python入门(五)实现统计《哈姆雷特》最多单词和《三国演义》人物出场次数
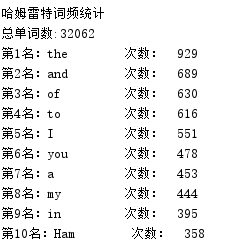
先看效果,我们的冠词"热"以929次高居榜首
核心知识
简单的文件读取
字典
列表
尤其是字典和列表,需要了解清楚才能理解代码
步骤
- 读取txt文件,并将所有的标点符号替换为空格
- 将文件分解成一个一个的单词
- 使用字典一个一个的复制单词作为键,遇到相同的键其对应的值就+1
- 将字典转化为列表,并按值大小从大到小排序
- 循环输出结果
代码
def getTxt():
# 打开相对路径,需要两个省略号点.表示本项目
txt = open("../assert/Hamlet.txt", "r").read()
txt.lower()
#取代标点符号
for i in "^……,"".#!@$%^&*|?/:;{}[]()~`<>_+=":
txt = txt.replace(i, " ")
return txt
hamlet = getTxt()
#将文本分割成单词
words = hamlet.split()
counts = {}
for word in words:
counts[word] = counts.get(word, 0) + 1
items = list(counts.items())
# 此时的items是键值对型列表,包含键和值作为一个元素,reverse=True表示从大到小,sort表示排列
items.sort(key=lambda x: x[1], reverse=True)
print("哈姆雷特词频统计")
print("总单词数:{:}".format(len(words)))
for i in range(10):
word, count = items[i]
print("第" + str(i + 1) + "名:{0:<10} 次数:{1:>5}".format(word, count))
看懂了上面的代码,对于《三国演义》也差不多,但我们需要回答两个问题
1、如何识别中文,并将他们分开?英文可以通过空格和标点,但中文往往是一堆字凑成一句话
2、如何从识别出的中文中区别出人名?
其实也很简单,站在前人的肩膀上
我们导入jieba库,它自动会有lcut()方法来帮我们
看一个例子
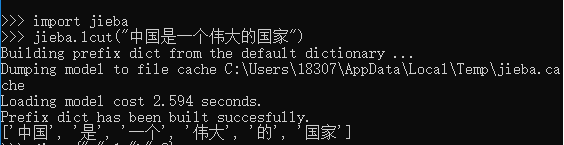
自动就分好了!
当然,这个库还有更强大的功能,这里我们只用来区别汉字
对于区别人名的问题,在我们会机器学习之前,就只能靠我们人工了,命名一个exclude列表,专门记录非人名却又排名前列的,然后去掉,多次运行代码,就行了……(突然有点low)
另外,三国里面一些人名有多种叫法,比如诸葛亮,孔明等,我们也要手动对排在前列的进行合并
# 三国演义
import jieba
def getSanguo():
txt = open("../assert/三国演义.txt", encoding="utf-8").read()
return txt
exclude = ["却说", "丞相", "二人", "不可", "荆州", "不能", "如此", "商议", "将军", "今日",
"军马", "如何", "军士", "主公", "左右", "次日", "大喜", "引兵", "天下", "东吴",
"于是", "魏兵", "人马", "都督", "不知", "不敢"]
words = jieba.lcut(getSanguo())
counts = {}
for word in words:
if len(word) == 1:
continue
reword = word
if word in ["孔明曰", "孔明"]:
reword = "诸葛亮"
elif word in ["玄德", "玄德曰"]:
reword = "刘备"
elif word in ["云长", "关公"]:
reword = "关羽"
elif word in ["子龙"]:
reword = "赵云"
elif word in ["孟德", "阿瞒", "孟德曰"]:
reword = "曹操"
counts[reword] = counts.get(reword, 0) + 1
for word in exclude:
del counts[word]
items = list(counts.items())
items.sort(key=lambda x: x[1], reverse=True)
for i in range(10):
word, count = items[i]
print("{:} {:}".format(word, count))
下面是输出结果(对出场短暂的周瑜居然排进前十感到惊讶!)
当然了,张飞,吕布的次数算少了,因为还没合并翼德,奉先这些~
诸葛亮 1363
刘备 1213
曹操 938
关羽 779
张飞 348
吕布 299
赵云 286
孙权 263
司马懿 221
周瑜 217