联邦学习之安全聚合SMPC
联邦学习之安全聚合
- 联邦学习过程
- 1. 设备选择
- 2. 参数分发
- 3. 本地更新
- 4. 全局更新
- 5.收敛判停
- DSSGD
- FedAVG
- 安全聚合SMPC
- DH密钥交换
- 秘密分享secret share
- 引理1
- Shamir′s Secret Sharing with 2−out−of−3 (t = 2, n = 3)
- FedAVG场景
- Masking with One-Time Pads场景
- Masking with One-Time Pads问题
- SMPC: One-Time Pads with Recovery
- One-Time Pads with Recovery问题
- SMPC: Double-Masking
- 总结
- 引用
联邦学习过程
联邦学习以轮为单位,每轮包含设备选择、参数分发、本地更新和全局更新这4个步骤
1. 设备选择
服务器端选择该轮参与训练的设备,在设备选择阶段,有的设备可能处于离线状态,需要选择在线的设备,并且设备的电量、网络状况等符合一定的要求,被选中的设备参与该轮训练。

2. 参数分发
服务器将当前的模型参数分发给选中的设备。

3. 本地更新
本地设备下载到服务器发来的新的模型参数后,在此基础上,用本地的数据训练更新模型。
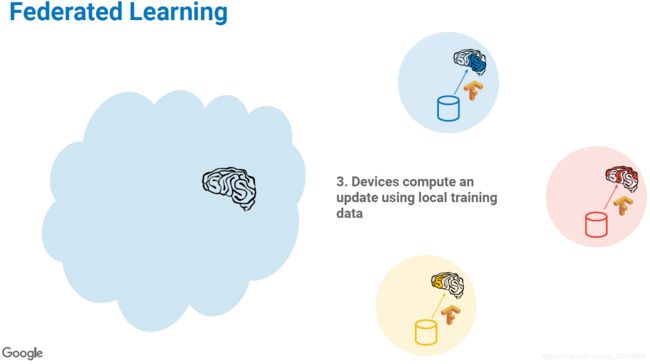
4. 全局更新
设备把本地更新了的模型发到服务器端,服务器按照一定规则进行聚合,对全局模型进行更新

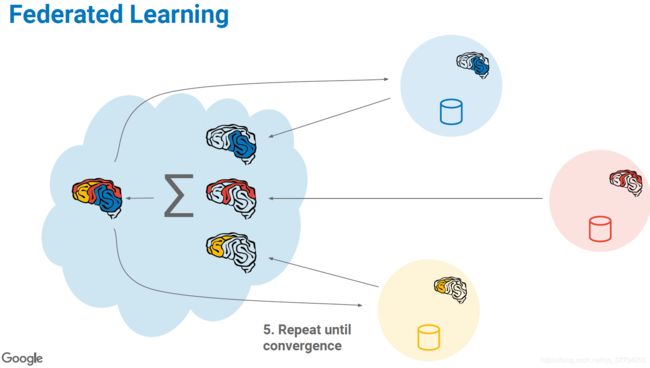
5.收敛判停
&emspl&emspl;在满足一定的收敛规则时,停止迭代
DSSGD
联邦学习的算法,源自分布式机器学习。2015年CCS中提出了分布选择随机梯度下降(DSSGD)算法,它是一个异步的协议,分为下载、训练和上传三个阶段。下载阶段,客户端可以选择一部分参数来进行更新本地模型;训练阶段,客户端在本地进行训练;上传阶段,客户端可以选择本地模型的一部分参数上传给服务器。每个客户端完成一次训练,马上将最新的参数选择一部分进行上传,服务器立即更新全局模型,然后进行广播。

FedAVG
之前的DSSGD存在的问题是通信量巨大,而且是异步的,不能用于很多用户的场景。2017年谷歌的Mcmahan等提出了FedAvg算法,是一个同步的协议,全局更新的每一轮可以有上百个客户端,进行加权平均,是目前主流的联邦学习算法。

安全聚合SMPC
在上面的算法中,所有的梯度都是以明文的形式给出的,然而,从梯度会泄露用户的个人信息,在最新的NeurIPS 2019中,《Deep Leakage from Gradients》一文指出,从梯度可以推断出原始的训练数据,包括图像和文本数据。谷歌的Bonawitz等人,提出了安全聚合SMPC加密方案,服务器只能看到聚合完成之后的梯度,不能知道每个用户的私有的真实梯度值。
DH密钥交换
在说安全聚合SMPC前,先说说一个常用的密钥交换协议——DH密钥交换。DH密钥交换的目的,是让想要通信的Alice、Bob双方,他们之间能够拥有一个私密的密钥,这个密钥只有A和B两个人知道。DH密钥交换包含如下步骤:
1. 首先,Alice和Bob商量好DH的参数,一个大数素数 P \mathcal{P} P,和 z p \mathbb{z}_p zp上的一个生成元 G G G( 1 < G < P 1
2. Alice和Bob都各自产生一个随机数,A和B是Alice和Bob的私钥
3. Alice和Bob分别计算 G A = G A ( m o d P ) G^A=G^A(mod \mathcal{\;P}) GA=GA(modP)和 G B = G B ( m o d P ) G^B=\mathcal{G}^B(mod \mathcal{\;P}) GB=GB(modP), G A G^A GA和 G B G^B GB是Alice和Bob的公钥。(由公钥推导出私钥是困难的)
4. Alice和Bob分别将公钥发送给对方
5. Alice收到Bob发来的他的公钥 G B G^B GB,计算出用来和Bob秘密通信的密钥 s A B = ( G B ) A ( m o d P ) s_{AB}=(G^B)^A(mod \mathcal{\;P)} sAB=(GB)A(modP);同理Bob收到alice发来的他的公钥 G A G^A GA,计算出用来和Bob秘密通信的密钥 s B A = ( G A ) B ( m o d P ) s_{BA}=(G^A)^B(mod \mathcal{\;P)} sBA=(GA)B(modP)。显然 s A B = s B A s_{AB}=s_{BA} sAB=sBA是相等的,他们在公开环境中,可以通过密钥建立私有通信通道,使用该密钥来加密消息。

秘密分享secret share
联邦学习中的安全聚合是基于安全多方计算的,安全多方计算是基于秘密分享的,秘密分享由1978年被Shamir提出(RSA中的S)。
引理1
L e m m a r 1 \mathcal{Lemmar \;1} Lemmar1:一个二维平面上, 给出任意 k k k个点 ( x 1 , y 1 ) , . . . , ( x k , y k ) (x_1,y_1), ... ,(x_k,y_k) (x1,y1),...,(xk,yk)的坐标,有且仅有一个 k − 1 k-1 k−1次的多项式 q ( x ) q(x) q(x),对于所有给定的 x i x_i xi,使得 q ( x i ) = y i q(x_i)=y_i q(xi)=yi。
- 给定 f ( x ) = a 0 + a 1 x f(x)=a_0+a_1x f(x)=a0+a1x,系数未知时,需要2个或者更多个 f ( x ) f(x) f(x)上的点才会透露出 f ( x ) f(x) f(x)是什么
- 给定 f ( x ) = a 0 + a 1 x + a 2 x 2 + . . . + a k − 1 x k − 1 f(x)=a_0+a_1x+a_2x^2+... +a_{k-1}x^{k-1} f(x)=a0+a1x+a2x2+...+ak−1xk−1,系数未知时,需要k个或者更多个 f ( x ) f(x) f(x)上的点才会透露出 f ( x ) f(x) f(x)是什么
Shamir′s Secret Sharing with 2−out−of−3 (t = 2, n = 3)
假设秘密 s = f ( 0 ) s=f(0) s=f(0), s s s被分享给 n = 3 n=3 n=3个用户,阈值 t = 2 t=2 t=2。
- 在这种情况下,一个用户想要知道秘密 s s s,必须至少有另一个用户的合作,达到阈值 t t t,才能获取秘密。只有一个用户,是获取不到秘密的,两点才能确定一条线,例如下图中单独第2个用户没法确定 s s s:

FedAVG场景
在原始的FedAVG中,用户 u u u发送更新值 y u y_u yu给服务器, y u y_u yu是其真实的模型更新值,服务器进行聚合,再按照聚合规则取平均:

Masking with One-Time Pads场景
用户u和v之间通过DH建立秘密通信通道,他们之间知道一个秘密随机数 s u v s_{uv} suv。用户1发送给服务器的更新值 y 1 y_1 y1是真实值 x 1 + 0 − ( s 12 + s 13 ) x_1+0-(s_{12}+s_{13}) x1+0−(s12+s13),这样服务器收到 y 1 y_1 y1时,并不知道 x 1 x_1 x1是多少。服务器对收到的所有值进行聚合以后,它们正负才会抵消,相当于真实值的聚合,等同于FedAVG。

Masking with One-Time Pads问题
上面的方案是存在问题的,假设用户2在上传 y 2 y_2 y2时掉线了,没有把 y 2 y_2 y2发送给服务器,那么这一轮全局更新中,服务端的聚合值 ∑ y i \sum{y_i} ∑yi是没有意义的。

SMPC: One-Time Pads with Recovery
因为上面的方案存在用户掉线后,聚合值失效的问题,所以考虑带恢复的方案。当用户2掉线时,在恢复阶段,它的值 s 12 s_{12} s12和 s 23 s_{23} s23用户1和用户3是知道的,服务器询问用户1和用户3,用户1和用户3进行报告。在恢复阶段结束后,服务器完成聚合。
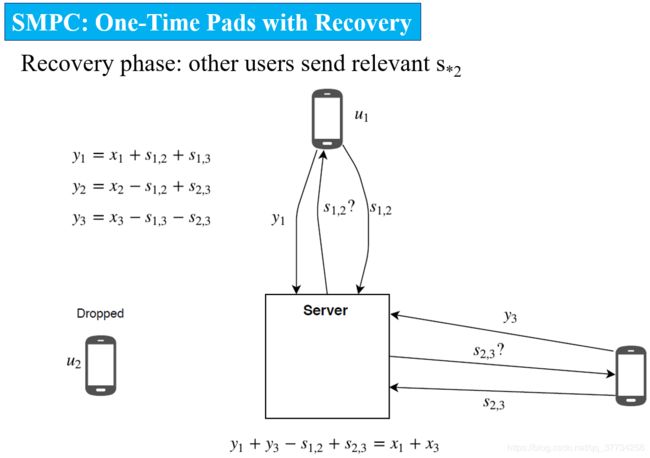
One-Time Pads with Recovery问题
- 上面的方案存在的第一个问题是,假如用户1或者用户3在上传 s 2 ∗ s_{2*} s2∗的时候掉线了,下一轮就需要继续对这个掉线进行处理,无穷无尽…【使用秘密分享secret share来解决这一问题,只要恢复阶段用户数 ∣ U ∣ ≥ t |U|\geq t ∣U∣≥t,就能成功恢复秘密 s u v s_{uv} suv。秘密分享还能保证只有足够多的用户存在时,才能获取秘密,使得刺探用户隐私变得困难。】
- 上面的方案存在的第二个问题,是加入用户2并不是真的掉线,而是网络延时较大,在服务器询问用户1和用户3获取 s 12 s_{12} s12和 s 23 s_{23} s23后,用户2发送给服务器的值 y 2 y_2 y2抵达。这时服务器就能够获取到用户2的隐私数据 x 2 = y 2 + s 12 − s 23 x_2=y_2+s_{12}-s_{23} x2=y2+s12−s23。

SMPC: Double-Masking
- 针对上面存在的问题,采用双掩码的策略,即使用两个随机数,为用户u引入另一个秘密随机数 b u b_u bu。所有的 b u b_u bu和 s ∗ ∗ s_{**} s∗∗均使用秘密分享的方式分享给其它用户。恢复阶段,至少有 t t t个用户才能恢复一个秘密。
- 在恢复阶段,诚实用户 v v v不会把关于某个用户 u u u的信息 b u b_u bu和 s u v s_{uv} suv同时说出去。对于掉线的用户u,他会说出 s u v s_{uv} suv的秘密,对于在线的用户u,则会说出 b u b_{u} bu的秘密。

总结
完整的SMPC的方案,可以在谷歌的论文中读到,可以参阅《Practical Secure Aggregation for Privacy-Preserving Machine Learning》。
引用
图大部分引用自论文:
[1] Jack Sullivan. “Secure Analytics: Federated Learning and Secure Aggregation”. Jan 2020. URL: https://inst.eecs.berkeley.edu/~cs261/fa18/scribe/10_15_revised.pdf
谷歌的方案:
[2] Bonawitz K, Ivanov V, Kreuter B, et al. Practical Secure Aggregation for Privacy-Preserving Machine Learning[C]. CCS, 2017: 1175-1191.
谷歌FL论文作者演讲PPT:
[3] Jakub Konečný. “Federated Learning-Privacy-Preserving Collaborative Machine Learning without Centralized Training Data”. Jan 2020. URL: http://jakubkonecny.com/files/2018-01_UW_Federated_Learning.pdf
[4] Jakub Konečný. “Federated Learning”. FL-IJCAI’19 ppts. Jan 2020. URL: http://fml2019.algorithmic-crowdsourcing.com/