。使用这个方法所产生的结果相当惊人,尤其是针对那些灰度图像。以下是一些例子:

https://www.bruzed.com/2009/10/contrast-stretching-and-histogram-equalization/
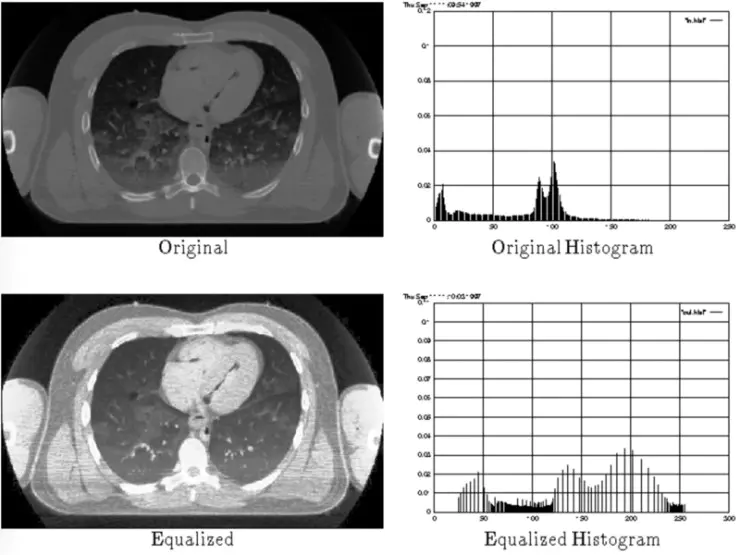
http://www-classes.usc.edu/engr/ee-s/569/qa2/Histogram%20Equalization.htm
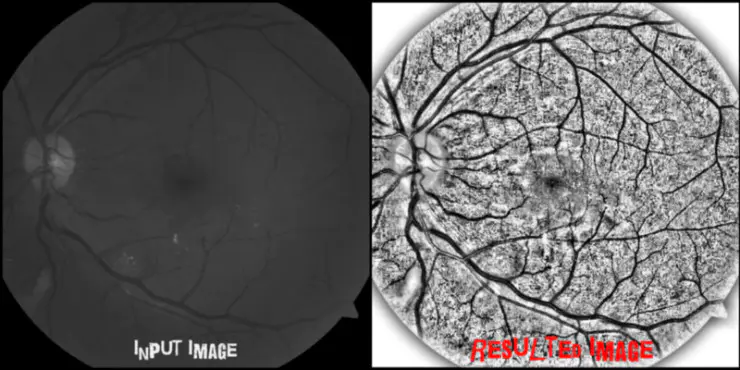
https://studentathome.wordpress.com/2013/03/27/local-histogram-equalization/
在本文中,我们将讨论三种用于提高图像对比度的图像扩充方法。这些方法有时也被称作“直方图拉伸”,因为它们会使用像素强度的分布,并扩展这些分布以适应更大范围的值,从而提高图像中最亮和最暗部分之间的对比度。
-
直方图均衡
直方图均衡法通过检测图像的像素强度分布,并绘制出一个像素强度直方图,从而提高图像的对比度。之后,这个直方图的分布会被进行分析,如果分析结果显示还有未被利用的像素亮度范围,那么这个直方图就会被“扩展”,以涵盖这些未被利用的范围。然后直方图将被“投射”到图像上,以提高图像的整体对比度。
-
对比度扩展
“对比度扩展”的过程首先是分析图像中的像素强度分布,然后重新调节图像,使图像能够涵盖在2%至98%之间的所有像素强度。
-
自适应均衡
在直方图计算方面,“自适应均衡”与常规的直方图均衡有很大的区别。常规的直方图均衡法中,每个被计算的直方图都与图像中的一个部分相对应;但是,它有着在非正常图像部分过度扩充噪声的趋势。
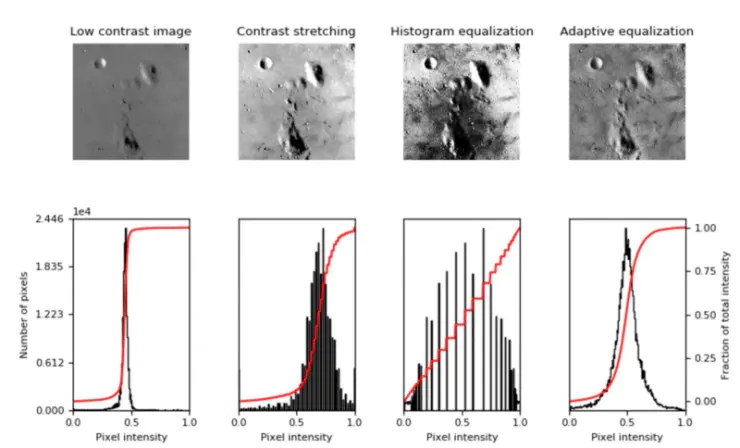
下面的代码来自于sci-kit图像库的文件。为了使这些代码能够在我们cifar10数据集的第一张图像上执行以上三种图像扩充,我们对代码进行了转换和修改。首先,我们将输入sic-kit图像库中的必要单元,然后对sci-kit图像文件中的代码进行修改和调整,以便查看数据集第一张图片的扩充图像集。
# Import skimage modules
from skimage import data, img_as_float
from skimage import exposure# Lets try augmenting a cifar10 image using these techniques
from skimage import data, img_as_float
from skimage import exposure# Load an example image from cifar10 dataset
img = images[0]# Set font size for images
matplotlib.rcParams['font.size'] = 8# Contrast stretching
p2, p98 = np.percentile(img, (2, 98))
img_rescale = exposure.rescale_intensity(img, in_range=(p2, p98))# Histogram Equalization
img_eq = exposure.equalize_hist(img)# Adaptive Equalization
img_adapteq = exposure.equalize_adapthist(img, clip_limit=0.03)#### Everything below here is just to create the plot/graphs ####
# Display results
fig = plt.figure(figsize=(8, 5))
axes = np.zeros((2, 4), dtype=np.object)
axes[0, 0] = fig.add_subplot(2, 4, 1)
for i in range(1, 4):
axes[0, i] = fig.add_subplot(2, 4, 1+i, sharex=axes[0,0], sharey=axes[0,0])
for i in range(0, 4):
axes[1, i] = fig.add_subplot(2, 4, 5+i)ax_img, ax_hist, ax_cdf = plot_img_and_hist(img, axes[:, 0])
ax_img.set_title('Low contrast image')y_min, y_max = ax_hist.get_ylim()
ax_hist.set_ylabel('Number of pixels')
ax_hist.set_yticks(np.linspace(0, y_max, 5))ax_img, ax_hist, ax_cdf = plot_img_and_hist(img_rescale, axes[:, 1])
ax_img.set_title('Contrast stretching')ax_img, ax_hist, ax_cdf = plot_img_and_hist(img_eq, axes[:, 2])
ax_img.set_title('Histogram equalization')ax_img, ax_hist, ax_cdf = plot_img_and_hist(img_adapteq, axes[:, 3])
ax_img.set_title('Adaptive equalization')ax_cdf.set_ylabel('Fraction of total intensity')
ax_cdf.set_yticks(np.linspace(0, 1, 5))# prevent overlap of y-axis labels
fig.tight_layout()
plt.show()
Here are the modified images of a low contrast cat from the cifar10 dataset. As you can see, the results are not as striking as they might be with a low contrast grayscale image, but still help improve the quality of the images.
下面这张图是一张修改后的图像,是由cifar10数据集中的一张对比度较低的猫咪图片修改得到的。正如你所看到的,最后修改的图像成果可能并不像在低对比度灰度图像中得到的图像成果那么令人惊艳,但总的来说图像的画质还是得到了提高。
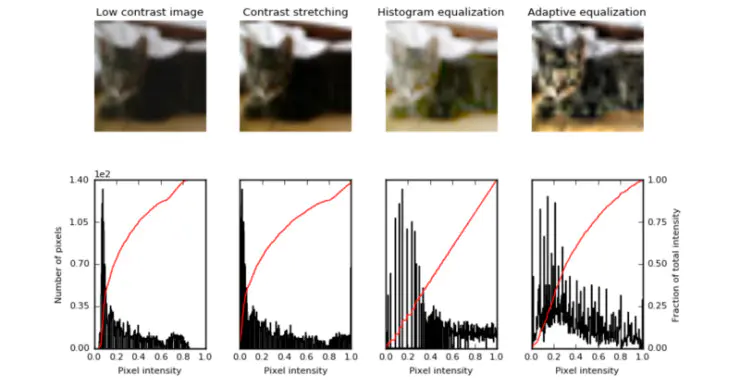
-
修改Keras.preprocessing以启用“直方图均衡法”
现在,我们已经成功地修改了cifar10数据集中的一张图像,我们接下来将要讨论如何调整或改变keras.preprocessing图像文件,从而执行这些不同的直方图修改方法,就像我们利用ImageDataGenerator()函数进行keras图像扩充一样。以下是我们将采取的几个步骤:
-
步骤概述
-
找出keras.preprocessing image py文件
-
把image py文件复制到你的文件或者笔记本上。
-
给每个均衡方法添加一个属性到ImageDataGenerator()init函数中。
-
把“IF”的表达语句添加到随即转换的方法中,这样,我们在使用datagenfit()函数的时候,图像扩充就会被执行。
对keras.preprocessing的图像py文件进行修改和调整的最简单的方式之一就是将文件中的内容复制、粘贴到我们的代码中。这么做的好处是省略了我们下一个输入文件内容的步骤。你可以点击此处查看github上的图像文件。但是,为了确保你拿到的文件是之前输入的文件的相同版本,你最好取你的机器上已有的图像文件。
运行print(keras._file_)将会打印出你机器上的keras库的路径,其路径(针对IMac用户)大致如下:
/usr/local/lib/python3.5/dist-packages/keras/__init__.pyc
这给我们提供了本机机器上的路径,沿着路径导航,然后进入preprocessing文件夹;在preprocessing文件夹中你就会看到图像py文件,你可以将其中的内容复制到你的代码中。这个文件有点长,但对于初学者来说,这应该是最简单的方法了。
-
编辑图像
你可以在图片顶部添加一行注释:from..import backend as K
到这里,你还需要再次检查,以确保你输入的是必须的scikit-image单元,这样复制的image.py才能识别出。
from skimage import data, img_as_float
from skimage import exposure
现在,我们需要给ImageDataGenerator类的方法添加六行代码,这样它就有三个属性来表示我们将要添加的图像扩充类型。下面的代码是从我现在的image.py中复制得来的:
def __init__(self,
contrast_stretching=False, #####
histogram_equalization=False,#####
adaptive_equalization=False, #####
featurewise_center=False,
samplewise_center=False,
featurewise_std_normalization=False,
samplewise_std_normalization=False,
zca_whitening=False,
rotation_range=0.,
width_shift_range=0.,
height_shift_range=0.,
shear_range=0.,
zoom_range=0.,
channel_shift_range=0.,
fill_mode=’nearest’,
cval=0.,
horizontal_flip=False,
vertical_flip=False,
rescale=None,
preprocessing_function=None,
data_format=None):
if data_format is None:
data_format = K.image_data_format()
self.counter = 0
self.contrast_stretching = contrast_stretching, #####
self.adaptive_equalization = adaptive_equalization #####
self.histogram_equalization = histogram_equalization #####
self.featurewise_center = featurewise_center
self.samplewise_center = samplewise_center
self.featurewise_std_normalization = featurewise_std_normalization
self.samplewise_std_normalization = samplewise_std_normalization
self.zca_whitening = zca_whitening
self.rotation_range = rotation_range
self.width_shift_range = width_shift_range
self.height_shift_range = height_shift_range
self.shear_range = shear_range
self.zoom_range = zoom_range
self.channel_shift_range = channel_shift_range
self.fill_mode = fill_mode
self.cval = cval
self.horizontal_flip = horizontal_flip
self.vertical_flip = vertical_flip
self.rescale = rescale
self.preprocessing_function = preprocessing_function
下面的random_transform()函数呼应我们之前传输至ImageDataGenerator函数的参数。如果我们把“对比度扩展”、“自适应均衡”或“直方图均衡”的参数设置为“True”,那么当我们调用ImageDataGenerator函数的时候,random_transform()函数就会执行所需的图像扩充。
def random_transform(self, x):
img_row_axis = self.row_axis - 1
img_col_axis = self.col_axis - 1
img_channel_axis = self.channel_axis - 1# use composition of homographies
# to generate final transform that needs to be applied
if self.rotation_range:
theta = np.pi / 180 * np.random.uniform(-self.rotation_range, self.rotation_range)
else:
theta = 0 if self.height_shift_range:
tx = np.random.uniform(-self.height_shift_range, self.height_shift_range) * x.shape[img_row_axis]
else:
tx = 0 if self.width_shift_range:
ty = np.random.uniform(-self.width_shift_range, self.width_shift_range) * x.shape[img_col_axis]
else:
ty = 0 if self.shear_range:
shear = np.random.uniform(-self.shear_range, self.shear_range)
else:
shear = 0 if self.zoom_range[0] == 1 and self.zoom_range[1] == 1:
zx, zy = 1, 1
else:
zx, zy = np.random.uniform(self.zoom_range[0], self.zoom_range[1], 2)transform_matrix = None
if theta != 0:
rotation_matrix = np.array([[np.cos(theta), -np.sin(theta), 0],
[np.sin(theta), np.cos(theta), 0],
[0, 0, 1]])
transform_matrix = rotation_matrix if tx != 0 or ty != 0:
shift_matrix = np.array([[1, 0, tx],
[0, 1, ty],
[0, 0, 1]])
transform_matrix = shift_matrix if transform_matrix is None else np.dot(transform_matrix, shift_matrix) if shear != 0:
shear_matrix = np.array([[1, -np.sin(shear), 0],
[0, np.cos(shear), 0],
[0, 0, 1]])
transform_matrix = shear_matrix if transform_matrix is None else np.dot(transform_matrix, shear_matrix) if zx != 1 or zy != 1:
zoom_matrix = np.array([[zx, 0, 0],
[0, zy, 0],
[0, 0, 1]])
transform_matrix = zoom_matrix if transform_matrix is None else np.dot(transform_matrix, zoom_matrix) if transform_matrix is not None:
h, w = x.shape[img_row_axis], x.shape[img_col_axis]
transform_matrix = transform_matrix_offset_center(transform_matrix, h, w)
x = apply_transform(x, transform_matrix, img_channel_axis,
fill_mode=self.fill_mode, cval=self.cval) if self.channel_shift_range != 0:
x = random_channel_shift(x, self.channel_shift_range, img_channel_axis) if self.horizontal_flip:
if np.random.random() < 0.5:
x = flip_axis(x, img_col_axis) if self.vertical_flip:
if np.random.random() < 0.5:
x = flip_axis(x, img_row_axis)
if self.contrast_stretching: #####
if np.random.random() < 0.5: #####
p2, p98 = np.percentile(x, (2, 98)) #####
x = exposure.rescale_intensity(x, in_range=(p2, p98)) #####
if self.adaptive_equalization: #####
if np.random.random() < 0.5: #####
x = exposure.equalize_adapthist(x, clip_limit=0.03) #####
if self.histogram_equalization: #####
if np.random.random() < 0.5: #####
x = exposure.equalize_hist(x) #####
return x
现在,所有必备的代码都已经准备就绪了,那么我们就可以调用ImageDataGenerator()函数执行直方图修改的方法了。当我们将所有的参数设置为True后,部分图像就会变成这样:
# Initialize Generator
datagen = ImageDataGenerator(contrast_stretching=True, adaptive_equalization=True, histogram_equalization=True)# fit parameters from data
datagen.fit(x_train)# Configure batch size and retrieve one batch of images
for x_batch, y_batch in datagen.flow(x_train, y_train, batch_size=9):
# Show the first 9 images
for i in range(0, 9):
pyplot.subplot(330 + 1 + i)
pyplot.imshow(x_batch[i].reshape(img_rows, img_cols, 3))
# show the plot
pyplot.show()
break

我不推荐在任何给定的数据集中将一个以上的参数设置为True,你需要确保你的数据集实验有助于你提高分类器的准确性。对于彩色图像,我发现“对比度扩展”的成效优于“直方图修改”或“自适应均衡”的成效。
-
训练并且验证你的keras卷积神经网络
最后一步,训练我们的卷积神经网络,并使用 model.fit_generator() 函数验证这个模型,从而实现在扩充图像上的神经网络的训练和验证。
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2Dbatch_size = 64
num_classes = 2
epochs = 10model = Sequential()
model.add(Conv2D(4, kernel_size=(3, 3),activation='relu',input_shape=input_shape))
model.add(Conv2D(8, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(16, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(2, activation='softmax'))
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])datagen.fit(x_train)
history = model.fit_generator(datagen.flow(x_train, y_train, batch_size=batch_size),
steps_per_epoch=x_train.shape[0] // batch_size,
epochs=20,
validation_data=(x_test, y_test))

雷锋网特约稿件,未经授权禁止转载。详情见转载须知。