实训日记7:爬取文章数据/团队日记7
实训日记7
本周实训,我们使用网络爬虫爬取我们需要的资讯数据。
资讯信息的爬取需要按照我们的数据库设计进行。字段如下图:

选择资讯网站
深刻地体会到了一个结构不清晰的网页对爬虫的劝退效果远各种超反爬虫技术。。。
根据本人的考察,国内所有资讯网站的网页结构都十分混乱,不同类型的资讯所在的网页结构差别巨大,这让我们很难泛化地写出爬虫。
即便如此,我们也要进行爬取,精挑细选我选择了环球网作为本次爬取的目标。
环球网国际板块的结构如下:
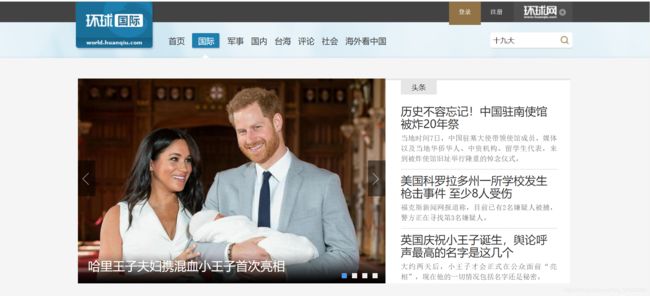

然而到了军事板块,网页就变成了这样:

完全不同的结构,怎么办呢,当然是寻找共同点。
根据我仔细观察,两者的超链接都存放在
接下来看文章内部网页:

需要爬取标题,时间,作者,内容。其中内容爬取富文本即可。这一步很简单,找到网页结构中存放数据的标签,记录下即可。
编写爬虫
编写爬虫爬取链接信息,代码如下:
import requests
import random
import urllib
from bs4 import BeautifulSoup
User_Agents =[
'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11',
'Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11']
types={'world':'国际','mil':'军事','china':'国内','taiwan':'台湾',
'opinion':'社评','society':'社会','oversea':'海外看中国'}
excludes=['http://www.huanqiu.com/','http://world.huanqiu.com/',
'http://mil.huanqiu.com/','http://china.huanqiu.com/',
'http://taiwan.huanqiu.com/','http://opinion.huanqiu.com/',
'http://society.huanqiu.com/','http://oversea.huanqiu.com/']
def geturl(url):
r=requests.get(url,headers={'User-Agent':random.choice(User_Agents)})
r.raise_for_status()
return r.text
subjects={}
for _type in types:
url='http://'+_type+'.huanqiu.com/'
soup=BeautifulSoup(geturl(url),'html.parser')
lils=soup.find_all('li')
for li in lils:
a=li.find('a')
try:
link=a.attrs['href']
except:
continue
temp=subjects.get(link,set())
temp.add(types[_type])
subjects[link]=temp
print(len(subjects))
fw=open('huanqiu.csv','w')
for sub in subjects:
if (sub in excludes) or ('photo' in sub):
continue
if len(subjects[sub])>4:
continue
link=sub
_type='&'.join(subjects[sub])
try:
fw.write(','.join([link,_type])+'\n')
except:
print(sub)
fw.close()
这样就能爬取所有的网页链接,并且根据网页的入口给文章打上标签。爬取的部分数据如下:

这里把类型过多的文章数据判定为噪声,去除。
接下来我们可以根据爬取的链接进入文章内部爬取,代码如下:
import requests
import random
import urllib
from bs4 import BeautifulSoup
import traceback
import json
User_Agents =[
'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11',
'Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11']
def geturl(url):
r=requests.get(url,headers={'User-Agent':random.choice(User_Agents)})
r.raise_for_status()
#print(r.encoding)
return r.text.encode('ISO-8859-1').decode('utf-8')
articles=[]
fo=open('huanqiu.csv','r')
for row in fo.readlines():
row=row.replace('\n','').split(',')
url=row[0]
_type=row[1]
try:
soup=BeautifulSoup(geturl(url),'html.parser')
except:
print(row,'get')
continue
try:
title=soup.find('h1').string
except:
print(row,'title')
continue
try:
content=soup.find('div',{'class':'la_con'})
content=str(content).encode("gbk", "ignore").decode('gbk')
#content=''.join(content.split())
#content.replace('\n','
')
#content.replace('\r','
')
except:
traceback.print_exc()
print(row,'content')
continue
try:
author=soup.find('meta',{'name':'author'}).attrs['content']
date=soup.find('meta',{'name':'publishdate'}).attrs['content']
except:
print(row,'author date')
continue
articles.append([title,author,date,_type,content])
print(len(articles))
pop_list=[]
fw=open('temp.csv','w',encoding='gbk')
for j in range(len(articles)):
try:
fw.write(','.join(articles[j])+'\n')
except:
pop_list.append(j)
j-=1
dic={}
rls=[3,262,50]
for i in range(len(articles)):
if i in rls:
continue
dic[i]=articles[i]
#ajson=json.dumps(dic)
with open('articles.json','w') as f:
json.dump(dic,f,ensure_ascii=False,sort_keys=True, indent=4)
print('done')
这里再次吐槽一下资讯网站爬取工作的难度。。。。文章内容里各种奇怪的编码字符,需要使用content=str(content).encode("gbk", "ignore").decode('gbk')来删除非gbk编码的字符。然而,这样做仍然会有些玄学字符能够保存下来(原因至今未知),不过数量很少,只在第3、50、262条数据内存在,可以单独剔除。
爬取部分结果如下(json):
这样就终于爬取了我们的资讯网站所需要的数据。。。。看我博客可能说的比较简单,实际上每一步都挺麻烦的,因为网页结构混乱,字符编码混乱。。。对数据还要去噪。。。总之我还是太菜了,唉
团队日记7
本周我们团队已经完成了模型的优化工作,继续在工程上进行推进。
- 注册登录
首先工程上我们实现了简单的注册登陆功能@AFXBR,这部分逻辑较为清晰,具体见链接内部,不再赘述。
- 推荐算法
本周还实现了基于情绪分析的推荐系统算法@Jemary,本系统采用的是协同过滤推荐算法,根据用户-文章评分矩阵查找当前用户的最近邻居,利用最近邻居的评分来预测当前用户对项目的预测值,将评分最高的N个项目推荐给用户。
其算法流程图如下图1所示:

基于用户的协同过滤推荐算法实现步骤为:
1).实时统计user对item的打分,从而生成user-item表
2).计算各个user之间的相似度,从而生成user-user的得分表,并进行排序;
3).对每一user的item集合排序;
4).针对预推荐的user,在user-user的得分表中选择与该用户最相似的N个用户,并在user-item表中选择这N个用户中已排序好的item集合中的topM;
5).此时的N*M个商品即为该用户推荐的商品集。
具体代码实现见@Jemary
- 远程服务端的配置
本周完成了配置服务器的工作@zekdot
服务器选择阿里云的云服务器,硬件配置是1核2G,操作系统是Ubuntu 16.04。配置过程分为如下几步。
- nginx的安装配置
具体操作见@zekdot。
完成nginx的安装配置可以让我们成功的访问到服务器上的静态资源了,但是访问后台的数据仍然能需要进一步的配置。 - 数据库的配置
具体操作见@zekdot。
这一步无需做过多解释,创建数据库以及表以保存业务流程中必要的数据。 - SpringBoot项目导出与启动
具体操作见@zekdot。
在pom.xml中添加打包方式为jar包;然后Build->Build Artifacts,选择jar包对应的选项,然后Build,将在target文件夹下出现对应的jar包;将其传送到服务器端,然后在8082端口启动;此时再访问页面可以看到已经可以成功加载数据了。
这样服务器的配置就完成了。
- 爬取文章数据
既然已经配置好了服务端,自然需要将资讯的数据导入服务端数据库。具体操作正如本片博客前半段所讲的,这里不再赘述。