利用FFMPEG与X264实现帧内预测模式的隐写算法(2)
前言
由于这个领域我以后不打算深入,而且课题也只是交个毕设而已,所以代码中有些地方图方便直接开了全局变量,这样破坏了ffmpeg原有的封装结构。这门这代码只作学习和理论实践使用,千万别拿这个直接去投入开源使用,如果想跟着我改的朋友也请给原ffmpeg代码留好备份。所有代码会等毕设结题后公开。
正文
在上一篇文章中我们介绍了H264相关的知识和基于帧内预测模式的算法。这一片我们会具体在ffmpeg与x264中实现上一篇文章中2.4中所描述的算法
1. ffmpeg与x264对于一帧的处理
这个ffmpeg与x264的更多内容请参考雷霄骅的博客,我们这里直接讲需要了解的结构体和函数。
1.1 ffmpeg中几个结构体的概念
AVFormatContext:记录多媒体文件格式的相关信息,一般来说对应一个多媒体文件的信息。
AVInputFormat/AVOutputFormat:描述一种多媒体格式的信息,一般来说对应一种多媒体文件的信息,如MP4,FLV,MP3等。
AVStream:多媒体文件中的一段多媒体流。比如我们一般的视频文件里面有视频流,音频流,甚至是字幕流等等,每个流都会对应一个AVCodecContext。
AVCodecContext:这是个比较重要的结构体,比较抽象,大致记录的编解码器的一些特征,比如有几个声道,视频宽高等等。还会存一部分需要编解码的数据。可以看做视频画面与编解码器中间的一个过渡用的结构体。每个AVCodecContext都对应一个AVCodec
AVCodec:实实在在的被实例化编解码器。其中包含编解码类别,需要编解码的信息,编解码所用的函数指针等等。
AVFrame:视频中一帧画面,包括画面的yuv信息,以及对应需要播放的音频或字母等,用于直接播放的数据结构。
AVPacket:一个基本的数据包,可以解码成AVFrame。一个AVFrame可能由多个AVPacket解码组成,但是一个AVPacket最多包含一个AVFrame
1.2 部分函数调用结构
int avcodec_encode_video2(AVCodecContext *avctx, AVPacket *avpkt, const AVFrame *frame, int *got_packet_ptr):
将一个AVFrame编码成AVPacket,优先装进AVCodecContext。如果AVCodecContet装不下了,会弹出一个AVPacketd到avpkt,并将got_packet_ptr置1。这是最外层的编码API函数。
int AVCodecContext*->codec->encode2(AVCodecContext *avctx, AVPacket *avpkt, const AVFrame *frame, int *got_packet_ptr)
位于avcodec_encode_video2中,通过 ret = avctx->codec->encode2(avctx, avpkt, frame, got_packet_ptr);调用
这个是AVCodecContext中对应Codec的编码函数,encode2是一个函数指针,指向编码函数。
实际上就是将视频信息交给编码器后调用编码器的编码函数。
static int X264_frame(AVCodecContext *ctx, AVPacket *pkt, const AVFrame *frame, int *got_packet)
这个其实就是AVCodecContext*->codec->encode2所指向的函数(编码器为H264编码器)
可以发现这个函数位于libx264.c中,尚且还是在ffmpeg中的函数,但是在libx264.c中include的头文件中已经发现了x264的头文件,也就是说这里就是ffmpeg调用x264的分界点了。
int x264_encoder_encode( x264_t *h, x264_nal_t **pp_nal, int *pi_nal, x264_picture_t *pic_in, x264_picture_t *pic_out )
x264的最外层API,用于将一帧画面编码成H264格式的一帧,这个函数很长。我们只直在里面找到x264_slices_write()这个函数
x264_slices_write():一边编码一边写入帧的数据(与之对应的还有些文件头和写文件尾的函数)
x264_stack_align( x264_slice_write, h ):这是x264_slices_write()中的一句话,可以理解成x264_slice_write(h)。函数原型是static intptr_t x264_slice_write( x264_t *h ),这样写是为了字节对齐。这个函数写一帧的数据。在里面我们能找到x264_macroblock_analyse( h );这句话
void x264_macroblock_analyse( x264_t *h ) : 这个函数用于分析一个16*16的宏块。我会详细讲一讲这个函数。
1.3 void x264_macroblock_analyse( x264_t *h )
我们会发现其中有个x264_mb_analysis_t类型,这个类型用于存储分析结果,对于一个宏块我们需要分析的内容有,该16*16宏块如何划分,划分之后每个更小的宏块用什么IPM预测等等信息。
我们能发现其中有一行Do the analysis的注释。
在这行注释上面,主要设置了这行的量化系数。我们主要分析这行下面的一部分。

通过VS将代码折叠我们能更好地观察它的结构,这里首先判断这宏块属于哪种帧,对于每种帧,用具体不同的策略来分析,将分析结果保存在analysis中,最后分析完将分析结果反馈给出来决定这个帧之后如何编码
所以如果我们要篡改其中的IPM,就需要篡改它的analysis,使其最后按照我们指定的IPM去进行编码,这里我们继续展开SLICE_TYPE_I的情况
if( h->sh.i_type == SLICE_TYPE_I )
{
intra_analysis:
if( analysis.i_mbrd )
x264_mb_init_fenc_cache( h, analysis.i_mbrd >= 2 );
if( analysis.i_mbrd )
x264_intra_rd( h, &analysis, COST_MAX );
i_cost = analysis.i_satd_i16x16;
h->mb.i_type = I_16x16;
COPY2_IF_LT( i_cost, analysis.i_satd_i4x4, h->mb.i_type, I_4x4 );
COPY2_IF_LT( i_cost, analysis.i_satd_i8x8, h->mb.i_type, I_8x8 );
if( analysis.i_satd_pcm < i_cost )
h->mb.i_type = I_PCM;
else if (analysis.i_mbrd >= 2)
{
x264_intra_rd_refine(h, &analysis);
}
}注:COPY2_IF_LT是个宏定义,相当于Copy if little,ji如果新的划分方法更优,就copy成新的方法。
其中x264_mb_analyse_intra(), x264_intra_rd(), x264_intra_rd_refine(),都是用来计算不同划分方式的编码代价的。其中I_16x16表示该宏块不划分,I_4x4表示宏块划分成16个4*4宏块,I_8x8表示划分成4个8*8宏块。
当SLICE_TYPE_I这个分支执行完,马上代码就会将analysis中的分析结果去更新这一帧的编码方式,所以如果要实施信息嵌入,就要在这这个分支结构的最后面,将analysis中的数据修改掉。
2. 隐藏信息的信息嵌入
当时做信息嵌入的时候我还是考虑了类的封装性,所以通过增加AVCodecContext与x264_t的属性,将隐写的信息从最顶层传进来,不过这么做由于修改了结构体AVCodecContext,需要重编译整个ffmpeg工程,非常耗时,所以课题后续的代码修改为了图方便我就全部采用全局变量了。这里我还是介绍一下如何通过修改将参数从最顶层传递下来。
2.1 修改AVCodecContext
这个结构体的定义在avcodec.h中,我需要在其中加入4个参数,int x264_stegano_Mode,int x264_embbits,FILE* x264_stegano_ioFile,FILE* x264_stegano_logFile
分别表示嵌入模式,填入比特数,嵌入用输入文件,嵌入日志文件。
2.2 修改x264_t
这个是x264中的结构体,定义在common/common.h中,我们一样要为其添加这四个属性
2.3 重编译x264与ffmpeg
不要忽略这个过程,虽然改完头文件直接去执行make发现它根本什么都没编译,然后单步运行也能找到这几个属性,但是实际运行起来却会遇到很多问题。主要原因是有很多申请内存时用到了sizeof(AVCodecContext)和sizeof(x264_t),sizeof其实并不是函数,它在编译成汇编的过程中直接会被转义成具体数值,如果不重新编译整个工程,每个调用sizeof的地方其实都出错了。
重编译指令
make clean
make
make install
2.4 在ffmpeg与x264间添加函数接口
修改完AVCodecContext后很容易就把参数从最外层传递到libx264.c中,但是发现了一个问题就是这些参数不能直接赋值给x264_t的结构体,原因是在x264.h中只申明了x264_t这个结构体,并没有具体的定义,也就是说在libx264.c中是无法得到x264_t的成员的。
解决方法就是通过参数传递,我们在x264.h中添加int x264_stegano_parameters(x264_t,int,FILE*,FILE*)的函数接口作为隐写信息的传入,再添加一个int x264_getemb()用于获取已经嵌入的比特数。
我们在x264的encoder/encoder.c中定义这两个函数
int x264_stegano_parameters(x264_t* h, int mode, FILE* inp, FILE* log)
{
h->stegano_Mode = mode;
h->stegano_ioFile = inp;
h->stegano_logFile = log;
if (inp == NULL) h->stegano_Mode = 0;
return 0;
}
int x264_getemb(x264_t* h)
{
return h->embbits;
}然后在libx264.c的X264_frame中在x264_encoder_encode()前后添加上隐写参数设置和隐写信息获取。
x264_stegano_parameters(x4->enc, ctx->x264_Stegano_Mode, ctx->x264_Stegano_inpFile, ctx->x264_Stegano_logFile);
do {
if (x264_encoder_encode(x4->enc, &nal, &nnal, frame? &x4->pic: NULL, &pic_out) < 0)
return AVERROR_EXTERNAL;
ret = encode_nals(ctx, pkt, nal, nnal);
if (ret < 0)
return ret;
} while (!ret && !frame && x264_encoder_delayed_frames(x4->enc));
ctx->embbits = x264_getemb(x4->enc);这样我们就把隐写相关参数从最表层传递到x264中了
2.5 提取编码代价
x264_mb_analyse_intra(), x264_intra_rd(), x264_intra_rd_refine()这三个函数是用来计算编码代价的,详细的这里我们就略过了,这里只讲其中处理4*4宏块的地方,并且如何把4*4宏块的编码代价提出来。我们首先开一个静态全局变量imp_satd_list[]用来存储9中预测模式的编码代价。
2.5.1 x264_mb_analyse_intra()

这里结构非常清楚,我们直接进入4*4的分支

看到其中idx的循环,这就是遍历16个4*4宏块的地方。我们点开其中继续看,找到其中如下代码段
if( i_best > 0 )
{
for( ; *predict_mode >= 0; predict_mode++ )
{
int i_satd;
int i_mode = *predict_mode;
if( h->mb.b_lossless )
x264_predict_lossless_4x4( h, p_dst_by, 0, idx, i_mode );
else
h->predict_4x4[i_mode]( p_dst_by );
i_satd = h->pixf.mbcmp[PIXEL_4x4]( p_dst_by, FDEC_STRIDE, p_src_by, FENC_STRIDE );
if( i_pred_mode == x264_mb_pred_mode4x4_fix(i_mode) )
{
i_satd -= lambda * 3;
if( i_satd <= 0 )
{
i_best = i_satd;
a->i_predict4x4[idx] = i_mode;
break;
}
}
COPY2_IF_LT( i_best, i_satd, a->i_predict4x4[idx], i_mode );
}
}其中predict_mode遍历当前宏块可用的预测模式,预测完之后的编码代价存在i_satd中
所以我们在COPY那句话前或后加上一句
imp_satd_list[idx][x264_mb_pred_mode4x4_fix(i_mode)] = i_satd;2.5.2 x264_intra_rd()
这个函数我并没有看懂,如果有看懂的大神可以留言。
refine函数中又把编码代价全部重新算了一遍,所以我认为这个函数也并不是那么重要,可能只是一个过渡性质的函数。所以编码代价留到refine函数中一并提出。
2.5.3 x264_intra_rd_refine()

大结构也非常清楚,我们直接看I_4x4的这个分支
if( h->mb.i_type == I_4x4 )
{
pixel4 pels[3][4] = {{0}}; // doesn't need initting, just shuts up a gcc warning
int nnz[3] = {0};
for( int idx = 0; idx < 16; idx++ )
{
pixel *dst[3] = {h->mb.pic.p_fdec[0] + block_idx_xy_fdec[idx],
h->mb.pic.p_fdec[1] + block_idx_xy_fdec[idx],
h->mb.pic.p_fdec[2] + block_idx_xy_fdec[idx]};
i_best = COST_MAX64;
const int8_t *predict_mode = predict_4x4_mode_available( a->b_avoid_topright, h->mb.i_neighbour4[idx], idx );
if( (h->mb.i_neighbour4[idx] & (MB_TOPRIGHT|MB_TOP)) == MB_TOP )
for( int p = 0; p < plane_count; p++ )
/* emulate missing topright samples */
MPIXEL_X4( dst[p]+4-FDEC_STRIDE ) = PIXEL_SPLAT_X4( dst[p][3-FDEC_STRIDE] );
for( ; *predict_mode >= 0; predict_mode++ )
{
int i_mode = *predict_mode;
i_satd = x264_rd_cost_i4x4( h, a->i_lambda2, idx, i_mode );
imp_satd_list[idx][x264_mb_pred_mode4x4_fix(i_mode)] = i_satd;
if( i_best > i_satd )
{
a->i_predict4x4[idx] = i_mode;
i_best = i_satd;
for( int p = 0; p < plane_count; p++ )
{
pels[p][0] = MPIXEL_X4( dst[p]+0*FDEC_STRIDE );
pels[p][1] = MPIXEL_X4( dst[p]+1*FDEC_STRIDE );
pels[p][2] = MPIXEL_X4( dst[p]+2*FDEC_STRIDE );
pels[p][3] = MPIXEL_X4( dst[p]+3*FDEC_STRIDE );
nnz[p] = h->mb.cache.non_zero_count[x264_scan8[idx+p*16]];
}
}
}
for( int p = 0; p < plane_count; p++ )
{
MPIXEL_X4( dst[p]+0*FDEC_STRIDE ) = pels[p][0];
MPIXEL_X4( dst[p]+1*FDEC_STRIDE ) = pels[p][1];
MPIXEL_X4( dst[p]+2*FDEC_STRIDE ) = pels[p][2];
MPIXEL_X4( dst[p]+3*FDEC_STRIDE ) = pels[p][3];
h->mb.cache.non_zero_count[x264_scan8[idx+p*16]] = nnz[p];
}
h->mb.cache.intra4x4_pred_mode[x264_scan8[idx]] = a->i_predict4x4[idx];
}
}2.6 修改IPM
前面我们说到,要修改IPM的地方是在analysis去更新当前帧之前。
这里我们先来看一下x264自带的几个比较细节的相关函数和数据结构:
x264_mb_predict_intra4x4_mode(x264_t*,int): 用于返回当前宏块的MPM(预测的IPM)
x264_mb_pred_mode4x4_fix(x):其实是个宏定义,在x264中如果宏块在边界上,部分预测模式不可用,返回
x264_mb_predict_intra4x4_mode()返回值可能是9~12中的值。通过这个宏定义使它变成模式2,即取平均值模式。
x264_scan8[40]:x264中如果将16*16的宏块分割成16个4*4的宏块,这16个4*4的宏块的编号如下所示
0 1 4 5
2 3 6 7
8 9 12 13
10 11 14 15
显然这样编号要获得上下左右的宏块并不是很容易,而且0,1,4,5,2,8,10等宏块获取边界外的信息十分麻烦,所以x264通过x264_scan8[]这个数组作转换,具体转换策略可以参考这篇文章,总之转换后使得获取上下左右的宏块十分便利,并且有多余空间存储宏块外的信息。
然后讲几个我自己加的函数:
int addemb(int):函数中用一个静态全局变量记录当前已经嵌入的比特数,传进来的参数为嵌入比特数的增加量,返回值为当前嵌入比特数。
int addemb(int x)
{
static int emb = 0;
emb += x;
return emb;
}
int getbit(FILE*):从文件中获取一个比特,用静态全局变量作为数据缓冲。其中left和buf均为静态全局变量
int getbit(FILE* fin)
{
FILE* inpFile = NULL;
if (!inpFile) {
inpFile = fin;
}
if (feof(inpFile)) return -1;
if (left == 0) { buf = getc(inpFile); if (buf == EOF) return -1; left = 8; }
int ret = buf & 1;
left--;
buf >>= 1;
return ret;
}
接着我们来看下面这段如何修改IPM
首先在每次提取编码代价前要把imp_satd_list清空
intra_analysis:
if( analysis.i_mbrd )
x264_mb_init_fenc_cache( h, analysis.i_mbrd >= 2 );
memset(imp_satd_list, 0, sizeof(imp_satd_list));
x264_mb_analyse_intra( h, &analysis, COST_MAX );
if( analysis.i_mbrd )
x264_intra_rd( h, &analysis, COST_MAX );
i_cost = analysis.i_satd_i16x16;
h->mb.i_type = I_16x16;
COPY2_IF_LT( i_cost, analysis.i_satd_i4x4, h->mb.i_type, I_4x4 );
COPY2_IF_LT( i_cost, analysis.i_satd_i8x8, h->mb.i_type, I_8x8 );
if( analysis.i_satd_pcm < i_cost )
h->mb.i_type = I_PCM;
else if (analysis.i_mbrd >= 2)
{
memset(imp_satd_list, 0, sizeof(imp_satd_list));
x264_intra_rd_refine(h, &analysis);
}然后开始修改IPM:
checklist用于保存上一篇文章中描述的四个候选预测模式。
其中NUM4ARR的将后四个只分别赋给check_list[0-3]
if (h->stegano_Mode == 1)
{
x264_analyse_update_cache(h, &analysis);
if (inpFile == NULL)
{
inpFile = h->stegano_inpFile;
if (ftell(inpFile) == 0) addemb(-addemb(0));
}
if (h->mb.i_type == I_4x4)
{
if (h->mb.i_mb_x > 0 && h->mb.i_mb_y > 0)
{
int i = 0;
for (i = 0; i < 16; i++)
{
int i_pre_mode = x264_mb_predict_intra4x4_mode(h, i);
if (flog == NULL) flog = h->stegano_logFile;
if (i_pre_mode == x264_mb_pred_mode4x4_fix(analysis.i_predict4x4[i])) continue;
int x = getbit(inpFile), y;
if (x == -1) continue;
if (x == 0)
{
if (i_pre_mode == 0) NUM4ARR(check_list, 1, 2, 3, 4);
else if (i_pre_mode == 1) NUM4ARR(check_list, 0, 2, 3, 6);
else if (i_pre_mode == 2) NUM4ARR(check_list, 0, 1, 3, 4);
else if (i_pre_mode == 3) NUM4ARR(check_list, 0, 1, 2, 4);
else if (i_pre_mode == 4) NUM4ARR(check_list, 0, 1, 2, 3);
else if (i_pre_mode == 5) NUM4ARR(check_list, 0, 1, 2, 3);
else if (i_pre_mode == 6) NUM4ARR(check_list, 0, 1, 2, 3);
else if (i_pre_mode == 7) NUM4ARR(check_list, 0, 1, 2, 4);
else if (i_pre_mode == 8) NUM4ARR(check_list, 0, 1, 2, 3);
}
else
{
if (i_pre_mode == 0) NUM4ARR(check_list, 5, 6, 7, 8);
else if (i_pre_mode == 1) NUM4ARR(check_list, 4, 5, 7, 8);
else if (i_pre_mode == 2) NUM4ARR(check_list, 5, 6, 7, 8);
else if (i_pre_mode == 3) NUM4ARR(check_list, 5, 6, 7, 8);
else if (i_pre_mode == 4) NUM4ARR(check_list, 5, 6, 7, 8);
else if (i_pre_mode == 5) NUM4ARR(check_list, 4, 6, 7, 8);
else if (i_pre_mode == 6) NUM4ARR(check_list, 4, 5, 7, 8);
else if (i_pre_mode == 7) NUM4ARR(check_list, 3, 5, 6, 8);
else if (i_pre_mode == 8) NUM4ARR(check_list, 4, 5, 6, 7);
}
int m = 0,j;
for (j = 1; j < 4; j++)
if (imp_satd_list[i][check_list[j]] != 0 &&
imp_satd_list[i][check_list[j]] < imp_satd_list[i][check_list[m]])
m = j;
analysis.i_predict4x4[i] = check_list[m];
h->mb.cache.intra4x4_pred_mode[x264_scan8[i]] = analysis.i_predict4x4[i];
addemb(1);
if (flog) fprintf(flog, "mbx=%d mby=%d idx=%d dir=%d pred=%d\n", h->mb.i_mb_x, h->mb.i_mb_y, i, check_list[m],i_pre_mode);
}
h->emb = addemb(0);
}
}
inpFile = NULL;
flog = NULL;
}相信如果理解了上一篇介绍算法的博客看懂这段代码不是太困难,需要强调一下的是这句话
h->mb.cache.intra4x4_pred_mode[x264_scan8[i]] = analysis.i_predict4x4[i];
由于修改了IPM会对预测MPM的产生影响,我们需要后续预测根据我修改后的进行预测。所以需要及时更新在h中的所有IPM。
本来是可以调用x264_analyse_update_cache()这个函数用于更新的,但是这样每次刷新整个宏块的IPM会大大降低效率,直接将当前这个宏块的信息更新进h。
3. 隐藏信息的信息提取
提取相比嵌入来说容易的多,因为全部是在ffmpeg下进行的,而且我们之前也已经将修改完了AVCodecContext这个类,这里我们将x264_embbits作为提取的比特数,FILE* x264_stegano_ioFile作为输出文件,一开始的函数调用其实和雷霄骅的博客写得不太相同,我们这里简单讲讲
3.1从最外层到I帧宏块处理
int avcodec_decode_video2(AVCodecContext *avctx, AVFrame *picture, int *got_picture_ptr, const AVPacket *avpkt)

然后发现这个函数什么都没做,直接调用了compat_decode
static int compat_decode(AVCodecContext *avctx, AVFrame *frame, int *got_frame, const AVPacket *pkt)
主要是一系列的参数检查以及总流程
其中会发现avcodec_send_packet()和avcodec_receive_frame()两个函数
解码总流程大致是:AVPacket---(sendpacket)--->AVCodecContext---(recieveframe)--->AVFrame
解码的过程其实是在sendpacket里面的,我们进去看这个函数
int attribute_align_arg avcodec_send_packet(AVCodecContext *avctx, const AVPacket *avpkt)
又是一系列发送AVPacket的检查,我们找到decode_receive_frame_internal()这个函数
static int decode_receive_frame_internal(AVCodecContext *avctx, AVFrame *frame)
找到这里,判断所用解码器是否有对一帧有特殊操作,如果没有会进到else这个分支中。

static int decode_simple_internal(AVCodecContext *avctx, AVFrame *frame)
找到这里,判断是否多线程解码,当然我没开多线程,所以进入else分支

static int h264_decode_frame(AVCodecContext *avctx, void *data, int *got_frame, AVPacket *avpkt)
这里开始和雷霄骅博客中描述的基本就一样了,而且后续受汇编优化影响单步调试不能很好进展,我们直接沿着这条调用路径找到h264_mb.c这个文件其中有这个函数
3.2获取隐藏信息
static av_always_inline void hl_decode_mb_predict_luma(const H264Context *h,
H264SliceContext *sl,
int mb_type, int simple,
int transform_bypass,
int pixel_shift,
const int *block_offset,
int linesize,
uint8_t *dest_y, int p)
参数非常多,大概看一眼结构
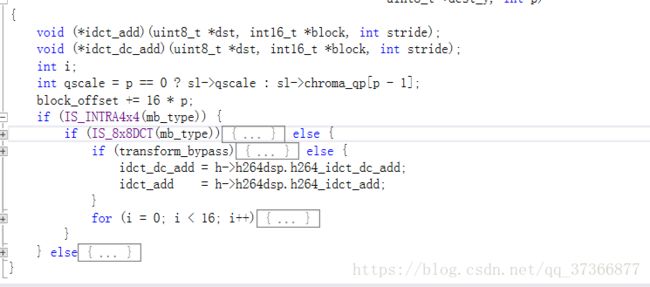
IS_INTRA4x4判断该16*16宏块是否被划分过,如果被划分过,判断是否为划分为8*8宏块。
所以我们直接找到IS_8x8DCT(mb_type)这个判断的else分支
找到其中的0-15的for循环
const int dir = sl->intra4x4_pred_mode_cache[scan8[i]];直接就把当前这个预测模式提取出来了,所以我们在这句话之后紧跟信息提取的代码
///////gcychange
AVCodecContext *avctx = h->avctx;
flog = avctx->x264_Stegano_logFile;
fout = avctx->x264_Stegano_inpFile;
if (flog&&sl->slice_type == AV_PICTURE_TYPE_I) fprintf(flog,
"%d %d %d %d %d\n",
sl->mb_x,
sl->mb_y,
i,
dir,
pred_intra_mode(h, sl, i));
if (avctx->x264_Stegano_Mode == 1 && getb <= avctx->embbits)
{
if (sl->slice_type == AV_PICTURE_TYPE_I)
{
static int flag = 0, flag1 = 0;
static int left = 0, buf = 0;
if (left >= 8)
{
//fprintf(fout, "%d ", buf & 255);
fputc(buf & 255, fout);
buf >>= 8;
left -= 8;
}
if (sl->mb_x > 0 && sl->mb_y > 0)
{
int i_pred_mode = pred_intra_mode(h, sl, i);
if (dir != i_pred_mode)
{
if (i_pred_mode == 0) NUM4ARR(zero_list, 1, 2, 3, 4);
else if (i_pred_mode == 1) NUM4ARR(zero_list, 0, 2, 3, 6);
else if (i_pred_mode == 2) NUM4ARR(zero_list, 0, 1, 3, 4);
else if (i_pred_mode == 3) NUM4ARR(zero_list, 0, 1, 2, 4);
else if (i_pred_mode == 4) NUM4ARR(zero_list, 0, 1, 2, 3);
else if (i_pred_mode == 5) NUM4ARR(zero_list, 0, 1, 2, 3);
else if (i_pred_mode == 6) NUM4ARR(zero_list, 0, 1, 2, 3);
else if (i_pred_mode == 7) NUM4ARR(zero_list, 0, 1, 2, 4);
else if (i_pred_mode == 8) NUM4ARR(zero_list, 0, 1, 2, 3);
char inlist = 0;
int j = 0;
for (j = 0; j < 4; j++) if (zero_list[j] == dir) inlist = 1;
if (inlist)
{
left++; getb++;
}
else
{
buf += (1 << left);
left++; getb++;
}
}
}
if (left >= 8)
{
fputc(buf & 255, fout);
buf >>= 8;
left -= 8;
}
}
}
/////////注:pred_intra_mode()是ffmpeg自带的用于计算MMP的函数
需要强调一下这里一定要带上对I帧的判断,因为非I帧中也有用该方法编码的宏块
到这里信息的嵌入和提取已经全部讲完了,外层封装一个带隐写的编解码器的代码暂时就不发了,有兴趣可以等我之后会上传的全部代码
最后
毕竟我还是一只看了视频编码不到一学期的菜鸟,如果有错欢迎指正。